
Третья и заключительная часть серии статей о языке lsFusion (ссылки на первую и вторую части)
В ней речь пойдет о физической модели: всем том, что не связано с функционалом системы, а связано с ее разработкой и оптимизацией производительности, когда данных становится слишком много.
Эта статья, как и предыдущие, не очень подходит для развлекательного чтения, но, в отличие от остальных, тут будет больше технических деталей и «горячих» тем (вроде типизации или метапрограммирования), плюс эта статья даст часть ответов на вопрос, как это все работает внутри.
В этой статье обойдемся без картинки (стека тут как такого нет), но зато сделаем оглавление, о чем просили в предыдущих статьях:
Оглавление
Идентификация элементов
Если проект состоит из нескольких небольших файлов, то проблем с именованием элементов обычно не возникает. Все имена на виду, и достаточно легко сделать так, чтобы они не пересекались. Если же проект, наоборот, состоит из множества модулей, разрабатываемых большим количеством различных людей, и абстракции в этих модулях из одной доменной области, конфликты имен становятся куда более вероятными. Для решения этих проблем в lsFusion есть два механизма:
- Пространства имен — разделение имени на полное и короткое, и возможность использования при обращении к элементу только короткого имени
- Явная типизация (если быть более точным, function overloading) — возможность называть свойства (и действия) одинаково, а затем при обращении к ним, в зависимости от классов аргументов, автоматически определять к какому именно свойству идет обращение
Пространства имен
Любой сложный проект обычно состоит из большого количества элементов, которые необходимо именовать. И, если доменные области пересекаются, очень часто возникает необходимость использовать одно и то же имя в различных контекстах. Например, у нас есть имя класса или формы Invoice (накладная), и мы хотим использовать это имя в различных функциональных блоках, например: Закупка (Purchase), Продажа (Sale), Возврат закупки (PurchaseReturn), Возврат продажи (SaleReturn). Понятно, что можно называть классы / формы PurchaseInvoice, SaleInvoice и так далее. Но, во-первых, такие имена сами по себе будут слишком громоздкими. А во-вторых, в одном функциональном блоке обращения, как правило, идут к элементам этого же функционального блока, а значит, при разработке, к примеру, функционального блока Закупки (Purchase) от постоянного повторения слова Purchase будет просто рябить в глазах. Чтобы этого не происходило, в платформе существует такое понятие как пространство имен. Работает это следующим образом:
- каждый элемент в платформе создается в некотором пространстве имен
- если в процессе создания элемента идет обращение к другим элементам, элементы созданные в этом же пространстве имен имеют приоритет
MODULE PurchaseInvoice; |
MODULE SaleInvoice; |
MODULE PurchaseShipment; |
Явная типизация
Пространства имен являются важным, но не единственным способом сделать код короче и читабельнее. Помимо них при поиске свойств (и действий) также существует возможность учитывать классы аргументов, передаваемых им на вход. Так, например:
sum = DATA NUMERIC[10,2] (OrderDetail); |
Также, стоит отметить, что явная типизация в lsFusion в общем случае не обязательна. Классы параметров можно не указывать, и если платформе хватит информации, чтобы найти нужное свойство, она сделает это. С другой стороны, в реально сложных проектах классы параметров все же рекомендуется задавать явно, не только с точки зрения краткости кода, но и с точки зрения различных дополнительных возможностей, таких как: ранняя диагностика ошибок, умное автодополнение со стороны IDE и так далее. У нас был большой опыт работы как с неявной типизацией (первые 5 лет), так и с явной (оставшееся время), и надо сказать, что времена неявной типизации сейчас вспоминают с содроганием (хотя может просто «мы не умели ее готовить»).
Модульность
Модульность является одним из самых важных свойств системы, позволяющим обеспечить ее расширяемость, повторное использование кода, а также эффективное взаимодействие команды разработчиков.
В lsFusion модульность обеспечивается следующими двумя механизмами:
- Расширения — возможность расширять (изменять) элементы системы после их создания.
- Модули — возможность группировать некоторый функционал вместе для его дальнейшего повторного использования.
Расширения
lsFusion поддерживает возможность расширения классов и форм, а также свойств и действий через механизм полиморфизма, описанный в первой статье.
sum = DATA NUMERIC[10,2] (OrderDetail); |
Модули
Модуль — это некоторая функционально законченная часть проекта. В текущей версии lsFusion модуль — это отдельный файл, состоящий из заголовка и тела модуля. Заголовок модуля, в свою очередь, состоит из: имени модуля, а также, при необходимости, списка используемых модулей и имени пространства имен этого модуля. Тело модуля состоит из объявлений и / или расширений элементов системы: свойств, действий, ограничений, форм, метакодов и так далее.
Обычно модули для объявления своих / расширения существующих элементов используют элементы из других модулей. Соответственно, если модуль B использует элементы из модуля A, то в модуле B необходимо указать, что он зависит от A.
На основании своих зависимостей все модули в проекте выстраиваются в некотором порядке, в котором происходит их инициализация (этот порядок играет важную роль при использовании вышеупомянутого механизма расширений). Гарантируется, что если модуль B зависит от модуля A, то инициализация модуля A произойдет раньше, чем инициализация модуля B. Циклические зависимости между модулями в проекте не допускаются.
Зависимости между модулями являются транзитивными. То есть, если модуль C зависит от модуля B, а модуль B зависит от модуля A, то считается, что и модуль С также зависит от модуля A.
Любой модуль всегда автоматически зависит от системного модуля System, вне зависимости от того, указано это явно или нет.
MODULE EmployeeExample; // Задаем имя модуля |
Метапрограммирование
Метапрограммирование — это вид программирования, связанный с написанием программного кода, который в качестве результата порождает другой программный код. В lsFusion для метапрограммирования используются так называемые метакоды.
Метакод состоит из:
- имени метакода
- параметров метакода
- тела метакода — блока кода, состоящего из объявлений и / или расширений элементов системы ( свойств, действий, событий, других метакодов и т.д.)
Соответственно, перед тем как начать основную обработку кода, платформа выполняет его предобработку — заменяет все использования метакодов на тела этих метакодов. При этом все параметры метакода, использованные в идентификаторах / строковых литералах, заменяются на переданные этому метакоду аргументы:
Объявление:
META addActions(formName) |
@addActions(documentForm); |
EXTEND FORM documentForm |
Объявление:
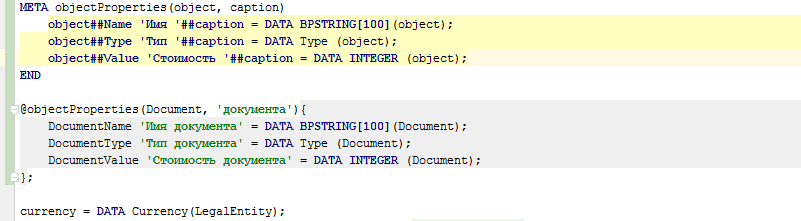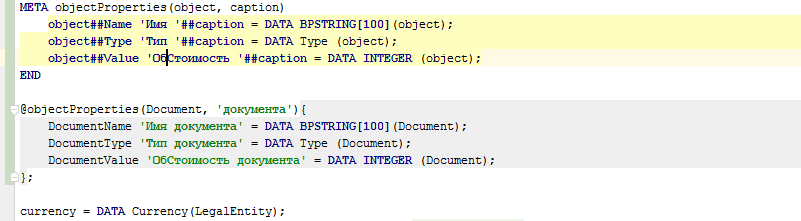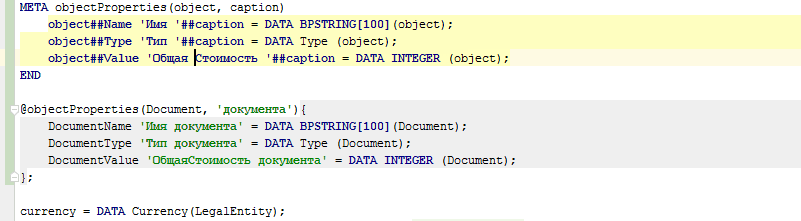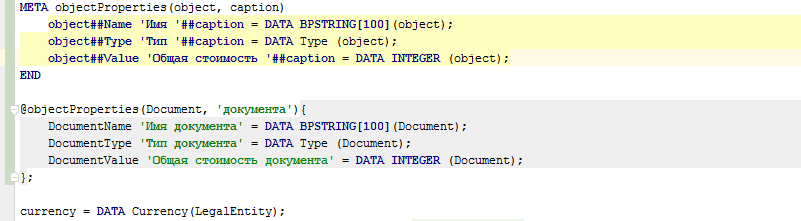
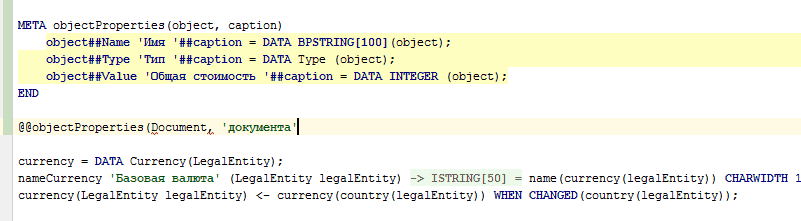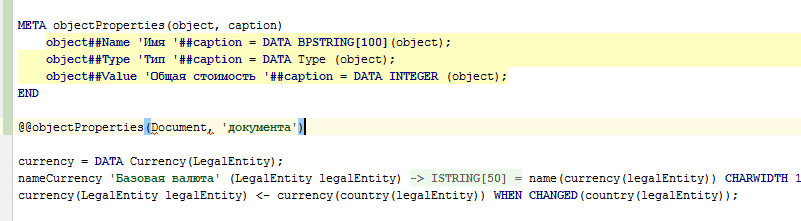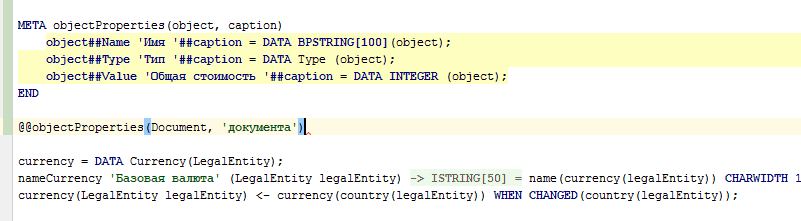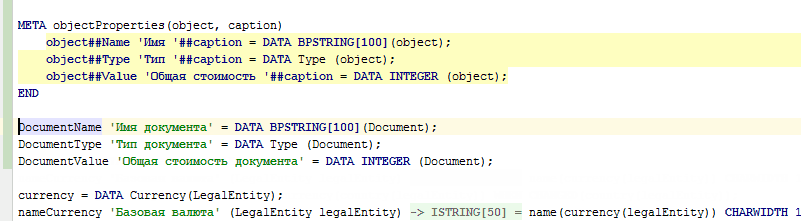
META objectProperties(object, caption) |
@objectProperties(document, 'документа'); |
DocumentName 'Имя документа' = DATA BPSTRING[100](Document); |
В lsFusion метакоды решают задачи, схожие с generics в Java (передача классов в качестве параметров) и lambda в ФП (передачи функций в качестве параметров), правда, делают это не очень красиво. Но, с другой стороны, они это делают в существенно более общем случае (то есть, например, с возможностью объединения идентификаторов, использования в любых синтаксических конструкциях — формах, дизайнах, навигаторе и т.п.)
Отметим, что «разворачивание» метакодов поддерживается не только в самой платформе, но и в IDE. Так, в IDE есть специальный режим Enable meta, который генерирует результирующий код прямо в исходниках и тем самым позволяет участвовать этому сгенерированному коду в поиске использований, автодополнении и т.п. При этом, если тело метакода изменяется, IDE автоматически обновляет все использования этого метакода.
Также метакоды можно использовать не только для автоматической, но и для ручной кодогенерации (в качестве шаблонов). Для этого достаточно вместо одной @ написать @@ — и сразу после того, как строка использования метакода будет полностью введена (вплоть до точки с запятой), IDE заменит это использование метакода на сгенерированный по этому метакоду код:
Интеграция
Интеграция включает в себя все то, что связано с взаимодействием системы lsFusion с другими системами. С точки зрения направления этого взаимодействия интеграцию можно разделить на:
- Обращение к lsFusion системе из другой системы.
- Обращение из lsFusion системы к другой системе.
С точки зрения физической модели интеграцию можно разделить на:
- Взаимодействие с системами, выполняющимися в «той же среде», что и lsFusion система (то есть, в виртуальной Java машине (JVM) lsFusion-сервера и/или использующими тот же SQL-сервер, что и lsFusion система).
- Взаимодействие с удаленными системами по сетевым протоколам.
Соответственно, первые системы будем называть внутренними, вторые — внешними.
Таким образом в платформе существует четыре различных вида интеграции:
- Обращение к внешней системе
- Обращение из внешней системы
- Обращение к внутренней системе
- Обращение из внутренней системы
Обращение к внешней системе
Обращение к внешним системам в lsFusion в большинстве случаев реализуется при помощи специального оператора EXTERNAL. Этот оператор выполняет заданный код на языке / в парадигме заданной внешней системы. Кроме того, этот оператор позволяет передавать объекты примитивных типов в качестве параметров такого обращения, а также записывать результаты обращения в заданные свойства (без параметров).
На данный момент в платформе поддерживаются следующие типы взаимодействий / внешних систем:
HTTP — выполнение http-запроса Web-сервера.
Для этого типа взаимодействия необходимо задать строку запроса (URL), которая одновременно определяет как адрес сервера, так и непосредственно запрос, который необходимо выполнить. Параметры могут передаваться как в строке запроса (для обращения к параметру используется спецсимвол $ и номер этого параметра, начиная с 1), так и в его теле (BODY). Предполагается, что в BODY передаются все параметры, не использованные в строке запроса. Если в BODY больше одного параметра, тип контента BODY при передаче устанавливается равным multipart/mixed, а параметры передаются как составные части этого BODY.
При обработке параметров файловых классов (FILE, PDFFILE и т.п.) в BODY, тип контента параметра определяется в зависимости от расширения файла (в соответствии со следующей таблицей). Если расширение файла отсутствует в этой таблице, тип контента устанавливается равным application/<расширение файла>.
При необходимости, при помощи специальной опции (HEADERS) можно задать заголовки выполняемого запроса. Для этого нужно указать свойство с ровно одним параметром строкового класса, в котором будет храниться название заголовка, и значением строкового класса, в котором будет храниться значение этого заголовка.
Результат http-запроса обрабатывается аналогично его параметрам, только в обратную сторону: к примеру, если тип контента результата или присутствует в следующей таблице, или равен application/*, то считается, что полученный результат — это файл и должен записываться в свойство со значением FILE. Заголовки результата http-запроса обрабатываются по аналогии с заголовками самого этого запроса (с той лишь разницей, что опция называется HEADERSTO, а не HEADERS).
EXTERNAL HTTP GET 'https://www.cs.cmu.edu/~chuck/lennapg/len_std.jpg' TO exportFile; |
Для этого типа взаимодействия задается строка подключения и SQL-команда(ы), которую необходимо выполнить. Параметры могут передаваться как в строке подключения, так и в SQL-команде. Для обращения к параметру используется спецсимвол $ и номер этого параметра (начиная с 1).
Параметры файловых классов (FILE, PDFFILE и т.п.) можно использовать только в SQL-команде. При этом, если какой-либо из параметров при выполнении является файлом формата TABLE (TABLEFILE или FILE с расширением table), то такой параметр считается таблицей и в этом случае:
- перед выполнением SQL-команды значение каждого такого параметра загружается на сервер во временную таблицу
- при подстановке параметров подставляется не само значение параметра, а имя созданной временной таблицы
Результатами выполнения являются: для DML-запросов — числа, равные количеству обработанных записей, для SELECT-запросов — файлы формата TABLE (FILE с расширением table), содержащие результаты этих запросов. При этом порядок этих результатов совпадает с порядком выполнения соответствующих запросов в SQL-команде.
externalSQL () { |
Для этого типа взаимодействия задается строка подключения к lsFusion-серверу (или его веб-серверу, при наличии такового), действие, которые необходимо выполнить, а также список свойств (без параметров), в значения которых будут записаны результаты обращения. Передаваемые параметры должны по количеству и по классам совпадать с параметрами выполняемого действия.
Способ задания действия в этом типе взаимодействия полностью соответствует способу задания действия при обращении из внешней системы (про этот тип обращения в следующем разделе).
externalLSF() { |
В том случае, если нужно обратиться к системе по протоколу, отличному от вышеперечисленных, это всегда можно сделать, создав действие на Java и реализовав это обращение там (но об этом чуть позже в разделе «Обращение к внутренним системам»)
Обращение из внешней системы
Платформа предоставляет возможность внешним системам обращаться к разработанной на lsFusion системе с использованием сетевого протокола HTTP. Интерфейсом такого взаимодействия является вызов некоторого действия с заданными параметрами и, при необходимости, возврат значений некоторых свойств (без параметров) в качестве результатов. Предполагается, что все объекты параметров и результатов являются объектами примитивных типов.
Вызываемое действие может задаваться одним из трех способов:
- /exec?action=<имя действия> — задается имя вызываемого действия.
- /eval?script=<код> — задается код на языке lsFusion. Предполагается, что в этом коде присутствует объявление действия с именем run, именно это действие и будет вызвано. Если параметр script не задан, то предполагается, что код передается первым параметром BODY.
- /eval/action?script=<код действия> — задается код действия на языке lsFusion. Для обращения к параметрам можно использовать спецсимвол $ и номер параметра (начиная с 1).
Во втором и третьем случае, если параметр script не задан, то предполагается, что код передается первым параметром BODY.
Обработка параметров и результатов симметрична обращению к внешним системам по протоколу HTTP (с той лишь разницей, что параметры при этом обрабатываются как результаты, и, наоборот, результаты обрабатываются как параметры), поэтому особо повторяться не будем.
Например, если у нас есть действие:
importOrder(INTEGER no, DATE date, FILE detail) { |
- URL — хттп://адрес_сервера/exec?action=importOrder&p=123&p=2019-01-01
- BODY — json-файл со строками запроса
Пример обращения на Python
import json
import requests
from requests_toolbelt.multipart import decoder
lsfCode = ("run(INTEGER no, DATE date, FILE detail) {\n"
" NEW o = FOrder {\n"
" no(o) <- no;\n"
" date(o) <- date;\n"
" LOCAL detailId = INTEGER (INTEGER);\n"
" LOCAL detailQuantity = INTEGER (INTEGER);\n"
" IMPORT JSON FROM detail TO detailId, detailQuantity;\n"
" FOR imported(INTEGER i) DO {\n"
" NEW od = FOrderDetail {\n"
" id(od) <- detailId(i);\n"
" quantity(od) <- detailQuantity(i);\n"
" price(od) <- 5;\n"
" order(od) <- o;\n"
" }\n"
" }\n"
" APPLY;\n"
" EXPORT JSON FROM price = price(FOrderDetail od), id = id(od) WHERE order(od) == o;\n"
" EXPORT FROM orderPrice(o), exportFile();\n"
" }\n"
"}")
order_no = 354
order_date = '10.10.2017'
order_details = [dict(id=1, quantity=10),
dict(id=2, quantity=15),
dict(id=5, quantity=4),
dict(id=10, quantity=18),
dict(id=11, quantity=1),
dict(id=12, quantity=3)]
order_json = json.dumps(order_details)
url = 'http://localhost:7651/eval'
payload = {'script': lsfCode, 'no': str(order_no), 'date': order_date,
'detail': ('order.json', order_json, 'text/json')}
response = requests.post(url, files=payload)
multipart_data = decoder.MultipartDecoder.from_response(response)
sum_part, json_part = multipart_data.parts
sum = int(sum_part.text)
data = json.loads(json_part.text)
##############################################################
print(sum)
for item in data:
print('{0:3}: price {1}'.format(int(item['id']), int(item['price'])))
##############################################################
# 205
# 4: price 5
# 18: price 5
# 3: price 5
# 1: price 5
# 10: price 5
# 15: price 5
Обращение к внутренней системе
Существует два типа внутреннего взаимодействия:
Java-взаимодействие
Этот тип взаимодействия позволяет вызвать код на языке Java внутри JVM lsFusion-сервера. Для этого необходимо:
- обеспечить, чтобы скомпилированный Java-класс был доступен в classpath сервера приложений. Также необходимо, чтобы этот класс наследовал lsfusion.server.physics.dev.integration.internal.to.InternalAction.
Пример Java-классаimport lsfusion.server.data.sql.exception.SQLHandledException; import lsfusion.server.language.ScriptingErrorLog; import lsfusion.server.language.ScriptingLogicsModule; import lsfusion.server.logics.action.controller.context.ExecutionContext; import lsfusion.server.logics.classes.ValueClass; import lsfusion.server.logics.property.classes.ClassPropertyInterface; import lsfusion.server.physics.dev.integration.internal.to.InternalAction; import java.math.BigInteger; import java.sql.SQLException; public class CalculateGCD extends InternalAction { public CalculateGCD(ScriptingLogicsModule LM, ValueClass... classes) { super(LM, classes); } @Override protected void executeInternal(ExecutionContext<ClassPropertyInterface> context) throws SQLException, SQLHandledException { BigInteger b1 = BigInteger.valueOf((Integer)getParam(0, context)); BigInteger b2 = BigInteger.valueOf((Integer)getParam(1, context)); BigInteger gcd = b1.gcd(b2); try { findProperty("gcd[]").change(gcd.intValue(), context); } catch (ScriptingErrorLog.SemanticErrorException ignored) { } } } - зарегистрировать действие при помощи специального оператора внутреннего вызова (INTERNAL)
calculateGCD 'Рассчитать НОД' INTERNAL 'CalculateGCD' (INTEGER, INTEGER);
- зарегистрированное действие, как и любое другое, можно вызывать при помощи оператора вызова. Выполняться при этом будет метод executeInternal(lsfusion.server.logics.action.controller.context.ExecutionContext context) заданного Java-класса.
// на форме
FORM gcd 'НОД'
OBJECTS (a = INTEGER, b = INTEGER) PANEL
PROPERTIES 'A' = VALUE(a), 'B' = VALUE(b)
PROPERTIES gcd(), calculateGCD(a, b)
;
// в другом действии
run() {
calculateGCD(100, 200);
}
Этот тип взаимодействия позволяет обращаться к объектам / синтаксическим конструкциям SQL-сервера, используемого разрабатываемой lsFusion-системой. Для реализации такого типа взаимодействия в платформе используется специальный оператор — FORMULA. Этот оператор позволяет создавать свойство, вычисляющее некоторую формулу на языке SQL. Формула задается в виде строки, внутри которой для обращения к параметру используется спецсимвол $ и номер этого параметра (начиная с 1). Соответственно, количество параметров у полученного свойства будет равно максимальному из номеров использованных параметров.
round(number, digits) = FORMULA 'round(CAST(($1) as numeric),$2)'; // свойство с двумя параметрами: округляемым числом и количеством знаков после запятой |
Обращение из внутренней системы
Тут все симметрично обращению к внутренней системе. Есть два типа взаимодействия:
Java-взаимодействие
В рамках такого типа взаимодействия внутренняя система может обращаться непосредственно к Java-элементам lsFusion-системы (как к обычным Java объектам). Таким образом, можно выполнять все те же операции как и с использованием сетевых протоколов, но при этом избежать существенного оверхеда такого взаимодействия (например, на сериализацию параметров / десериализацию результата и т.п). Кроме того, такой способ общения гораздо удобнее и эффективнее, если взаимодействие очень тесное (то есть в процессе выполнения одной операции требуется постоянное обращение в обе стороны — от lsFusion системы к другой системе и обратно) и / или требует доступа к специфическим узлам платформы.
Для того, чтобы обращаться к Java-элементам lsFusion-системы напрямую, нужно предварительно получить ссылку на некоторый объект, у которого будут интерфейсы по поиску этих Java элементов. Как правило это делается одним из двух способов:
- Если первоначально обращение идет из lsFusion системы (через описанный выше механизм), то в качестве «объекта поиска» можно использовать объект действия, «через которое» идет это обращение (класс этого действия должен наследоваться от lsfusion.server.physics.dev.integration.internal.to.InternalAction, у которого, в свою очередь, есть все необходимые интерфейсы).
- Если объект, из метода которого необходимо обратиться к lsFusion системе, является Spring bean'ом, то ссылку на объект бизнес-логики можно получить, используя dependency injection (соответственно bean называется businessLogics).
Пример Java-класса
import lsfusion.server.data.sql.exception.SQLHandledException;
import lsfusion.server.data.value.DataObject;
import lsfusion.server.language.ScriptingErrorLog;
import lsfusion.server.language.ScriptingLogicsModule;
import lsfusion.server.logics.action.controller.context.ExecutionContext;
import lsfusion.server.logics.classes.ValueClass;
import lsfusion.server.logics.property.classes.ClassPropertyInterface;
import lsfusion.server.physics.dev.integration.internal.to.InternalAction;
import java.math.BigInteger;
import java.sql.SQLException;
public class CalculateGCDObject extends InternalAction {
public CalculateGCDObject(ScriptingLogicsModule LM, ValueClass... classes) {
super(LM, classes);
}
@Override
protected void executeInternal(ExecutionContext<ClassPropertyInterface> context) throws SQLException, SQLHandledException {
try {
DataObject calculation = (DataObject)getParamValue(0, context);
BigInteger a = BigInteger.valueOf((Integer)findProperty("a").read(context, calculation));
BigInteger b = BigInteger.valueOf((Integer)findProperty("b").read(context, calculation));
BigInteger gcd = a.gcd(b);
findProperty("gcd[Calculation]").change(gcd.intValue(), context, calculation);
} catch (ScriptingErrorLog.SemanticErrorException ignored) {
}
}
}
SQL-взаимодействие
Системы имеющие доступ к SQL-серверу lsFusion-системы (одной из таких систем, к примеру, является сам SQL-сервер), могут обращаться непосредственно к таблицам и полям, созданным lsFusion-системой, средствами SQL-сервера. При этом необходимо учитывать, что, если чтение данных относительно безопасно (за исключением возможного удаления / изменения таблиц и их полей), то при записи данных не будут вызваны никакие события (и, соответственно, все элементы их использующие — ограничения, агрегации и т.п.), а также не будут пересчитаны никакие материализации. Поэтому записывать данные напрямую в таблицы lsFusion-системы крайне не рекомендуется, а если это все же необходимо, важно учесть все вышеупомянутые особенности.
Отметим, что такое прямое взаимодействие (но только на чтение) особенно удобно для интеграции с различными OLAP-системами, где весь процесс должен происходить с минимальным оверхедом.
Миграция
На практике часто возникают ситуации когда по различным причинам необходимо изменять имена уже существующих элементов системы. Если элемент, который необходимо переименовать, не связан ни с какими первичными данными, это можно сделать без каких-либо лишних телодвижений. Но если этим элементом является первичное свойство или класс, то такое «тихое» переименование приведет к тому, что данные этого первичного свойства или класса просто-напросто исчезнут. Чтобы этого не произошло, разработчик может создать специальный миграционный файл migration.script, поместить его в classpath сервера, и в нем указать, как старые имена элементов соответствуют новым именам. Работает это все следующим образом:
Миграционный состоит из блоков, которые описывают изменения, произведенные в указанной версии структуры базы данных. При старте сервера применяются все изменения из миграционного файла, которые имеют версию выше, чем версия, хранящаяся в базе данных. Изменения применяются в соответствии с версией, от меньшей версии к большей. Если изменение структуры БД происходит успешно, то максимальная версия из всех примененных блоков записывается в базу данных в качестве текущей. Синтаксис описания каждого блока выглядит следующим образом:
V<номер версии> {
изменение1
...
изменениеN
}
Изменения, в свою очередь, бывают следующих типов:
DATA PROPERTY oldNS.oldName[class1,...,classN] -> newNS.newName[class1,...,classN] |
- для миграции метаданных (политики безопасности, настроек таблиц и т.п)
- для оптимизации миграции пользовательских данных (чтобы не перерасчитывать агрегации и не переносить данные между таблицами лишний раз).
Соответственно, если миграция метаданных не нужна или данных не очень много, такие изменения в миграционном скрипте можно не указывать.
Пример миграции
V0.3.1 { |
Стоит отметить, что обычно большинство работ по генерации миграционных скриптов выполняется при помощи IDE. Так, при переименовании большинства элементов, можно указать специальную галочку Change migration file (включена по умолчанию), и IDE сгенерирует все нужные скрипты автоматически.
Интернационализация
На практике иногда возникает ситуация, когда необходимо иметь возможность использовать одно приложение на разных языках. Эта задача обычно сводится к локализации всех строковых данных, которые видит пользователь, а именно: текстовых сообщений, заголовков свойств, действий, форм и т.д. Все эти данные в lsFusion задаются при помощи строковых литералов (строк в одиночных кавычках, например 'abc'), соответственно, их локализация осуществляется следующим образом:
- в строке вместо текста, который необходимо локализовать, указывается идентификатор строковых данных, заключенный в фигурные скобки (например, '{button.cancel}').
- при передаче этой строки клиенту на сервере осуществляется поиск всех встречаемых в строке идентификаторов, затем осуществляется поиск каждого из них во всех ResourceBundle файлах проекта в нужной локали (то есть локали клиента), и при нахождении нужного варианта идентификатор в скобках заменяется на соответствующий текст.
script '{scheduler.script.scheduled.task.detail}' = DATA TEXT (ScheduledTaskDetail); |
scheduler.script.scheduled.task.detail=Script
scheduler.constraint.script.and.action=In the scheduler task property and script cannot be selected at the same time
scheduler.form.scheduled.task=Tasks
ServerResourceBundle_ru.properties
scheduler.script.scheduled.task.detail=Скрипт
scheduler.constraint.script.and.action=В задании планировщика не могут быть одновременно выбраны свойство и скрипт
scheduler.form.scheduled.task=Задания
Оптимизация производительности проектов с большим количеством данных
Если система небольшая и данных в ней относительно немного, как правило, она работает достаточно эффективно без каких-либо дополнительных оптимизаций. Если же логика становится достаточно сложной, а количество данных значительно возрастает, иногда имеет смысл подсказать платформе, как лучше хранить и обрабатывать все эти данные.
В платформе есть два основных механизма работы с данными: свойства и действия. Первый отвечает за хранение и вычисление данных, второй — за перевод системы из одного состояния в другое. И если работа действий поддается оптимизации достаточно ограниченно (в том числе из-за эффекта последействия), то для свойств существует целый набор возможностей, которые позволяют как уменьшить время отклика конкретных операций, так и увеличить общую производительность системы:
- Материализации. Если чтений свойства достаточно много (значительно больше, чем изменений), можно существенно улучшить производительность операций, использующих такое свойство, материализовав его.
- Индексы. Если свойство часто участвует в вычислениях других свойств, как правило, имеет смысл построить индекс по этому свойству.
- Таблицы. Если для одного и того же набора объектов часто читаются / изменяются одновременно одни и те же свойства, хранить каждое такое свойство отдельно может быть достаточно неэффективно. Поэтому в платформе хранение свойств можно «группировать» в таблицы.
Материализации
Практически любое агрегированное свойств в платформе можно материализовать. В этом случае свойство будет храниться в базе данных постоянно и автоматически обновляться при изменении данных, от которых это свойство зависит. При этом при чтении значений такого материализованного свойства, эти значения будут читаться непосредственно из базы, как если бы свойство было первичным (а не вычисляться каждый раз). Соответственно, все первичные свойства являются материализованными по определению.
Свойство можно материализовать тогда и только тогда, когда для него существует конечное число наборов объектов, для которых значение этого свойства не NULL
Вообще, тема материализаций достаточно обстоятельно разбиралась в недавней статье про баланс записи и чтения в базах данных, поэтому останавливаться на ней подробно здесь, на мой взгляд, особого смысла не имеет.
Индексы
Построение индекса по свойству позволяет хранить в базе все значения такого свойства в упорядоченном виде. Соответственно, индекс обновляется при каждом изменении значения индексированного свойства. Благодаря индексу, если, например, идет фильтрация по индексированному свойству, можно очень быстро найти нужные объекты, а не просматривать все существующие объекты в системе.
Индексировать можно только материализованные свойства (из раздела выше).
Индекс также может быть построен сразу по нескольким свойствам (это эффективно, если, к примеру, фильтрация идет сразу по этим нескольким свойствам). Кроме того, в такой составной индекс можно включать параметры свойств. Если указанные свойства хранятся в разных таблицах, то при попытке построения индекса будет выдана соответствующая ошибка.
INDEX customer(Order o); |
Таблицы
Для хранения и вычисления значений свойств платформа lsFusion использует реляционную базу данных. Все первичные свойства, а также все агрегированные свойства, которые помечены как материализованные, хранятся в полях таблиц базы данных. Для каждой таблицы существует набор ключевых полей с именами key0, key1, ..., keyN, в которых хранятся значения объектов (например, для пользовательских классов — идентификаторы этих объектов). Во всех остальных полях хранятся значения свойств таким образом, что в соответствующем поле каждого ряда находится значение свойства для объектов из ключевых полей.
При создании таблицы необходимо указать список классов объектов, которые будут ключами в этой таблице.
TABLE book (Book); |
Имена таблиц и полей, в которых хранятся свойства, в СУБД формируются в соответствии с заданной политикой именования. На текущий момент в платформе поддерживается три стандартных политики именования.
| Политика | Имя таблицы | Имя поля |
|---|---|---|
| Полное с сигнатурой (по умолчанию) | ПространствоИмен_ИмяТаблицы | ПространствоИмен_ИмяСвойства_ИмяКласса1 _ИмяКласса2..._ИмяКлассаN |
| Полное без сигнатуры | ПространствоИмен_ИмяТаблицы | ПространствоИмен_ИмяСвойства |
| Краткое | ИмяТаблицы | ИмяСвойства |
При выборе политики именования важно иметь в виду, что использование слишком краткой политики именования свойств, если количество материализованных свойств достаточно большое, может значительно усложнить именование этих свойств (так, чтобы оно было уникальным), или, соответственно, приводить к слишком частой необходимости явно именовать поля, в которых будут храниться эти свойства.
Заключение
Как говорилось в одном известном мультике: «мы строили, строили и наконец построили». Может, конечно, немного поверхностно, но разобраться с основными возможностями языка / платформы lsFusion по этим трем статьям, я думаю, можно. Пришла пора переходить к самой интересной части — сравнению с другими технологиями.
Как показал опыт и формат хабра, делать это эффективнее играя не на своем, а на чужом поле. То есть идти не от возможностей, а от проблем и, соответственно, рассказывать не о своих преимуществах, а о недостатках альтернативных технологий, причем в их же терминологии. Такой подход обычно гораздо лучше воспринимается на консервативных рынках, а именно таким рынком, на мой взгляд, и является рынок разработки информационных систем, во всяком случае, на постсоветском пространстве.
Так что совсем скоро появится еще несколько статей в стиле: «Почему не ...?», и, я уверен, они будут значительно более интересными, чем эти весьма занудные tutorial'ы.
