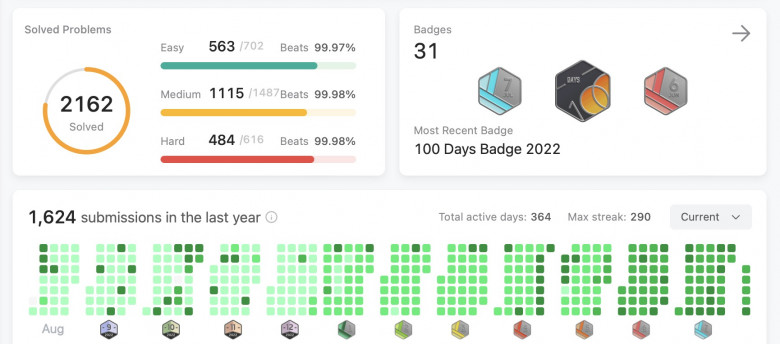
Two Generals, One Temptation: The Quantum ACK Challenge
Medium
9 min
Opinion

What if the “spooky” correlations of quantum entanglement could confirm receipt of a one-way message, ending the acknowledgment (ACK) regress in the Two Generals’ Problem, without sending anything back? This Opinion explains, in everyday terms, why standard quantum mechanics forbids that hope and offers a clear yardstick for testing claims: the quantum trigger, a hypothetical local device that would behave like an ACK if it existed. We show why such a device has zero advantage under the no-signaling rule, unpack how ordinary timing, spectral and physical-emission leakage, shared schedulers, and post-selection can impersonate a “quantum ACK,” and provide quick diagnostics any team can run.