PostgreSQL 16: Part 1 or CommitFest 2022-07
7 min
Translation
August was a special month in PostgreSQL release cycle as the first CommitFest for the 16th PostgreSQL release was held.
Let's compile the server and check out the cool new stuff!

Domain-specific languageused in programming and designed for managing data held in a relational database management system, or for stream processing in a relational data stream management system
August was a special month in PostgreSQL release cycle as the first CommitFest for the 16th PostgreSQL release was held.
Let's compile the server and check out the cool new stuff!

In the previous articles, we have covered query execution stages, statistics, sequential and index scan, and two of the three join methods: nested loop and hash join.
This last article of the series will cover the merge algorithm and sorting. I will also demonstrate how the three join methods compare against each other.

So far we have covered query execution stages, statistics, sequential and index scan, and have moved on to joins.

In previous articles we discussed query execution stages and statistics. Last time, I started on data access methods, namely Sequential scan. Today we will cover Index Scan.
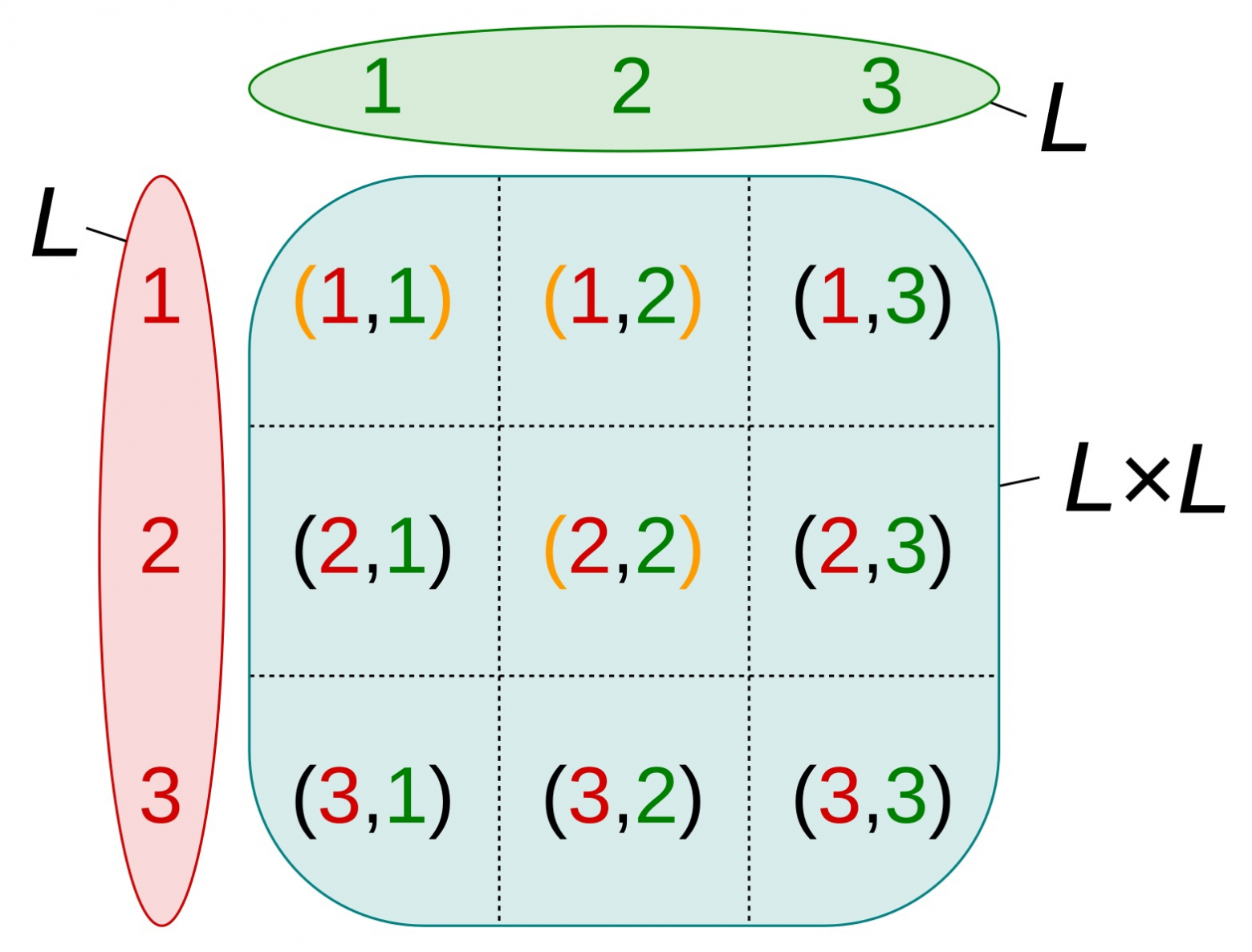
In this article, we would like to compare the core mathematical bases of the two most popular theories and associative theory.
In previous articles we discussed how the system plans a query execution and how it collects statistics to select the best plan. The following articles, starting with this one, will focus on what a plan actually is, what it consists of, and how it is executed.
In this article, I will demonstrate how the planner calculates execution costs. I will also discuss access methods and how they affect these costs, and use the sequential scan method as an illustration. Lastly, I will talk about parallel execution in PostgreSQL, how it works, and when to use it.
I will use several seemingly complicated math formulas later in the article. You don't have to memorize any of them to get to the bottom of how the planner works; they are merely there to show where I get my numbers from.

In the last article we reviewed the stages of query execution. Before we move on to plan node operations (data access and join methods), let's discuss the bread and butter of the cost optimizer: statistics.
Dive in to learn what types of statistics PostgreSQL collects when planning queries, and how they improve query cost assessment and execution times.
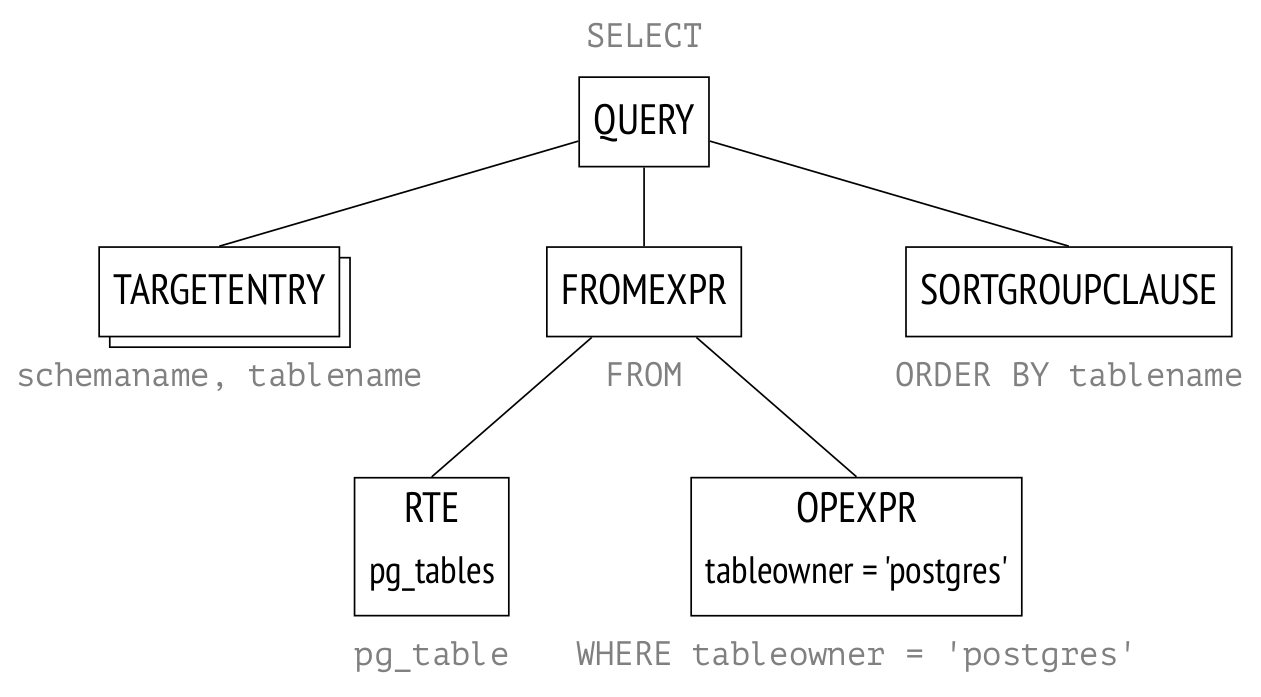
Hello! I'm kicking off another article series about the internals of PostgreSQL. This one will focus on query planning and execution mechanics.
In the first article we will split the query execution process into stages and discuss what exactly happens at each stage.
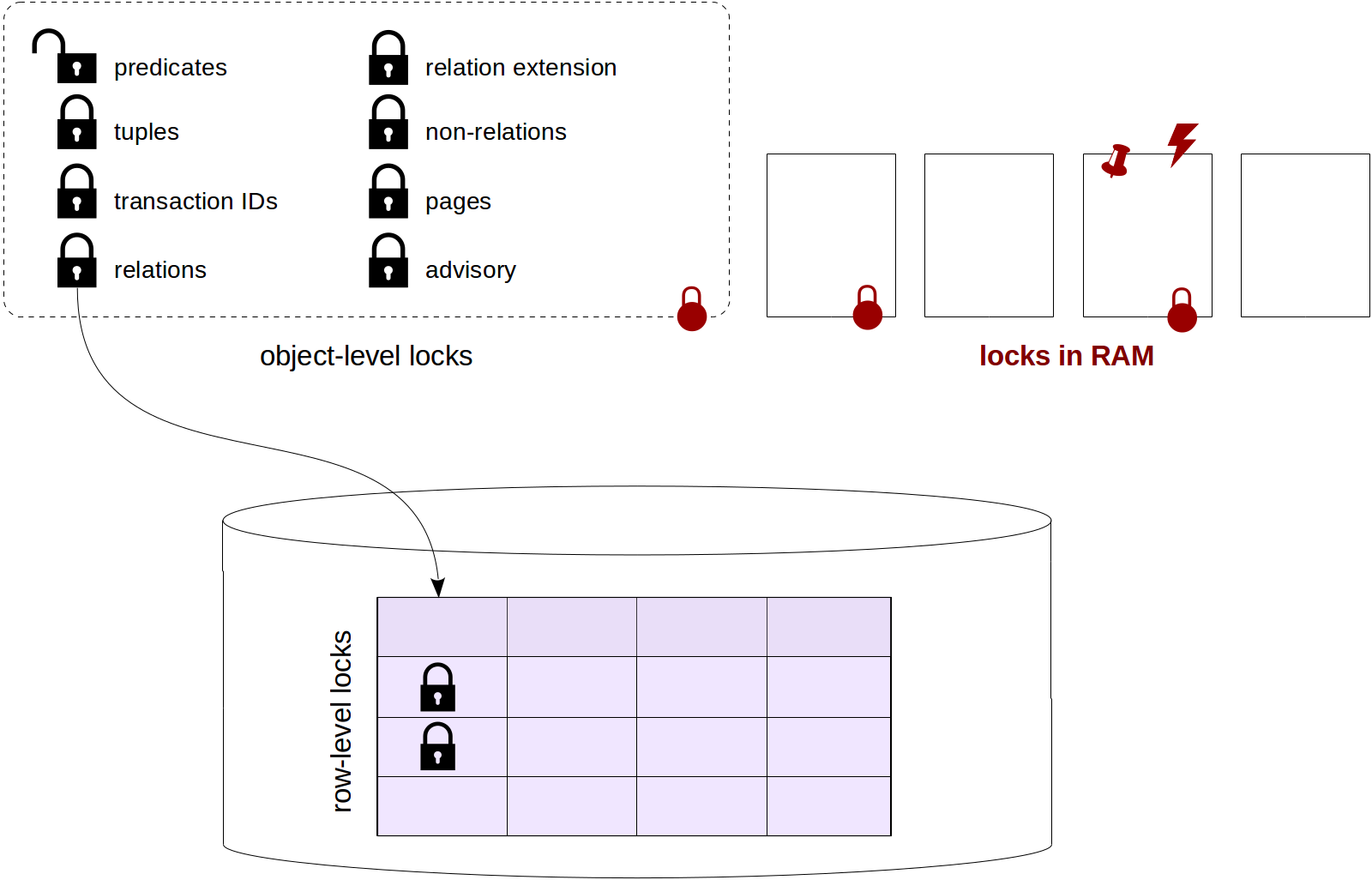
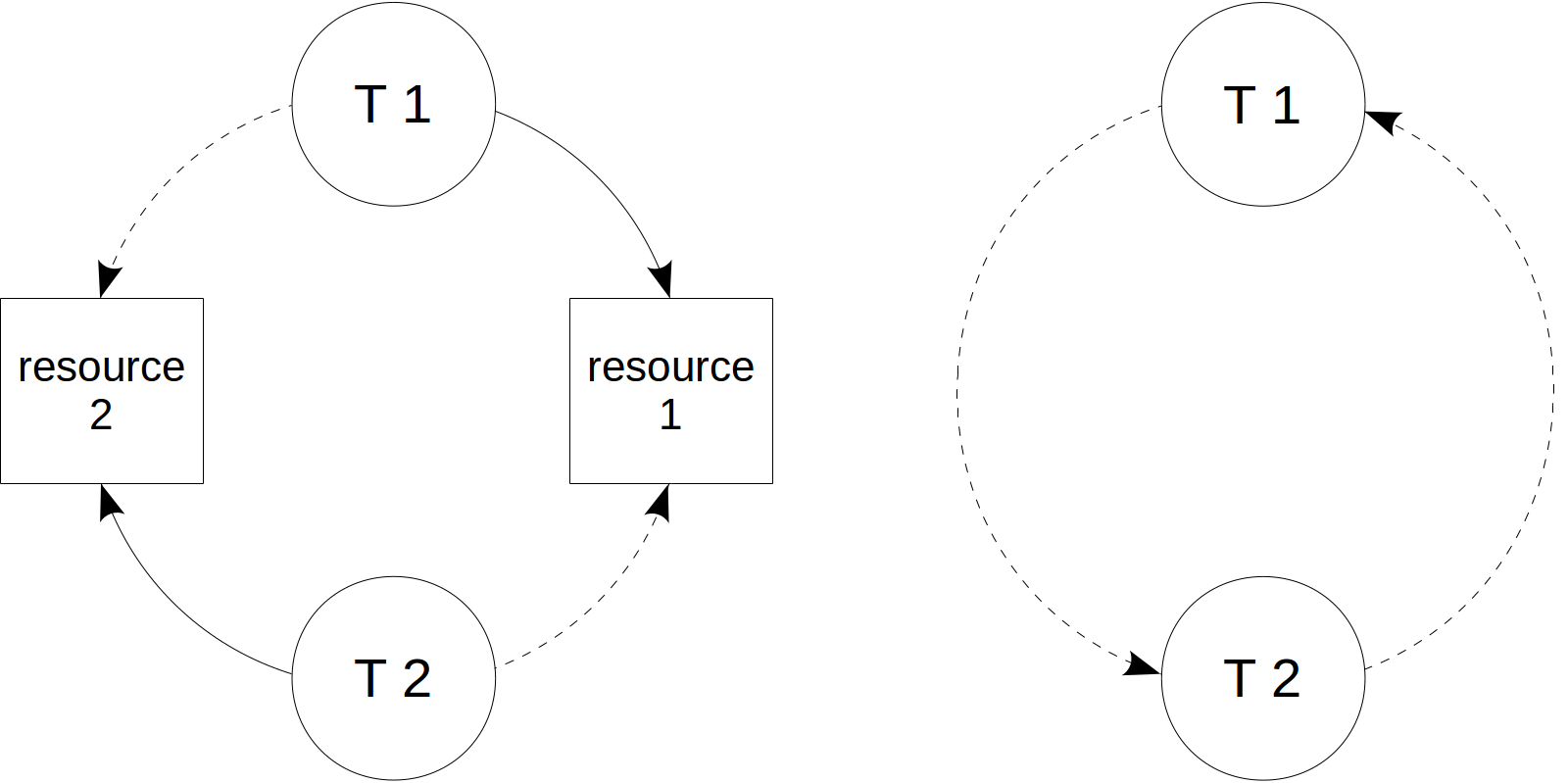
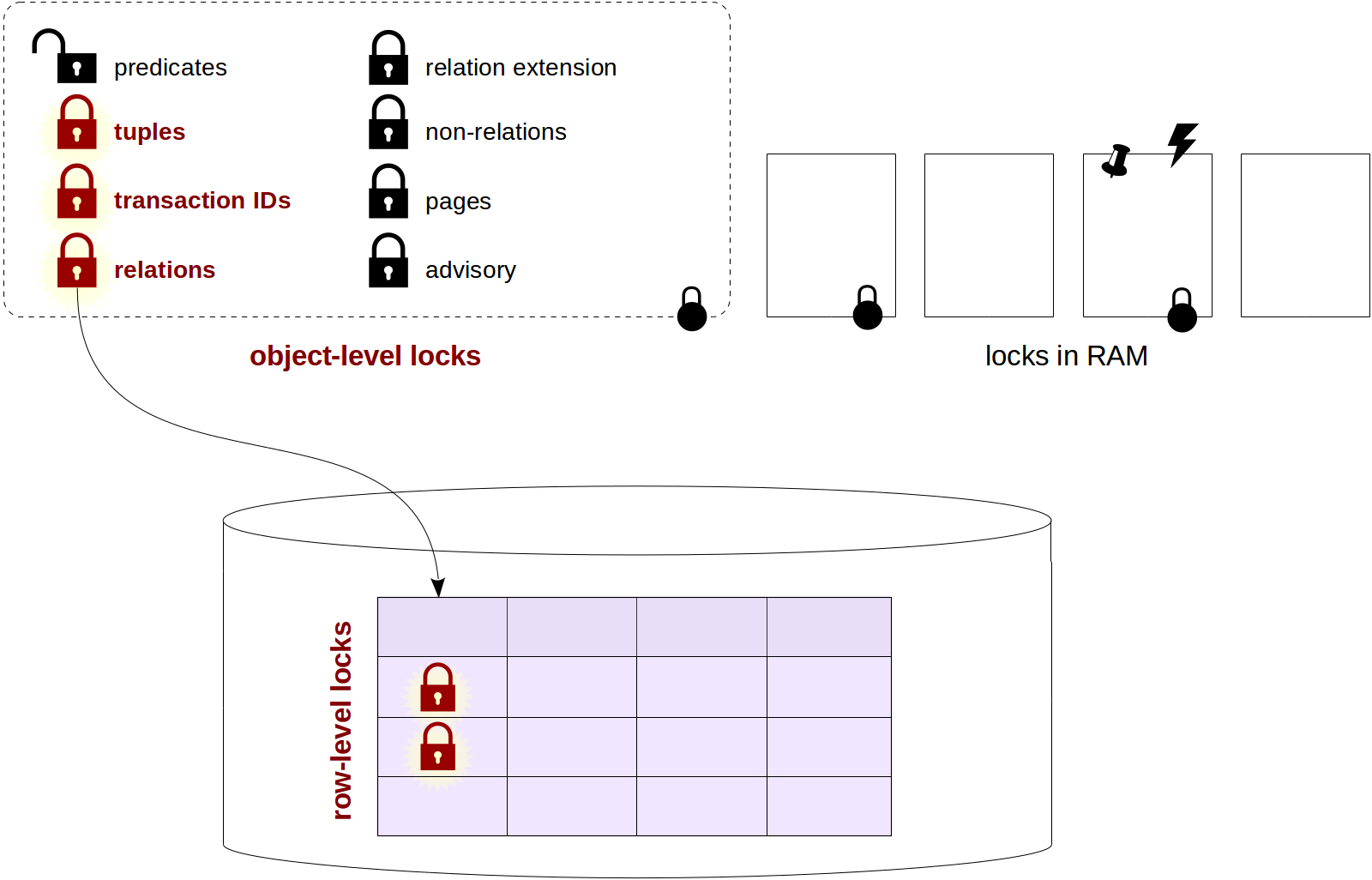
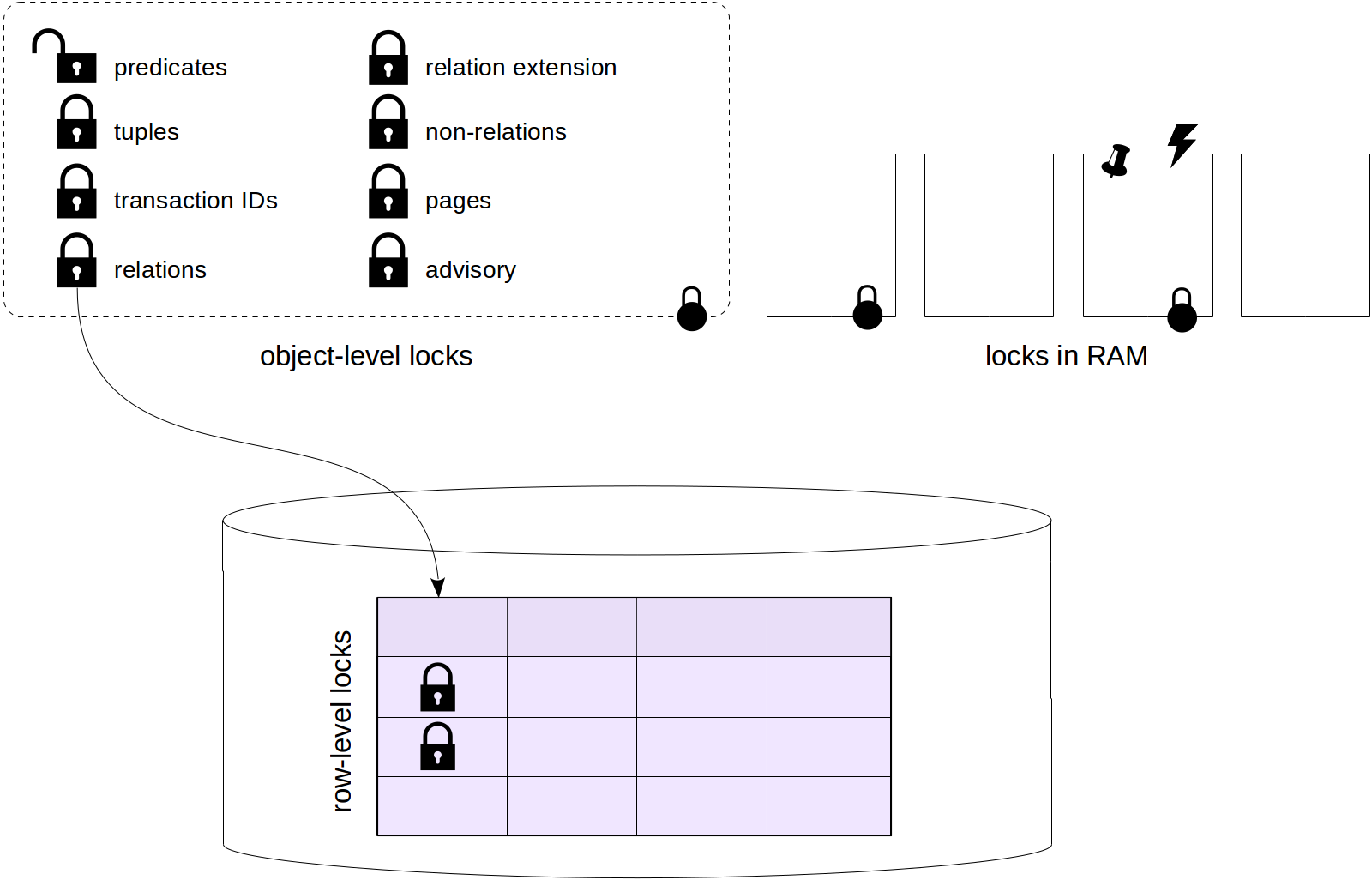
Many thanks to Elena Indrupskaya for the translation of these articles into English.
The standard definition of Transaction state that “Every Query batch that runs in a SQL server is a Transaction.”, this means any query you run on a SQL server will be considered as a Transaction it could either be a simple SELECT query or any UPDATE or ALTER query.
If you run a query without mentioning the BEGIN TRAN keyword then it would be considered as an Implicit transition.
If you run a query which starts with BEGIN TRAN and ends with COMMIT or ROLLBACK then it would be considered as Explicit Transaction.
Many thanks to Elena Indrupskaya for the translation of these articles into English.