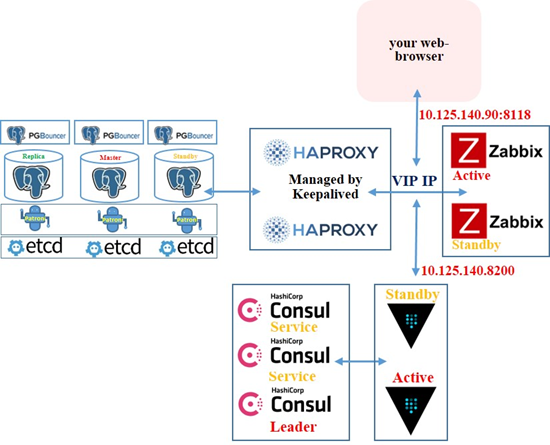
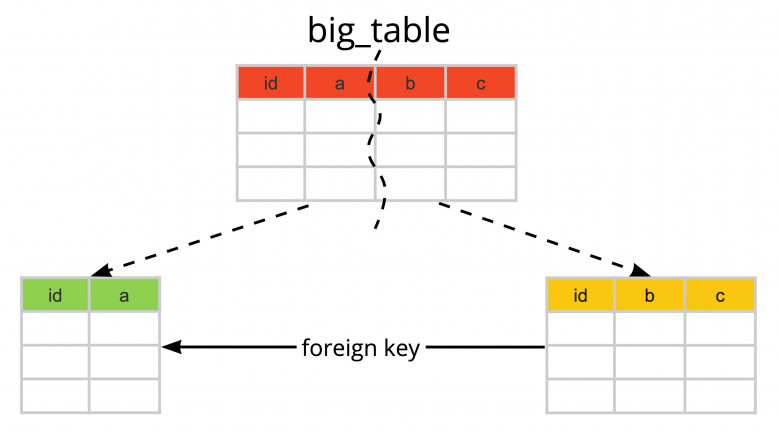
Как и когда пора начинать коммитить в OSS
По долгу службы, мы много работаем с деньгами. Складываем, вычитаем, считаем проценты. Любому школьнику известно, что для этих расчетов не подходят обычные встроенные в язык типы: флоаты не сойдутся у финансовых аудиторов, большие целые принесут кучу проблем при конвертации (например, йены обходятся без дробных единиц, а в одном оманском риале — 1000 баиз, а не сто, как у всяких плебейских долларов и евро), и так далее. Существуют целые комитеты, определяющие стандарты (ISO 4217 — коды валют и ISO 24165 — идентификаторы цифровых токенов). Во всех более-менее современных языках есть библиотеки для работы с денежными суммами, реализующие стандарты и скрывающие от нас адовую арифметику без потерь точности.
В мире эликсира, почти всем, что связано с имплементацией комитетских стандартов, занимается Кип Коул. Удобной работе с деньгами мы обязаны тоже его библиотекам: ex_money — для собственно арифметики и money_sql для персистенса.