Краткий пересказ: мы сделали программу, определяющую надежность новостей с точностью 95% (на валидационной выборке) при помощи машинного обучения и технологий обработки естественного языка. Скачать ее можно здесь. В условиях реальной действительности точность может оказаться несколько ниже, особенно по прошествии некоторого времени, так как каноны написания новостных статей будут меняться.
Глядя, как бурно развиваются машинное обучение и обработка естественного языка, я подумал: чем черт не шутит, может быть, мне удастся создать модель, которая выявляла бы новостной контент с недостоверной информацией, и тем самым хоть чуть-чуть сгладить катастрофические последствия, которые приносит сейчас распространение фейковых новостей.

С этим можно поспорить, но, на мой взгляд, самый сложный этап в создании собственной модели машинного обучения — сбор материалов для обучения. Когда я обучал модель для распознавания лиц, мне пришлось несколько дней собирать фотографии каждого из игроков лиги НБА в сезоне 2017/2018. Теперь же я и не подозревал, что мне придется провести погруженным в этот процесс несколько мучительных месяцев и столкнуться с очень неприятными и жуткими вещами, которые люди пытаются выдать за настоящие новости и надежную информацию.
Первое же препятствия стало для меня неожиданностью. Изучив сайты с фейковыми новостями повнимательнее, я быстро обнаружил, что существует множество различных категорий, к которым могут относиться ложные сведения. Есть статьи с откровенным враньем, есть такие, которые приводят реальные факты, но затем неверно их интерпретируют, есть псевдонаучные тексты, есть просто эссе с мнениями автора, замаскированные под новостные заметки, есть сатира, есть компиляторские статьи, состоящие в основном из чужих твитов и цитат. Я немного погуглил и нашел разные классификации, в которых люди пытались разбить такие сайты на группы — «сатира», «фейковые», «вводящие в заблуждение» и так далее.
Я решил, что можно с тем же успехом взять их за основу, и пошел по списку приведенных сайтов, чтобы набрать оттуда примеров. Практически сразу возникла проблема: некоторые из сайтов, помеченные как «фейковые» или «вводящие в заблуждение» на самом деле содержали и достоверные статьи. Я понял, что собирать с них данные без проверки на тривиальные ошибки не удастся.
Тогда же я стал задаваться вопросом: стоит ли учитывать сатиру и субъективные тексты и если да, то куда их относить — к достоверным материалам, фейку или в отдельную категорию?
Прокорпев неделю над сайтами с фейковыми новостями, я задумался, не слишком ли усложняю проблему. Возможно, стоит просто взять какие-то из уже существующих обучающих моделей для анализа тональности и попытаться выявить закономерности. Я решил сделать простенький инструмент, который будет собирать данные: заголовки, описания, информацию об авторах и сам текст, и отсылать их модели для анализа тональности. Для последнего я использовал Textbox — это было удобно, потому что я могу запускать его локально, на своей машине, и быстро получать результаты.
Textbox выдает оценку тональности, которую можно интерпретировать как позитивную или негативную. Затем я сварганил алгоритм, который приписывал тональности каждой разновидности выгруженных данных (заголовок, авторы, текст и так далее) определенную степень значимости, и собрал всю систему воедино, чтобы посмотреть, удастся ли мне получить общую оценку новостной статьи.
Сначала все вроде бы шло неплохо, но уже после седьмой или восьмой загруженной статьи система стала проседать. В общем и целом, все это и близко не стояло к тому инструменту для выявления фейковых новостей, который я хотел создать.
Это был полный провал.
На этом этапе мой друг Дэвид Хернандез посоветовал мне обучить модель самостоятельно обрабатывать текст. Чтобы это сделать, нам нужно было как можно больше примеров из разных категорий текстов, которые модель, по нашему замыслу, должна была бы уметь распознавать.
Так как я уже замучился в своих попытках выявить паттерны в фейковых сайтах, мы решили просто взять и собрать данные с доменов, категория которых нам точно была известна, чтобы набрать базу побыстрее. Буквально через несколько дней мой плохонький инструмент насобирал объем контента, который мы сочли достаточным для обучения модели.
Результат был хреновым. Копнув наши обучающие материалы поглубже, мы обнаружили, что их просто-напросто невозможно аккуратно расфасовать по четко ограниченным категориям, как нам бы хотелось. Где-то фейковые новости были перемешаны с нормальными, где-то попадались сплошь посты со сторонних блогов, а какие-то статьи на 90% состояли из твитов Трампа. Становилось ясно, что всю нашу базу придется перерабатывать с нуля.
Тут-то и началось самое веселье.
В одну прекрасную субботу я взялся за этот бесконечный процесс: вручную просматривать каждую статью, определять, в какую категорию она попадает, а затем неуклюже копировать ее в громадную таблицу, которая становилась все необъятнее. В этих статьях попадались по-настоящему отвратительные, злобные, расистские высказывания, на которые я поначалу старался не обращать внимания. Но уже после первых нескольких сотен они стали на меня давить. Перед глазами все рябило, цветовосприятие начало давать сбои, а состояние духа стало сильно подавленным. Как наша цивилизация докатилась до такого? Почему люди неспособны критически воспринимать информацию? Есть ли у нас еще какая-то надежда? Так все продолжалось еще несколько дней, пока я пытался наскрести достаточно материалов, чтобы модель была значимой.
Я поймал себя на том, что уже сам не уверен, что подразумеваю под «фейковыми новостями», что злюсь, когда вижу в какой-нибудь статье точку зрения, с которой не согласен, и с трудом перебарываю искушение брать только то, что мне кажется верным. В конце концов, что вообще можно считать верным, а что — нет?
Но в конце концов я все-таки дошел до того магического числа, к которому стремился, и с огромным облегчением отослал материалы Дэвиду.
На следующий день он снова провел обучение. Я с нетерпением ожидал результатов.
Мы достигли точности примерно в 70%. В первую минуту мне показалось, что это прекрасный результат. Но потом, опробовав систему на выборочной проверке нескольких рандомных статей из Сети, я понял, что реальной пользы от нее никому не будет.
Это был полный провал.
Возвращаемся к стадии рисования на доске. В чем я ошибся? Дэвид предположил, что, возможно, упрощение механизма — ключ к более высокой точности. Следуя его совету, я всерьез задумался над тем, какую проблему пытаюсь решить. И тут меня озарило: может быть, решение состоит в том, чтобы выявлять не фейковые новости, а достоверные. Достоверные новости куда проще свести в единую категорию. Они основываются на фактах, излагают их коротко и ясно и содержат минимум субъективной интерпретации. И надежных ресурсов, откуда можно набрать материалы, для них хватает.
Так что я вернулся в Интернет и в очередной раз приступил к сбору новой базы данных для обучения. Я решил распределять материалы по двум группам: истинные и неистинные. К неистинным относились сатирические заметки, статьи с субъективными мнениями, фейковые новости и все остальное, что не содержало строго фактической информации и не укладывалось в стандарты Associated Press.
На это у меня ушло еще несколько недель. Каждый день я тратил несколько часов на то, чтобы собрать новый контент со всех сайтов, которые вы только можете себе представить, от The Onion до Reuters. Я загрузил в гигантскую таблицу несколько тысяч примеров истинных и неистинных текстов, и каждый день их число возрастало еще на несколько сотен. Наконец, я решил, что материалов набралось достаточно для повторной попытки. Я отослал таблицу Дэвиду и не мог дождаться результатов.
Увидев точность выше 95%, я чуть не запрыгал от радости. Значит, нам все-таки удалось выявить паттерны в написании статей, которые отличают достоверные новости от всего того, что не стоит принимать всерьез.
Это был успех (ну, в каком-то смысле)!
Весь смысл этих махинаций состоял в том, чтобы препятствовать распространению ложной информации, поэтому я с большим удовольствием делюсь результатом с вами. Мы назвали систему Fakebox, и пользоваться ей очень просто. Нужно только вставить текст статьи, которая вызывает у вас сомнения, и нажать на кнопку «Ananlyze».
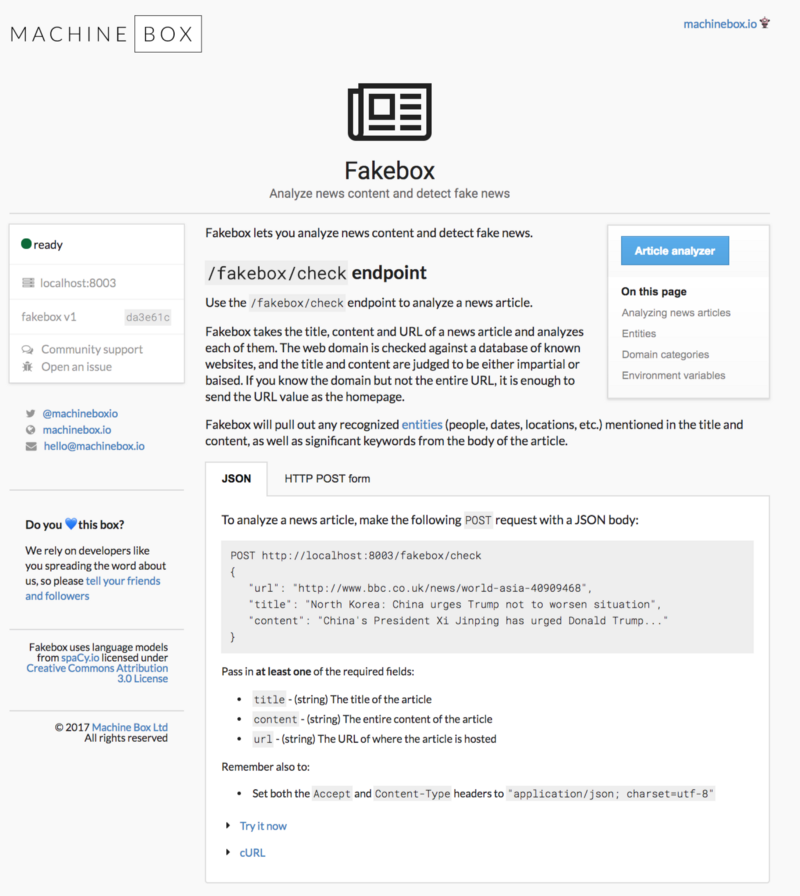
При помощи REST API Fakebox можно интегрировать в любую среду. Это контейнер Docker, так что деплоить и масштабировать его вы можете куда и как пожелаете. Перелопачивайте неограниченные объемы контента с нужной вам скоростью и автоматически помечайте все то, что требует вашего внимания.
Помните: система определяет, написан ли текст языком, характерным для достоверной новостной статьи. Если она выдает очень низкую оценку, это значит, что текст не является основанной на фактах новостной заметкой в ее классическом виде: это может быть дезинформация, сатира, субъективное мнение автора или что-то еще.
Если обобщить, мы научили модель анализировать, как написан текст, и определять, есть ли в нем оценочная лексика, авторские суждения, слова с эмоциональной окраской или нецензурные выражения. Она может давать сбои, если текст очень короткий или преимущественно состоит из цитат (или твитов) других людей. Fakebox, конечно, не решит проблему фейковых новостей окончательно, но может помочь выявить те материалы, к которым нужно относиться с долей скепсиса. Наслаждайтесь!
Глядя, как бурно развиваются машинное обучение и обработка естественного языка, я подумал: чем черт не шутит, может быть, мне удастся создать модель, которая выявляла бы новостной контент с недостоверной информацией, и тем самым хоть чуть-чуть сгладить катастрофические последствия, которые приносит сейчас распространение фейковых новостей.
С этим можно поспорить, но, на мой взгляд, самый сложный этап в создании собственной модели машинного обучения — сбор материалов для обучения. Когда я обучал модель для распознавания лиц, мне пришлось несколько дней собирать фотографии каждого из игроков лиги НБА в сезоне 2017/2018. Теперь же я и не подозревал, что мне придется провести погруженным в этот процесс несколько мучительных месяцев и столкнуться с очень неприятными и жуткими вещами, которые люди пытаются выдать за настоящие новости и надежную информацию.
Определение фейка
Первое же препятствия стало для меня неожиданностью. Изучив сайты с фейковыми новостями повнимательнее, я быстро обнаружил, что существует множество различных категорий, к которым могут относиться ложные сведения. Есть статьи с откровенным враньем, есть такие, которые приводят реальные факты, но затем неверно их интерпретируют, есть псевдонаучные тексты, есть просто эссе с мнениями автора, замаскированные под новостные заметки, есть сатира, есть компиляторские статьи, состоящие в основном из чужих твитов и цитат. Я немного погуглил и нашел разные классификации, в которых люди пытались разбить такие сайты на группы — «сатира», «фейковые», «вводящие в заблуждение» и так далее.
Я решил, что можно с тем же успехом взять их за основу, и пошел по списку приведенных сайтов, чтобы набрать оттуда примеров. Практически сразу возникла проблема: некоторые из сайтов, помеченные как «фейковые» или «вводящие в заблуждение» на самом деле содержали и достоверные статьи. Я понял, что собирать с них данные без проверки на тривиальные ошибки не удастся.
Тогда же я стал задаваться вопросом: стоит ли учитывать сатиру и субъективные тексты и если да, то куда их относить — к достоверным материалам, фейку или в отдельную категорию?
Анализ тональности
Прокорпев неделю над сайтами с фейковыми новостями, я задумался, не слишком ли усложняю проблему. Возможно, стоит просто взять какие-то из уже существующих обучающих моделей для анализа тональности и попытаться выявить закономерности. Я решил сделать простенький инструмент, который будет собирать данные: заголовки, описания, информацию об авторах и сам текст, и отсылать их модели для анализа тональности. Для последнего я использовал Textbox — это было удобно, потому что я могу запускать его локально, на своей машине, и быстро получать результаты.
Textbox выдает оценку тональности, которую можно интерпретировать как позитивную или негативную. Затем я сварганил алгоритм, который приписывал тональности каждой разновидности выгруженных данных (заголовок, авторы, текст и так далее) определенную степень значимости, и собрал всю систему воедино, чтобы посмотреть, удастся ли мне получить общую оценку новостной статьи.
Сначала все вроде бы шло неплохо, но уже после седьмой или восьмой загруженной статьи система стала проседать. В общем и целом, все это и близко не стояло к тому инструменту для выявления фейковых новостей, который я хотел создать.
Это был полный провал.
Обработка естественного языка
На этом этапе мой друг Дэвид Хернандез посоветовал мне обучить модель самостоятельно обрабатывать текст. Чтобы это сделать, нам нужно было как можно больше примеров из разных категорий текстов, которые модель, по нашему замыслу, должна была бы уметь распознавать.
Так как я уже замучился в своих попытках выявить паттерны в фейковых сайтах, мы решили просто взять и собрать данные с доменов, категория которых нам точно была известна, чтобы набрать базу побыстрее. Буквально через несколько дней мой плохонький инструмент насобирал объем контента, который мы сочли достаточным для обучения модели.
Результат был хреновым. Копнув наши обучающие материалы поглубже, мы обнаружили, что их просто-напросто невозможно аккуратно расфасовать по четко ограниченным категориям, как нам бы хотелось. Где-то фейковые новости были перемешаны с нормальными, где-то попадались сплошь посты со сторонних блогов, а какие-то статьи на 90% состояли из твитов Трампа. Становилось ясно, что всю нашу базу придется перерабатывать с нуля.
Тут-то и началось самое веселье.
В одну прекрасную субботу я взялся за этот бесконечный процесс: вручную просматривать каждую статью, определять, в какую категорию она попадает, а затем неуклюже копировать ее в громадную таблицу, которая становилась все необъятнее. В этих статьях попадались по-настоящему отвратительные, злобные, расистские высказывания, на которые я поначалу старался не обращать внимания. Но уже после первых нескольких сотен они стали на меня давить. Перед глазами все рябило, цветовосприятие начало давать сбои, а состояние духа стало сильно подавленным. Как наша цивилизация докатилась до такого? Почему люди неспособны критически воспринимать информацию? Есть ли у нас еще какая-то надежда? Так все продолжалось еще несколько дней, пока я пытался наскрести достаточно материалов, чтобы модель была значимой.
Я поймал себя на том, что уже сам не уверен, что подразумеваю под «фейковыми новостями», что злюсь, когда вижу в какой-нибудь статье точку зрения, с которой не согласен, и с трудом перебарываю искушение брать только то, что мне кажется верным. В конце концов, что вообще можно считать верным, а что — нет?
Но в конце концов я все-таки дошел до того магического числа, к которому стремился, и с огромным облегчением отослал материалы Дэвиду.
На следующий день он снова провел обучение. Я с нетерпением ожидал результатов.
Мы достигли точности примерно в 70%. В первую минуту мне показалось, что это прекрасный результат. Но потом, опробовав систему на выборочной проверке нескольких рандомных статей из Сети, я понял, что реальной пользы от нее никому не будет.
Это был полный провал.
Fakebox
Возвращаемся к стадии рисования на доске. В чем я ошибся? Дэвид предположил, что, возможно, упрощение механизма — ключ к более высокой точности. Следуя его совету, я всерьез задумался над тем, какую проблему пытаюсь решить. И тут меня озарило: может быть, решение состоит в том, чтобы выявлять не фейковые новости, а достоверные. Достоверные новости куда проще свести в единую категорию. Они основываются на фактах, излагают их коротко и ясно и содержат минимум субъективной интерпретации. И надежных ресурсов, откуда можно набрать материалы, для них хватает.
Так что я вернулся в Интернет и в очередной раз приступил к сбору новой базы данных для обучения. Я решил распределять материалы по двум группам: истинные и неистинные. К неистинным относились сатирические заметки, статьи с субъективными мнениями, фейковые новости и все остальное, что не содержало строго фактической информации и не укладывалось в стандарты Associated Press.
На это у меня ушло еще несколько недель. Каждый день я тратил несколько часов на то, чтобы собрать новый контент со всех сайтов, которые вы только можете себе представить, от The Onion до Reuters. Я загрузил в гигантскую таблицу несколько тысяч примеров истинных и неистинных текстов, и каждый день их число возрастало еще на несколько сотен. Наконец, я решил, что материалов набралось достаточно для повторной попытки. Я отослал таблицу Дэвиду и не мог дождаться результатов.
Увидев точность выше 95%, я чуть не запрыгал от радости. Значит, нам все-таки удалось выявить паттерны в написании статей, которые отличают достоверные новости от всего того, что не стоит принимать всерьез.
Это был успех (ну, в каком-то смысле)!
Фейковым новостям — бой
Весь смысл этих махинаций состоял в том, чтобы препятствовать распространению ложной информации, поэтому я с большим удовольствием делюсь результатом с вами. Мы назвали систему Fakebox, и пользоваться ей очень просто. Нужно только вставить текст статьи, которая вызывает у вас сомнения, и нажать на кнопку «Ananlyze».
При помощи REST API Fakebox можно интегрировать в любую среду. Это контейнер Docker, так что деплоить и масштабировать его вы можете куда и как пожелаете. Перелопачивайте неограниченные объемы контента с нужной вам скоростью и автоматически помечайте все то, что требует вашего внимания.
Помните: система определяет, написан ли текст языком, характерным для достоверной новостной статьи. Если она выдает очень низкую оценку, это значит, что текст не является основанной на фактах новостной заметкой в ее классическом виде: это может быть дезинформация, сатира, субъективное мнение автора или что-то еще.
Если обобщить, мы научили модель анализировать, как написан текст, и определять, есть ли в нем оценочная лексика, авторские суждения, слова с эмоциональной окраской или нецензурные выражения. Она может давать сбои, если текст очень короткий или преимущественно состоит из цитат (или твитов) других людей. Fakebox, конечно, не решит проблему фейковых новостей окончательно, но может помочь выявить те материалы, к которым нужно относиться с долей скепсиса. Наслаждайтесь!
