Comments 77
Круто. Молодчина.
Мне вообще кажется, что подобный функционал должен быть в самом клиенте.
Должна быть! Но мое кунгфу не настолько сильное, чтобы с ним лезть в исходники трансмиссии или рторрента.
Функционал вам ничего не должен. Берите и пишите.
Как альтернативный вариант — интегрировать в клиент примитивный файл-менеджер, при перемещении файла в котором линки обновляются ИЛИ написать плагин для тотал-коммандера который будет обновлять эти линки
Здорово! Чтобы форма не подвисала во время сканирования можно использовать BackgroundWorker
Чтобы форма не подвисала во время сканирования можно использовать BackgroundWorker
Я бы даже сказал нужно. Вообще делать работу в том же потоке, что работает UI — очень дурной тон и годиться только для «quick&dirty» прототипов. На крайняк, если лень писать нормально, но хочется придать поделке товарный вид, есть такая альтернатива как явный вызов обработки сообщений внутри тела рабочего цикла.
Совершенно верно. На месте автора я бы сделал консольное приложение, а эксперты по UI могут все написать сами, по своим вкусам и желаниям. Ссылка на репозиторий в самом посте.
Да, а еще хорошо бы прогресс-бар использовать.
явно не менял расширения файлов. Имя мог поменять, а вот расширение вряд ли
Если расширение было в верхнем регистре — поменяю его на нижний практически обязательно.
Вообще лично для себя я вижу эту задачу немного иначе.
Когда-то я имел отдельные папки по разным трекерам, хранил все torrent-файлы и не переименовывал и не перемещал сами файлы. Сейчас всё уже не так — практически всё скачанное переименовано, пересортировано, и расползлось по разным жёстким дискам. И я, разумеется, не помню сколько-нибудь полного списка того, что и откуда я качал.
Соответственно задача в идеальном случае (не знаю на сколько это возможно — может быть это заняло бы дохренища времени):
Скачать ВСЕ (ну или хотя бы из определённых разделов, исключив некоторые разделы по нехарактерным для меня темам) torrent-файлы с нескольких трэкеров и просканировать примерно 3 терабайта «файлопомойки» на предмет соответствия искомым хэшам.
При этом есть и вовсе нерешаемые проблемы: некоторые файлы шли в архивах и я их разархивировал, некоторые наоборот заархивировал, а в некоторых музыкальных файлах поменял теги так что хоть контент и имеется, это уже другие файлы с другими хэшами.
Когда-то я имел отдельные папки по разным трекерам, хранил все torrent-файлы и не переименовывал и не перемещал сами файлы. Сейчас всё уже не так — практически всё скачанное переименовано, пересортировано, и расползлось по разным жёстким дискам. И я, разумеется, не помню сколько-нибудь полного списка того, что и откуда я качал.
Соответственно задача в идеальном случае (не знаю на сколько это возможно — может быть это заняло бы дохренища времени):
Скачать ВСЕ (ну или хотя бы из определённых разделов, исключив некоторые разделы по нехарактерным для меня темам) torrent-файлы с нескольких трэкеров и просканировать примерно 3 терабайта «файлопомойки» на предмет соответствия искомым хэшам.
При этом есть и вовсе нерешаемые проблемы: некоторые файлы шли в архивах и я их разархивировал, некоторые наоборот заархивировал, а в некоторых музыкальных файлах поменял теги так что хоть контент и имеется, это уже другие файлы с другими хэшами.
частичная проверка хешей поможет от измененных тегов, особенно если размер пайсов небольшой.
Умнó. Не подумал такой возможности. Спасибо.
На самом деле все очень натянуто. К примеру, если поменяется размер тега в начале файла, то будет сдвиг всех данных файла. В этом случае посчитать хеш конечно можно, но с какой позиции его считать? Что уже скорее невозможно.
А вот поменяется ли размер от изменения тегов — опять непонятно. Будет ли приложение добавлять паддинг тегу или сразу запишет данные — зависит только от него. Будет ли сохранен паддинг, или нет — опять не ясно. Все зависит от конкретных реализаций.
Я пришел к такому выводу — музыку не раздавать вообще. Ну, почти.
Т.е. есть две папки:
.../music — здесь музыкальная коллекция. Всё красиво, организованно
.../INBOX/music — сюда попадает новая музыка. Она лежит какое-то время, раздаётся, а потом, когда руки доходят и файлы меняются, с раздачи снимается.
Всё потому что крайне мало треков, где что-нибудь не изменено.
Т.е. есть две папки:
.../music — здесь музыкальная коллекция. Всё красиво, организованно
.../INBOX/music — сюда попадает новая музыка. Она лежит какое-то время, раздаётся, а потом, когда руки доходят и файлы меняются, с раздачи снимается.
Всё потому что крайне мало треков, где что-нибудь не изменено.
Размер поменяется, а вот раздавать все равно можно будет, но только те части файлов в которых находится непоследственно музыка. Те части, в которых находятся теги, будут, естественно, признаны негодными для раздавания.
Как будешь их искать?
Сейчас проверяется только первый кусок, и, если его хеш совпадает, то он считается нашим. Можно проверять все куски, которые есть в этом файле (это есть, отлажу и запилю), но тут возникает вопрос, как считать правильность? Можно считать подходящим только тот файл, у которого совпал хеш всех проверенных кусков. А можно выставить «порог доверия», то есть говорить, что файл наш, если совпали, скажем, 75% кусков, независимо от их положения в файле.
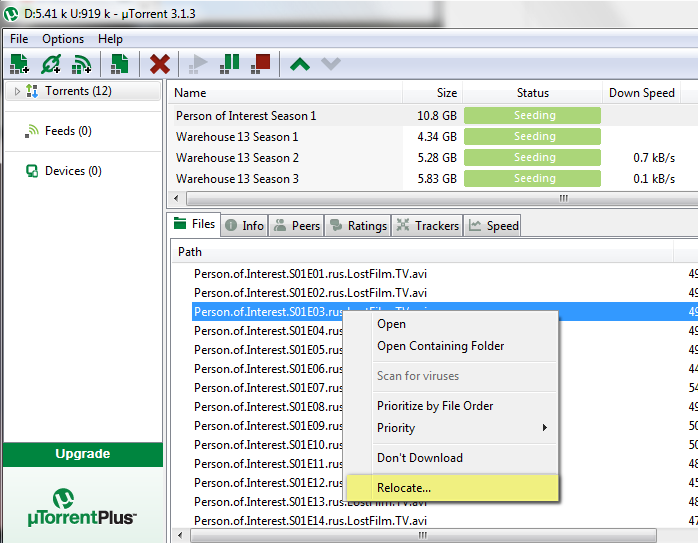
«Найти в куче файлов тот, который соответствует описанному в .torrent, и переместить его в папку, соответствующую пути в .torrent.»
На мой взгляд, было бы логичнее оставить файл где есть, а изменить путь к нему в торренте. Например, если у меня расползется по папкам с кривыми путями та же тщательно отструктурированная и проименованная Бондиада (напр. Nekogda.ne.govori.nekogda, как написал недавно безызвестный автор), я буду недоволен.
На мой взгляд, было бы логичнее оставить файл где есть, а изменить путь к нему в торренте. Например, если у меня расползется по папкам с кривыми путями та же тщательно отструктурированная и проименованная Бондиада (напр. Nekogda.ne.govori.nekogda, как написал недавно безызвестный автор), я буду недоволен.
Обязательно попробую поковырять в этом направлении. Создайте issue на github, а то могу забыть.
Меня на гитхабе нет ввиду отсутствия необходимости, извините.
О как. За отсутствие учетки на гитхабе нынче минусуют? А если у меня реально нет необходимости в его использовании — я недочеловек?
>За отсутствие учетки на гитхабе нынче минусуют?
А скоро вообще морду бить будут! Останавливают тебя на районе, и так «Есть учетка на Гитхабе? А ну ка дай по-быстрому одну issue зарепортить?»
А скоро вообще морду бить будут! Останавливают тебя на районе, и так «Есть учетка на Гитхабе? А ну ка дай по-быстрому одну issue зарепортить?»
такое раздавать в прежней раздаче уже нельзя
{kind=link}
Щито? Переместить файл в торрент-клиенте — это одно. Переместить его в торрент-файле — совершенно другое. Информация о имени/пути лежит внутри info-чанка. Идентификационный хеш считается на основе info-чанка. Поменяв 1 букву в имени, мы получим уже другой торрент, о прежней раздачи говорить уже нельзя.
В таком случае затея практически лишена смысла. Подозреваю, что мало кто хранит файлы в оригинальных названиях после завершения закачки, как правило они неудобоваримы или принципом наименования противоречат замыслу пользователя.
В таком случае предлагаю расстрелять автора за то, что написал никому не нужное изделие, создал никому не нужный тред, потратил время уважаемые посетителей уважаемого ресурса, да и вообще из-за него идет снижение ВВП.
«Оригинальные названия» действительно в подавляющем большинстве случаев меня не устраивают. Приходится не лениться и изменять название в процессе добавления торрента в список закачек клиента. В «Мюторренте» (по-моему и в Делюге тоже такое делал) это приводит к тому, что в списке закачек клиента у раздачи остаётся «оригинальное название», а на винте — то, которое было указано при добавлении торрента.
Сори, сонный, пишется темно и вяло. Но думаю, всем понятно, что я подразумеваю.
Сори, сонный, пишется темно и вяло. Но думаю, всем понятно, что я подразумеваю.
Так в клиенте перемещать и надо. У мюторрента в нутрях конфигов примерно тот же формат берётся за основу, что и у торрентов, вроде. Привязка к клиенту, конечно, но, думаю, его популярность очень высока.
Если бы все трекеры оперировали расширением BitTorrent, которое добавляет magnet-ссылку, всё было бы гораздо, гораздо прощею
Да… А ведь хотелось бы просто в клиенте указать — найди файлы этих раздач вон в той папке и раздавай… чтоб он сам все это сделал, никуда не копируя их.
Причина этого ограничения — использование при сканировании директорий параметра `SearchOption.AllDirectories`, что приводит к вылету при попытке прочитать закрытые директории типа корзины или `System Volume Information` (если знающие люди подскажут как это обойти, то буду весьма признателен).
Я не сильно знающий человек, но может просто проверять аттрибуты и не искать среди скрытых и системных файлов?
А зачем перемещать, может прости симлинк сделать на каждый фаил? Мне кажется это более логичным. На linux/osx лучше даже хардлинки сделать.
Хорошая работа, однако было бы хорошо добавить решим «кандидатов». К примеру, есть у нас торрент с мелкими файлами, части файлов нет, как следствие хеш проверить мы не можем. Однако, используя данные о размере файлов можно попробовать найти все файлы данного размера и поместить их в директорию «кандидаты», а что делать с ними дальше — пусть решает человек.
Но это наверное особого смысла не имеет, торренты с мелкими файлами можно зачастую перекачать, хотя недавно по интернету ходил торрент-файл с 80к мелких картинок.
Еще фича: файлы «частично похожие», когда мы имеем сегменты для проверки хеша, но все хеши не совпадают. Такое может случиться из-за повреждения данных на диске/изначальной недокачанности.
Но это наверное особого смысла не имеет, торренты с мелкими файлами можно зачастую перекачать, хотя недавно по интернету ходил торрент-файл с 80к мелких картинок.
Еще фича: файлы «частично похожие», когда мы имеем сегменты для проверки хеша, но все хеши не совпадают. Такое может случиться из-за повреждения данных на диске/изначальной недокачанности.
Можно попробовать вместо перемещения и переименования файлов создавать для них симлинки с правильными именами в отдельной папке.
Григорий, выше уже поднималась несколько раз просьба. Повторю применительно к своей проблеме (думаю она есть у многих):
Есть библиотека электронных книг, скаченных из разных мест Интернета. С другой стороны эти книги присутствуют во многих раздачах на рутрекере и часто дублируются. Очень хочется встать со своим складом на все раздачи.
Переместить файлы, как Вы реализовали, не получиться по 2м причинам:
1. Они расположены на диске в порядке, удобным для работы
2. На рутрекере файлы многократно повторяются в раздачах, боюсь винчестера не хватит.
спасибо
Есть библиотека электронных книг, скаченных из разных мест Интернета. С другой стороны эти книги присутствуют во многих раздачах на рутрекере и часто дублируются. Очень хочется встать со своим складом на все раздачи.
Переместить файлы, как Вы реализовали, не получиться по 2м причинам:
1. Они расположены на диске в порядке, удобным для работы
2. На рутрекере файлы многократно повторяются в раздачах, боюсь винчестера не хватит.
спасибо
Только писать/патчить торрент-клиент, достаточно интересная затея. Правда неприменимо для мелких файлов, так как фактически будут раздаваться только части этих самых файлов.
К примеру: есть книга размером в 5 мегабайт, эта же книга есть в 10 раздачах. Если раздача начинается с этой книги, то мы уверенно можем раздать ее начало. Конец — только при условии, что ее размер кратен размеру пайса, или у нас есть книга, которая лежит дальше в торренте. К примеру, пусть размер пайса будет равен 2 метрам, тогда мы сможем раздать 4 метра этой книги. Если книга внутри торрента расположена не в начале, то мы не можем раздать и начало, в первых 2 метрах (минус 1 байт) может быть что-то у нас отсутствующее, равно как и в конце. Следовательно, на такой раздаче мы можем раздать только кусочек в 2 метра, хотя у нас все 5 есть.
Еще недостаток — трекеры, которые не дают скачивать метадату в больших количествах (те самые торренты), вы просто не найдете все раздачи со своей книжкой, особенно если она переименована. Я нечто подобное просил сделать на рутрекере, но меня очень сильно замодерировали.
А так штука была бы интересной и полезной.
К примеру: есть книга размером в 5 мегабайт, эта же книга есть в 10 раздачах. Если раздача начинается с этой книги, то мы уверенно можем раздать ее начало. Конец — только при условии, что ее размер кратен размеру пайса, или у нас есть книга, которая лежит дальше в торренте. К примеру, пусть размер пайса будет равен 2 метрам, тогда мы сможем раздать 4 метра этой книги. Если книга внутри торрента расположена не в начале, то мы не можем раздать и начало, в первых 2 метрах (минус 1 байт) может быть что-то у нас отсутствующее, равно как и в конце. Следовательно, на такой раздаче мы можем раздать только кусочек в 2 метра, хотя у нас все 5 есть.
Еще недостаток — трекеры, которые не дают скачивать метадату в больших количествах (те самые торренты), вы просто не найдете все раздачи со своей книжкой, особенно если она переименована. Я нечто подобное просил сделать на рутрекере, но меня очень сильно замодерировали.
А так штука была бы интересной и полезной.
Я бы зашёл со стороны дедупликации в файловой системе.
дубли в файловой системе и в торрентах — две большие разницы. Дубли на ФС (и даже на уровне секторов) найти проще.
Скорее всего имеется в виду такая ситуация: есть два .torrent-файла раздач, в которых присутствует один или несколько одинаковых файлов. Если мы будем копировать найденные на диске файлы, то получится как раз избыточность данных на диске. Это можно решить с помощью хардлинков.
Ты можешь найти 2 одинаковых файла в разных торрентах? Как?
Нет. Пример того, что я имел в виду.
Нашли два .torrent-файла, в которых есть один одинаковый файл. Мы их скачали, отсортировали для удобства пользования, и у нас на диске остался только один файл (ну в коллекции книг, например, нет смысла держать две одинаковых). И тут мы захотели вернуться на ОБЕ раздачи. Мы, немного изменив код программы, вернули все как было и получили, что файлов одинаковых снова два, и они оба занимают место.
И вот тут-то хороша система хардлинков.
А про поиск двух одинаковых файлов в .torrent — не такая большая проблема, если немного изучить строение фалов и переосмыслить статью в контексеt поиска не файлов на диске, а описания файлов в другом файле.
Нашли два .torrent-файла, в которых есть один одинаковый файл. Мы их скачали, отсортировали для удобства пользования, и у нас на диске остался только один файл (ну в коллекции книг, например, нет смысла держать две одинаковых). И тут мы захотели вернуться на ОБЕ раздачи. Мы, немного изменив код программы, вернули все как было и получили, что файлов одинаковых снова два, и они оба занимают место.
И вот тут-то хороша система хардлинков.
А про поиск двух одинаковых файлов в .torrent — не такая большая проблема, если немного изучить строение фалов и переосмыслить статью в контексеt поиска не файлов на диске, а описания файлов в другом файле.
«Нашли два .torrent-файла, в которых есть один одинаковый файл» — как нашли? Даже если они уже скачаны.
Виноват. Ошибся. «Нашли две раздачи».
Как нашли? Я могу повторять этот вопрос долго.
Когда ползали по трекеру. Нашли две раздачи. Скачали их .torrent-файлы. Закинули их (.torrent-файлы) в клиент, который вытянул раздачи. Каждую в свою папку. Мы, по завершению загрузки, эти две папки взяли и отсортировали как нам надо. НО. У нас в первой раздаче был файл, который есть и в другой (получилось после скачивания два одинаковых файла в разных папках). Мы это спалили и при сортировке один из них удалили.
Это предыстория. Теперь мы хотим вернуться на раздачу. Запускаем программу, речь о которой в статье. Она читает эти два .torrent-файла в папке, которую мы ей скормили. И копирует файл дважды — для первого и для второго прочитанных .torrent-файлов.
Получилось дублирование файлов, что нам очень не нравится — места много не бывает. Тут как раз на помощь приходит механизм хардлинков.
Так понятней?
Это предыстория. Теперь мы хотим вернуться на раздачу. Запускаем программу, речь о которой в статье. Она читает эти два .torrent-файла в папке, которую мы ей скормили. И копирует файл дважды — для первого и для второго прочитанных .torrent-файлов.
Получилось дублирование файлов, что нам очень не нравится — места много не бывает. Тут как раз на помощь приходит механизм хардлинков.
Так понятней?
У нас в первой раздаче был файл, который есть и в другой (получилось после скачивания два одинаковых файла в разных папках). Мы это спалили и при сортировке один из них удалили.Как нашли, как палили, при пожаре никто не пострадал? Я могу представить, что идет индексация КАЖДОГО файла, сравнение хешей (и даже побайтное сравнение), но это несколько долго. Но это я представляю.
Она читает эти два .torrent-файла в папке, которую мы ей скормили. И копирует файл дважды — для первого и для второго прочитанных .torrent-файлов.А вот этого я не понимаю, ибо файлы могут начинаться с разных позиций пайса, все хеши будут другими. Внимание, как найти, что вот этот вот файл есть в обеих раздачах? КАК?
Что такое симлинки/хардлинки я прекрасно знаю, про них писать не надо.
Все движется в сторону создания хардлинков.
Ваше имя впишется золотыми буквами в книжные разделы на трекерах. И в каком то смысле добавит порядка (увеличит количество раздающих) в текущий хаос этих разделов.
С хардлинками есть проблема: я удалил файлы из коллекции (они мне больше не интересны), а место не освобождается. Может, лучше симлинки?
Для того, чтобы подобных проблем не возникало, существуют опциональные хеши и вроде бы можно иногда встретить пофайловый SHA1, хотя больше всего хотелось бы TTH.
Как видно в таблице на том же сайте, .torrent метафайлы, богатые TTH'ем, умеют создавать не все создавалки, но EAD TorrentBuild умеет. У TorrentBuild есть проблемы с иностранными символами в именах (он пишет их в ANSI), но есть open source версия, там это может быть исправлено.
Чтобы прекратить этот кошмар, желательно создавать только метафайлы, богатые TTH, а трекерам желательно ругаться на метафайлы, не богатые TTH, и предлагать пересоздать .torrent другой программой.
Как видно в таблице на том же сайте, .torrent метафайлы, богатые TTH'ем, умеют создавать не все создавалки, но EAD TorrentBuild умеет. У TorrentBuild есть проблемы с иностранными символами в именах (он пишет их в ANSI), но есть open source версия, там это может быть исправлено.
Чтобы прекратить этот кошмар, желательно создавать только метафайлы, богатые TTH, а трекерам желательно ругаться на метафайлы, не богатые TTH, и предлагать пересоздать .torrent другой программой.
Sign up to leave a comment.
Возвращаемся на раздачу или как сделать невозможное