3 пакета Python для генерации синтетических данных
6 мин

Нет данных? Сгенерируй!
Рассмотрим три самых интересных, в плане функциональности и простоты использования, способа генерации синтетических данных с помощью пакетов Python .

Компьютерный анализ и синтез естественных языков
Нет данных? Сгенерируй!
Рассмотрим три самых интересных, в плане функциональности и простоты использования, способа генерации синтетических данных с помощью пакетов Python .

Существующие алгоритмы работающие с о смыслом слов:
• Векторное представление слов, GPT-3 - статистика
• Алгоритм Леска - подбор значения многозначного слова по статистике встречаемости слов в предложении
• Семантическая сеть - информационная модель предметной области, имеет вид ориентированного графа. Вершины графа соответствуют объектам предметной области, а дуги (ребра) задают отношения между ними. (см. рис. 1)
• В других вариантах - по сути поиск закономерностей через нейросети.
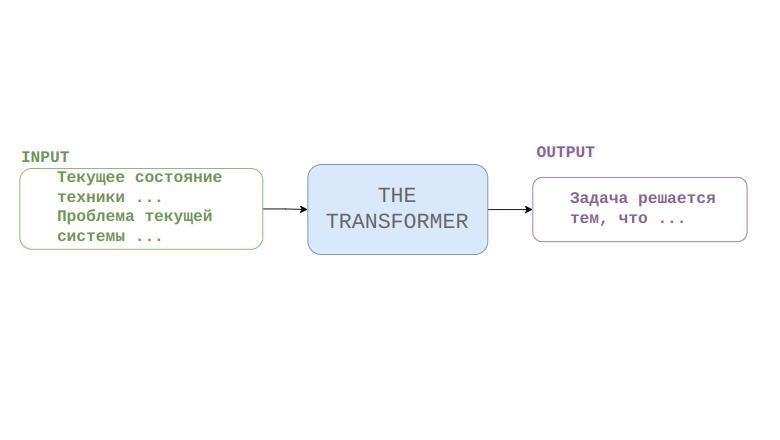
Современные языковые модели достигли впечатляющих результатов в некоторых задачах, которые раньше были под силу только человеческому разуму. Так, например, некоторые модели могут без затруднений искать ответы на вопросы, сформулированные на естественном языке в огромных массивах текстовой информации, при этом они не "подсматривают" во внешние источники, а хранят все знания в своей памяти (например, некоторые модели архитектуры T5). Можно пойти дальше и задаться целью создать языковую модель для решения специфичной изобретательской задачи, которая может стоять перед техническим экспертом. В рамках данной публикации попробуем ответить на вопрос могут ли современные нейронные сети генерировать решения изобретательских задач по описанию текущего состояния технической системы и проблемы, которую необходимо устранить.

Crono это парсер дат на естественном языке. Кроме формальных ISO 8601 или dd.MM.yyyy, распознает варианты а-ля «в среду утром», «с 10 до 11 вечера», «2 часа 5 минут назад» и т.п. Поддерживает 8 языков, в том числе, теперь, и русский.
Извлечение информации означает создание структурированных данных из неструктурированного текста. На практике задача может выглядеть так: нужно автоматически создать запись в календаре исходя из текста письма, как на рисунке ниже.
N-граммы
N-граммы – это статистические модели, которые предсказывают следующее слово после N-1 слов на основе вероятности их сочетания. Например, сочетание I want to в английском языке имеет высокую вероятностью, а want I to – низкую. Говоря простым языком, N-грамма – это последовательность n слов. Например, биграммы – это последовательности из двух слов (I want, want to, to, go, go to, to the…), триграммы – последовательности из трех слов (I want to, want to go, to go to…) и так далее.
Такие распределения вероятностей имеют широкое применение в машинном переводе, автоматической проверке орфографии, распознавании речи и умном вводе. Например, при распознавании речи, по сравнению с фразой eyes awe of an, последовательность I saw a van будет иметь большую вероятность. Во всех этих случаях мы подсчитываем вероятность следующего слова или последовательности слов. Такие подсчеты называются языковыми моделями.
Как же рассчитать P(w)? Например, вероятность предложения P(I, found, two, pounds, in, the, library). Для этого нам понадобится цепное правило, которое определяется так:
В этой статье мы поговорим о ранжирующих (retrieval) моделях диалоговых систем, и методах их персонификации.
Данный текст не является подробной и всеобъемлющей, пошаговой инструкцией по созданию диалогового агента и не претендует на большую научную ценность. Эта статья, скорее, представляет собой краткий обзор существующих методов и инструментов, применяющихся в наши дни и единственная ее задача - заинтересовать читателя и дать начальное представление о такого рода моделях оставив большой простор для собственных экспериментов.
Краткий список всего необходимого: базовое знания Python и PyTorch (если вы являетесь адептом TensorFlow, не пугайтесь, здесь будут показаны общие приемы, которые легко реализовать в других библиотеках), желательно знание библиотеки transformers, а также полезным будет минимальный опыт написания ботов для telegram (это, совершенно, не обязательно, ведь, с ботом можно общаться и в терминале) Ну что ж если вы готовы, то мы отправляемся в наше небольшое путешествие по миру диалоговых моделей.

Пандемия. Осень. Друг и бывший одногруппник, работающий на кафедре прикладной математики, попросил меня сделать курс по обработке естественного языка для МГТУ имени Баумана. Курс подразумевался быть коротким, около 10 занятий. Аудитория — студенты с первого по четвертый курс.
Студенты хотели больше знать о том, что их ждет после окончания нашего факультета и чем реально могут заниматься его выпускники. Я вспомнил, что и сам не до конца понимал, в какую сферу податься после диплома, поэтому подумал и согласился.
Хотел бы поделиться тем, с какими трудностями пришлось столкнуться, сколько времени было потрачено и кто больше узнал о предметной области, — я или студенты.

Привет. Я Игорь Буянов, старший разработчик группы разметки данных MTS AI. Я люблю датасеты и все методы, которые помогают их делать быстро и качественно. Недавно рассказывал о том, как делать иерархически датасет из Википедии. В этом посте хочу рассказать вам о Сноркеле - фреймворке для программирования данных (data programming). Познакомился я с ним случайно несколько лет назад, и меня поразил этот подход, который заключается в использовании разных эвристик и априорных знаний для автоматической разметки датасетов. Проект стартовал в Стэнфорде как инструмент для помощи в разметке датасетов для задачи information extraction, а сейчас разработчики делают платформу для пользования внешними заказчиками.
Сноркель может существенно сократить время на проверку какой-либо идеи, когда данных мало или их нет совсем, или увеличить эффективность процесса создания качественного датасета, как это потребовалось в проекте медицинского чат-бота, про который почитать можно здесь.
В этом посте я подготовил туториал, который наглядно покажет, как работать со Сноркелем, а также кратко объясню теоретические аспекты его работы.
Привет, Хабр! Хочу поделиться опытом анализа текста. Возьму рабочий пример документов в отношении граждан, проходящих процедуру банкротства. Задача заключается в автоматизированном сборе информации из текста 300 тыс. документов такой как: номер счета, с которого можно снять средства, разрешенная сумма, период действия. Пример интересующей меня части документа:

Меня зовут Александр Брыль, я дата-саентист в команде NLP СберМегаМаркета и сегодня хочу рассказать, как мы искали быстрое и удобное решение для исправления ошибок в поисковых запросах маркетплейса: зачем нам это понадобилось, как мы сравнивали автокорректоры Яндекс.Спеллер, корректор от DeepPavlov, SymSpell и на чем в итоге решили остановиться.


Предлагаю немного поразвлечься и научиться придумывать новые слова, которые звучат совсем как настоящие (прям как товары в Икее). Для начала вот вам десяток несуществующих городов:
• Лумберг, Сеф, Хирнов, Бинли, Лусский, Ноловорск, Сант-Гумит, Хойден, Голтон и Оголенда
И женских имен:
• Инела, Каисья, Ганнора, Целия, Тарисана, Лелена, Феомина, Олиcc, Нулина и Рослиба
Для запуска генерации нам не понадобится технических навыков, хотя технология, стоящая за ней, сейчас является очень перспективной и многофункциональной. Это генеративная нейронная сеть, способная решать множество задач по обработке естествнного языка (NLP). Это такие задачи как суммаризация (сделать из большого текста его резюме), понимание текста (NLU), вопросно-ответные системы, генерация (статей, кода или даже стихов) и другие. Тема эта очень глубокая, поэтому далее я дам пару ссылок для любителей копнуть поглубже. А те, кто хочет "только спросить", может сразу приступить к созданию слов.
Генерировать будем скриптом makemore от Андрея Карпати (недавно писал про скрипт в канале градиент обреченный), который он выложил пару недель назад. Андрей является известным исследователем в мире ИИ и периодически радует народ такими вот игрушками, можно полазить по его репозиторию, там еще много интересного.
Запустим скрипт.

В этой статье я бы хотел рассказать о совместной работе с @elizavetakluchikova и командой над тем, как бы применяем машинное обучение для облегчения поиска и оценки людей с суицидальными наклонностями по постам в социальных сетях, в частности, в Твиттере.
Прежде всего, мы отсылаем читателя к предыдущей статье, где рассказывалось о суицидальных играх, о команде людей, которая за шиворот вытаскивает детей из петли или с подоконника, а также о проблемах, с которыми сталкивается команда. Я прочитал эту статью и подумал, что мог бы помочь им, применив свои знания в обработке естественного языка. В результате работы, был собран датасет, который можно скачать здесь, а также была написана научная статья, которая была опубликована на конференции Диалог 2022.
Этот же пост был написан совместно с Лизой, где мы углубленно рассказываем о психологической подоплеке работы, а также о некоторых деталях работы, которые не были упомянуты в статье.
Как известно, один и тот же адрес можно написать различными текстовыми способами, используя сокращения, перестановку, вариации наименований и т.п. Встаёт вопрос: существует ли процедура нормализации, отождествляющая реально одинаковые и по-разному записанные адреса?
Ответ положительный, чему и посвящена данная статья.
Какие средства в принципе есть для решения задачи? Их сейчас два: выделение именованных сущностей (NER) и объекты ГАР ФИАС. NER даёт разбиение на адресные элементы и их нормализацию, ГАР ФИАС может дать уникальные идентификаторы. Задача решается, если в качестве нормализации взять множество строк из возможных нормализаций наименований элементов, добавив к ним GUID-идентификаторы ГАР, если получится. Два адреса эквивалентны, если хотя бы одна строка из множеств таких их строк совпадает.
А одними объектами ГАР ФИАС можно обойтись, используя только их идентификаторы? Конечно, нет. Во-первых, это не полный классификатор, особенно в части помещений и строений, хотя и постоянно пополняемый. Во-вторых, в адресах бывают специфические элементы, которые в ГАР отсутствуют (например, Московская область, Можайский район, примерно в 0,1 км по направлению на юг от ориентира середина д.Бараново, или пересечение улиц).
Итак, утверждается, что невозможно обойтись для адреса только одной нормализованной строкой для отождествления в общем случае. Но если таких строк будет несколько, причём сформированных определённым образом, то отождествление будет с очень высокой вероятностью.
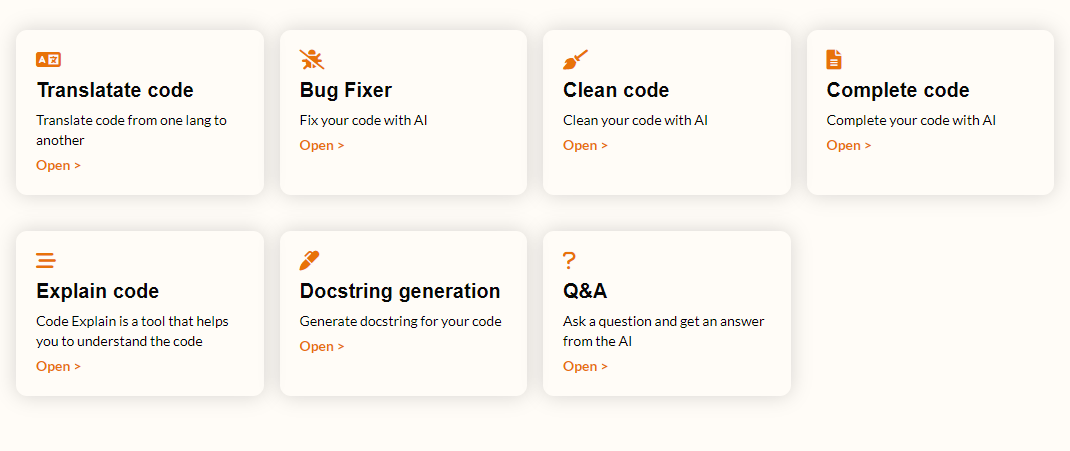
Думаю, многие знают изобретение Codex от OpenAI. Это мощная нейронная сеть, которая может делать любые операции с программным кодом. Она бесплатна, но доступна ограниченному кругу лиц.
Мне удалось получить доступ к сие чуду. Я, как любитель всего открытого, решил косвенно дать людям доступ к Codex, поэтому я разработал сервис - CodeTools. С помощью него можно перевести код с одного языка на другой, упростить код, задокументировать код, дополнить код и многое другое...

Привет, я Игорь Буянов, работаю в MTS AI старшим разработчиком в департаменте машинного обучения в команде разметки и сбора данных.
В этом руководстве я покажу, как на основе Википедии можно сделать текстовый датасет, метки которго будут иметь иерархию. Необходимость в таком датасете возникла при тестировании различных подходов к эксплуатации иерархичности меток [3]. Иерархией меток могут представлены интенты, которые распознает чат-бот при запросе пользователя: является ли обращение пользователя заявлением о проблем с медленным интернетом или тем, что он вообще отсутствует. Общим классом здесь будет интернет, а подклассом будет скорость и отсутствие интернета, соответственно. Материалы доступны на нашем гитхабе.
Скажу сразу, что большего датасета не получилось, но сам метод показался мне достаточно интересным, чтобы о нём рассказать. Возможно, кому-то этот метод поможет кому-то начать свои исследования. Это руководство — третья часть неформальной серии статей о парсинге Википедии (первая часть, вторая часть).

Для выявления ключевых слов, для начала будет решена задача кластеризации на тематики текстов с помощью метода LDA (Latent Dirichlet Allocation). После этого будет решаться задача, непосредственно, выявления ключевых словосочетаний с помощью предобученной модели Bert. И завершающим будет метод WordToVec, служащий для решения задачи поиска наиболее семантически похожих слов в тексте.

Upd. 11.06.2022 Многие заинтересовались генерацией изображений нейросетями. Вот Colab (интерактивная среда для запуска кода) для рисования картинок в стиле pixel art по текстовому описанию. Просто запускайте, ближе к концу увидете ячейку для ввода текста. Примеры картинок из Colab'а в комментариях.
Два года назад я начал делать небольшой проект, связанный с обработкой текстов на иностранных языках. Он постепенно развивался и стал использоваться лингвистами в НКРЯ, а энтузиасты сохранения малых языков используют его для расширения своих параллельных корпусов.
Сегодня же я расскажу как при помощи него создать полноценную параллельную книгу на разных языках. Книга будет красиво сверстана в PDF, иметь содержание, обложку и две выровненные по смыслу колонки текста. Такие книги служат отличным подспорьем при изучении иностранного языка. Найти их, однако, не так просто, и скорее всего это будут книги для детей или избранная классика. Полный пример готовой книги можно посмотреть здесь. Под капотом у приложения NLP модели, поддерживаемых языков более ста.
Проект открытый и любой может в нем поучаствовать. Во многом благодаря сообществу и вашему участию он за несколько лет дошел до сегодняшнего дня. В общем штука годная, давайте уже посмотрим, что к чему.

Привет,
Это статья нашего бывшего коллеги, Андрея Лукьяненко, который работал над проектом по созданию медицинского чат-бота. Андрей покинул нашу компанию по собственному желанию (и с большим сожалением для нас), но несмотря на это, мы решили опубликовать его материал. Мы уверены, что эта статья будет полезна всем, кто работает над созданием специализированных чат-ботов.
Итак, передаем слово Андрею Лукьяненко, бывшему техлиду MTS AI.
В последние годы рынок телемедицины (дистанционных медицинских услуг) и в целом медтеха активно растет, и пандемия коронавируса только ускорила его развитие. Такие технологии востребованы, потому что они относительно дешевы, доступны вне зависимости от места проживания пациента и дают возможность самостоятельно выбирать врачей.