Comments 380
но важнее всё же не как говорят, а как пишут!
важно, чтоб написано правильно было в текстах и в программах, чтоб знать точно, что имеется ввиду!
Вот приходит человек в магазин, хочет купить девушке ноутбук, и видит: игровая видеокарта, 4 ядра, 8192 человека в черном.
Хотя изначально я пошутил насчет людей в черном, но теперь, немного подумав, понимаю, что население в целом может быть и не просто приучить к «правильным» битам.
Тем более, что если бы не производители дисков — вся ВТ спокойно сидела бы на степенях двойки и не парилась.
Кстати говоря, очень интересно, почему получаются такие объёмы дисков. Вот 3 ТБ диск, 5860533168 «логических» секторов, 732566646 физических (по 4К).
732566646 = 2*3*3*3*7*1938007
должна же быть какая-то технологическая причина у такого странного множителя — 1938007?
Поэтому вместо него я пишу «рубль» (всем же понятно, рубль — это деньги такие), но при оплате снимаю эту сумму в USD.
60 MiB = 62.91456 MB (реально переданных байт). 15 процентов это 9.437184 MB.
Складываем (72.351744), умножаем на 1000 (так как Мега = 1000 Кило) и делим на 600, получается 120.6 секунд, около двух минут
Всё зависит от требуемой точности: в терабайтных (и больше) размерах, уже сложно прочитать в байтах/битах и в тоже время ошибку минимум в 10% уже нельзя просто так списать, сославшись на округление!
Кому сложно? Компьютеру?
— Я всё же прав — так как я писал эту статью по стандартам!
Вы читали мой комментарий? Какие же это стандарты, если ими не пользуются? Нужна точность — используйте байты.
не надо недооценивать стандарты — ими пользуются и будут ещё больше пользоваться со временем!
И если использовать сокращение TiB, то это придётся писать в обязательном порядке, для тех, кто ещё не знает, что такое TiB.
1<<40 это тоже самое, что 2^40 — Ti это как раз двоичные.
А 10<<40 это вообще бред сивой кобылы, извините. Сдвиг != степень. Так только с двойкой и только на наших двоичных машинах.
А 10<<40 это вообще бред сивой кобылы, извините..."
Вы считаете, что эта операция не имеет смысла? С моей точки зрения, она означает 10*(2^40), т.е. как раз число байт в 10 тибибайтах. При условии, конечно, что int у нас по меньшей мере 45-битный, чтобы не было переполнения. Но возможно, я за 25 лет работы с C так и не понял, что делает операция <<, и если так — объясните, как оно на самом деле.
байт — это минимально адресуемая единица памяти
word — в существующих реалиях — вообще непонятно что — наверное, разрядность самых частоиспользуемых регистров :-)
Например, процессоры с 36-битной архитектурой как правило имеют 9-битный байт, а в некоторых DSP от Texas Instruments байты состоят из 16 или 32 бит. Древние архитектуры могут иметь короткие байты из 4, 5 или 7 бит.
The specification cites three prefixes as follows:
kilo (K): A multiplier equal to 1024 (210).
mega (M): A multiplier equal to 1,048,576 (220 or K2, where K = 1024).
giga (G): A multiplier equal to 1,073,741,824 (230 or K3, where K = 1024).
Оперативка слава создателю пока 8Гб это 8Гб, без биби-лжи. В отличие от винтов и прочих карт-флешек.
«Литровая» бутылка молока ёмкостью 930 мл. Не, не врём, всё честно.
Этот вариант только вносит совершенно лишний хаос: непонятно какие приставки когда чего означают. Оперативка 8 ГБ, к сожалению 8 ГиБ, просто пока «ложь» в вашу пользу вы не хотите её замечать. Бодрейт, к примеру, никогда не измерялся в замаскированных под килобиты в секунду кибибитах в секунду.
Кроме того, ряд киби‐, меби‐, … идёт без дробных и промежуточных префиксов, что не нарушает целостности системы. А сам стандарт, на который вы ссылаетесь, прямо пишет вещи вроде
The definitions of kilo, giga, and mega based on powers of two are included only to reflect common usage. IEEE/ASTM SI 10-1997 states “This practice frequently leads to confusion and is deprecated.” Further confusion results from the popular use of a “megabyte” consisting of 1 024 000 bytes to define the capacity of the familiar “1.44-MB” diskette.
и
Contrast with the SI prefix mega (M) equal to 106, as in a 1-Mb/s data transfer rate, which is equal to 1 000 000 bits per second.
. Т.е. они прямо написали, что стандарт указывает такие множители только для отражения текущего способа использования. И даже привели несколько примеров когда они используются по‐другому. И ещё, там нигде нет определения тера‐ и бо́льших множителей, тогда как сейчас жёсткий диск на N ТБ довольно частое явление.
«Литровая» бутылка тут не в тему, литровой её называете вы потому что вам лениво произносить «бутылка ёмкостью 930 мл». И они честно пишут 930 мл и даже не имеют ввиду, что 1 мл = 1/1 024 л. Для того, чтобы с этим что‐то сделать нужен закон о том, что объёмы жидкостей в упаковках должны быть выбраны из указанных в законе ряда номиналов, никакое изменение определения «мили‐» или «литр» тут не поможет.
Хоть я про это и слышал давно, но как-то эти гибибайты режут ухо до сих пор. Всегда говорю гигабайт.
Зато на коробке будет заявлен объём на 20% больше реально доступного. Вот такая поправочка. :)
В среднем — 1029 кг/м³
Килограмм молока занимает 0.97л.
Это 4.85 стаканов по 200мл или 3.88 стаканов по 250мл.
Недостача составляет 30мл.
Это 6 чайных ложек или 1.5 столовых ложки.
Вполне можно понять вашу трагедию.
Спасибо за хорошую статью, зря на хабре не пишете, у вас стиль написания хороший.
Наверху посмотрел, что не прав. Пошел учить матчасть.
Во-вторых выделение поведение ПКМ, панель кнопок дисков (или вы про иную?) и шрифт прекрасно настраиваются и носятся с собой на флешке (тотал не привязан к компьютеру вообще никак).
В последнее время что-то настраиваю, только когда надоедает непривычное что-то или очень уж понадобилась какая-то настройка. В основном и с дефолтными вполне прилично можно работать более менее везде.
Понятно, что настроить можно. Но первый комментарий в ветке про необходимость всегда менять настройку. Я к тому, что Тотал от этого никак не спасает. :)
Командной строкой почти не пользуюсь, Win + R, cmd, Enter для консольки использую. В командной строке наверное чаще всего пишу точку и жму Enter, чтобы открыть проводник в текущей папке :) Поэтому у меня вместо командной строки перемещение по файлам, то есть набираешь первые буквы имени файла, а оно самое передвигается. Без всяких предварительных хоткеев (даже и не помню уже, какой хоткей по дефолту для этого).
У командной строки Тотала есть преимущество — консоль наследует права процесса-родителя. Если Тотал запущен из-под админа, то не нужно выполнять кучу телодвижений для запуска процессов с админскими правами. (Понятно, что нужно не всегда, а только при активной настройке.)
Да, и еще, почему SI? Почему не СИ?
А если серьезно, то новые размерности будут только запутывать далеких от IT людей и в разговоре все время нужно будет уточнять, что произнес. Да и в большинстве случаев в быту не так важно 1000 или 1024, поскольку все равно конечная оценка аналоговая — устраивает или не устраивает. Меня лично ни разу не напрягают эти 2.5% погрешности. Где надо, я и сам могу посчитать :)
Напомнило анекдот про блондинку (мне нравятся блондинки тоже, но так уж принято рассказывать про них анекдоты, не обижайтесь, любимые).
На вопрос «Какова вероятность встретить динозавра на улице?» блондинка отвечает — 50% — либо встречу, либо нет ;) — тоже цифровая оценка? ;)
Вообще-то нет. В OS X размер на диске как раз измеряется в СИ: Total Capacity: 121,33 GB (121 332 826 112 Bytes). А вот оперативная память почему-то в степенях двойки.

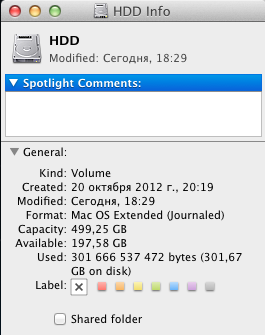
И только ретрограды старшего поколения упорствуют в применении устаревших правил.
То есть, к примеру, не мыться две недели, тоже допустимо… Но это ещё ничего не значит. ;)
> разрешено
Встал и ушел.
Подставьте в предложение выше что-нибудь явно вам знакомое. Например: «женщине разрешено надевать белое». По-вашему должно быть «женщине разрешена надевать белое» (поскольку «женщина» женского рода)?
Так что интерпретировать можно двояко.
Да и кроме того, там падеж, если предложение не безличное, творительный: разрешено быть и мужского, и среднего рода кому? Кофе.
Эээ… почему оно не безличное? Где актор? Не говоря уже о том, что «кому-чему» — это дательный падеж, а не творительный, творительный — это «кем-чем».
Ну или с другой стороны — заменим слово категории состояния на глагол, чтобы безличность была очевидна.
«Линейку разрешили использовать на экзамене» (безличное)
«Кофе разрешили быть и мужского рода» (безличное)
А теперь ваш пример… не выходит. Потому что это не слово категории состояния, а причастие прошедшего времени.
"[Министром образования] кофе разрешено быть и мужского, и среднего рода".
"[Соседом по квартире] мне разрешено воспользоваться дрелью".
Аналогия видна?
«Кофе (каково?) разрешено быть и мужского, и среднего рода».
«Линейка (какова?) разрешена быть использована на экзамене».
В прошлый раз я написал «разрешена к использованию», так что признаю, что целостность аналогии была нарушена.
Линейка разрешена быть использована на экзамене. = линейку разрешили использовать на экзамене.
Кофе разрешен быть среднего рода = (по аналогии) кофе разрешили (где глагол???) среднего рода.
Потерялось причастие. Вероятно, исходная фраза в этом формате должна звучать как-то так:
«кофе разрешен быть сущим среднего рода» (другого причастия глагола «быть» настоящего времени я не знаю).
Линейка разрешена быть использована на экзамене. = линейке разрешили использоваться на экзамене.
??? = кофе разрешили быть среднего рода.
Формат правых частей разный, matching failed…
Возможно будет проще, если я приведу аналогию на английском: «Coffee is allowed to be both of male and neuter grammatical gender».
В линейке стало «использоваться». Что случилось с кофе?
А английская фраза так и переводится безличным предложением с дательным падежом — «автомобилю разрешено перевозить пассажиров». Разве нет?
«Кофе (каково?) разрешено быть и мужского, и среднего рода».
Это неграмотно. Нельзя сказать «каково» — «разрешено быть». Попробуйте сказать «линейка разрешена использовать» (это корректная аналогия). Впрочем, сказать «линейка разрешена быть использована» тоже нельзя.
«Кофе (тв.пад.) чаю (дат.пад.) разрешено быть женского рода»…
Красивый вариант. Но всё равно используется «разрешено», независимо от рода кофе.
Насколько эти академии адекватны — другой вопрос.
При неадекватности этих механизмов получится хрень, как со французским.
При отсутствии же этих промеханизма получится хрень, как с английским.
Более того, большинство работ по лингвистике, которые я видел (извините, не профи), были написаны не под диктовку приказов, а фиксируя фактическое состояние языка и происходящие в нём изменения.
Если же мы перейдём к профессиональным сообществам (а терминология компьютеров диктуется соответствующим сообществом), то мы легко увидим, что оно так же, мягко говоря, чхать хотело на всякого рода министерства. Особенно, РФ, потому что государственная часть РФ, мягко говоря, не оказывает влияния на развитие computer science, да и не прикладные результаты R&D, тоже.
И вот мне мой опыт общения с профессионалами на работе и «так» говорит, что гигабайт — это 2<<30, а не выдумка какого-то там чинуши о том, как нам правильно говорить и писать о нашей профессии.
Я лишь писал, о том, что официально в правилах русского языка состоялись изменения (приказ лишь говорит о том что нужно использовать определенные словари), а вы тут начали всякую чушь выдумывать, о каком-то чиновнике, который от нефиг делать, взял и приказ написал…
Да и кто сказал, что это сделано по мнению одного человека, там целые институты делали новые словари — чиновники их просто утвердили.
И хочется вам (и тем сферическим носителям в вакууме) или нет, а дети уже 4-й год учатся именно по этим правилам.
Я знаю только один способ воплощения «инициативы народа», согласно действующей конституции, это общенациональный референдум. Я что-то пропустил?
www.gramota.ru/lenta/news/8_2489
Если вам хочется в это НЕ верить — никто вам не может запретить так считать.
Цитирую оттуда:
На самом деле ничего нового после приказа Минобрнауки с нормами русского языка не произошло. Как допускались только в разговорной речи варианты черное кофе и дОговор, так они допускаются только в разговорной речи и после 1 сентября. Как признавалось предпочтительным в строгом литературном употреблении черный кофе и договОр, так и признается сейчас.
www.gramota.ru/lenta/news/8_2489
«Напомним суть произошедшего. 1 сентября вступил в силу Приказ Минобрнауки России об утверждении списка грамматик, словарей и справочников. Подавляющим большинством СМИ это было подано как «вступление в силу новых норм русского языка».»
«Объявив варианты дОговор, йогУрт, брачащиеся и др. нововведениями в русском языке, журналисты тем самым расписались в неумении читать словари и незнании истории языка, а вслед за ними в том же расписались многие в нашей стране. „
“… нельзя не признать, что добротных, толковых газетных заметок и телевизионных репортажей, свидетельствовавших об искреннем желании журналистов не выдавать в эфир «сенсацию», а детально разобраться в случившемся, было меньшинство.
Сочетание «реформа языка», ставшее уже привычным жупелом, вызвало всплеск негодования в обществе, направленного как на «нехороших» лингвистов, покушающихся на грамотную речь, так и на чиновников, утвердивших «неправильные» словари. В Интернете даже начался сбор подписей в адрес министра А. А. Фурсенко с призывом отменить «новые нормы».»
«На самом деле ничего нового после приказа Минобрнауки с нормами русского языка не произошло. Как допускались только в разговорной речи варианты черное кофе и дОговор, так они допускаются только в разговорной речи и после 1 сентября.»
«А для этого, конечно, необходимо учиться читать словари и пользоваться справочниками. А еще – критически относиться к «сенсационным» новостям и лженаучным домыслам. „
На самом деле ничего нового после приказа Минобрнауки с нормами русского языка не произошло. Как допускались только в разговорной речи варианты черное кофе и дОговор, так они допускаются только в разговорной речи и после 1 сентября. Как признавалось предпочтительным в строгом литературном употреблении черный кофе и договОр, так и признается сейчас.
Я конкретно про якобы «стандарт», который якобы «Минобрнауки» якобы «приняло».
А понял, вы допускали, что Кофе и так уже было среднего рода?
И на флешке пишет «15.0GiB Removable Media»
А вот в той же консоли dd показывает именно MB. Но суффикс «k» в аргументах командной строки значит 1024. Впрочем, десятичные варианты всех двоичных суффиксов тоже есть.
Там же ls, du, df могут выводить информацию с использованием обоих вариантов, но sort использует только двоичный.
В KDE используют MiB.
Если я не ошибаюсь, пару лет назад Ubuntu перешла на СИ.
Стандарты должны быть для людей, а не люди для стандартов.
Уж не знаю, кто и почему первый применил множитель 1024, вместо 1000, но просто так изменить это не получится.
Стандарт лишь следует за сложившейся ситуацией.
Система не должна противоречить сама себе, поэтому и ввели стандарт!
Префиксы ведь от единиц измерения не зависят и их можно ставить хоть к граммам, хоть к секундам, хоть к пикселям!
Вы предлагаете сломать устоявшуюся систему исключениями?
Цель статьи: заострить внимание на том, что пора становиться грамотными и указывать правильно!
На остальные вопросы отвечено в статье.
Да, если придумаете, где нужны именно 220 пикселей, а не 1 млн. — называйте это мебипиксель. Вы соврешенно правы.
По моему вы страдаете на пустом месте. А приставка нано-онано и йотта-ёпта — не кошмар для вас? Это просто буковки, черненькие на белом. Не создавайте «кошмара» на пустом месте.
А вот то, что две величины, одинаково называющиеся (например один миллиард байт и «один терабайт»), могут отличаться на деле на 10 процентов (9,98, если занудствовать) вот это уже явный и очевидный кошмар.
Пару лет с этим столкнулся, когда в техзадании мы не проходили в заданные условиями рамки, а оказалось, просто, что пропускная способность канала была посчитана в одних величинах, а объемы передаваемых по нему данных — в других. И при этом и там и там — написаны одинаково.
В одном я постоянно покупаю, если что-то надо. Написал им в обратной связи, не исправили и не ответили.
Пришла как-то Кибиба к Мибибе и давай хныкать «не хочу быть кибибой, хочу стать гибибой». А ему Мибиба в ответ: «ничего, Кибиба, потерпи, подрастёшь, тибибой станешь».
А тут пришла Пибиба — и не стало ни Тибибы, ни Мибибы, ни Кибибы. Одна надежда на Эксибибу.
Читай: если сделать всем и всегда десятичную систему, то кто-то за это должен будет заплатить неэффективностью. Раньше 32ГиБ памяти хватало на обслуживание 3000 клиентов (включая транзакции в БД, ИО и т.д.), а после — 32ГБ начало хватать на 2000. И не потому, что 32 < 32, а потому, что страница памяти стала 4кБ (-96 байт), размер указателей стал больше (т.к. должен подстаиваться под конвертацию в 10-чную систему номеров страниц памяти), дорожек адреса стало больше, и так до самого мелкого контроллера снизу.
С учётом легаси и гонки за производительностью, эти биты в самом низу — на вес золота. Потому что поверх них столько кода накручено, что микроскопическая деградация в производительности эскалируется наружу кратно.
я же утверждаю с позиции стандарта — из-за правильного написания префикса байтов меньше не станет размеры блоков не изменятся, а просто будут правильно указываться
Ровно так же, как и совершенно типовое в ядре линукса <<PAGE_SIZE тоже отломается. Что вместо этого делать? десятичное умножение?
И сколько это будет стоить процессору (например, sandy bridge)?
Время выполнение сдвига (в любую сторону) от 1/2 до 2 тактов
Время выполнения умножения: от 1 до 3 тактов.
Время выполнения деления: от 26 до 92 тактов (!!!!)
Источник данных: gmplib.org/~tege/x86-timing.pdf
Теперь вы говорите «давайте считать всё правильно, и когда программа обращается к ядру, ядро делает page fault, то мы будем считать страницы по 4кБ размером, и будем вычислять номер страницы правильно — делением на 4000, а не сдвигом на PAGE_SIZE бит». И что мы имеем? 92 такта вместо двух на каждую операцию?
Крутая экономия в 46 раз. Так держать.
И если стандарт противоречит здравому смыслу — тем хуже для стандарта.
поэтому чтоб не указывать дроби, ввели двоичные префиксы, чтоб вместо 134,218 MB было 128 MiB
отвлекитесь от расчётов и просто прочитайте пояснение в UPD2 к статье
KiB => КиБ?
MiB => МиБ?
GiB => ГиБ?
TiB => ТиБ?
А то, писать: КiБ, МiБ, ГiБ и ТiБ — не очень удобно… да и не правильно, наверное.
1024 Киборга (КиБ) = 1 Миг (МиБ)
1024 Мигов = 1 Гибон (ГиБ)
1024 Гибонов = 1 Тибет (ТиБ)
1024 Тибета = 1 Питбуль (ПиБ)
1024 Питбуля = 1 Эйб (ЭиБ)
1024 Эйба = 1 Зибра/Зебра (ЗиБ)
1024 Зебры = 1 Ё-мобиль (ЙиБ/Yib)
PS: Прошу данный комментарий воспринимать как шутку.
В стандарте описано только английское написание, поэтому осмелюсь предположить, что в русской адаптации это было бы именно так, как вы предположили с КиБ, МиБ, ГиБ и ТиБ
net-tools 1.60-24.1ubuntu2
ifconfig 1.42 (2001-04-13)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:357744 errors:0 dropped:0 overruns:0 frame:0
TX packets:357744 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1421568124 (1.4 GB) TX bytes:1421568124 (1.4 GB)
P.S.
(аптайм всего 2 дня.)
Похоже, это дебиано-специфический патч.
Странно, что нет в убунте.
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:42840 errors:0 dropped:0 overruns:0 frame:0
TX packets:42840 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:6635704 (6.6 MB) TX bytes:6635704 (6.6 MB)
Видимо Ubuntu, окромя соблюдения странного стандарта, в этом смысла не видит.
т.е. всё в порядке и по стандарту
1024 и т.п. штуки — все происходит исключительно из организации оперативное памяти, которую радикально удобнее организовывать страницами/банками с кратными 2 размерами.
Since net-tools 1.60-4 ifconfig is printing byte counters and human readable counters with IEC 60027-2 units. So 1 KiB are 2^10 byte. Note, the numbers are truncated to one decimal (which can by quite a large error if you consider 0.1 PiB is 112.589.990.684.262 bytes :)
Возможно, в Ubuntu кто-то специально патчит это обратно.
т.е. всё в порядке и по стандарту
Прежде, чем заняться критикой и спорами, посмотрите на эти цифры: 1000GB, 100Mbit, 8GB, 512MB…
Что видят люди? Очевидно просто числа, но и понимают они их как просто числа, как некую количественную характеристику, упуская их смысловую нагрузку. Проблема в том, что им НЕВАЖНО, какая семантика в них заложена, им неважно, что некоторые из них характеризуют устройства ограниченные значениями степеней двойки, например, размер оперативной памяти. В то же время есть характеристики описывающие устройства не зависимые напрямую от значений степеней двойки, например, пропускная способность канала.
И главное — механизм. Он удивителен!
Маркетинг основан на естественном нежелании (принцип минимизации энергозатрат) людей добавлять метаинформацию в ассоциации. Это позволяет напрямую формировать устойчивые паттерны поведения, в основе которых своего рода троян — «то, что я сам для себя принял не подвергается излишней критике, в отличие от навязываемого извне». Этим пользуются, и это успешно работает, где-то в более осознанной форме, где-то в менее, но эффект очевиден.
Поэтому мы покупаем HDD на 1TB, и по той же причине мы ходим на выборы ;)
Например, никто не кричит, что обманывают, и 100Мбит сеть работает со скоростью 1E+8 бит на канальном уровне. Так же и с носителями и прочей маловажной для компьютера переферией. Байты памяти и байты IO — совсем разные байты.
Повторю: степени двойки для процессора — фактор неизбежный и вызванный оптимизацией вычислений. Оптимизацией настолько фундаментальной, что никто даже близко не начнёт её «генерализировать» (я выше привёл цифры — деление — 96 тактов, сдвиг (деление на степень двойки) — от 1/2 до 2 тактов).
Таким образом, внутри центральной части компьютера (память и процессор) счёт, кратный 1024 обусловлен технологически, и никто не будет этого менять. За пределами этого, там где оптимизация процессов не требует следовать кратности, у нас нет необходимости использовать непривычные человеку единицы измерений. Кстати, размер планок памяти вообще не обязан быть кратным 1024, достаточно быть кратным размеру строки.
Я задал этот вопрос, потому что мне интересно, в чем технологическая причина основания характеризующего емкости носителей. Мне, как пользователю было бы удобно видеть носитель емкостью 1000GiB, а не 931 GiB, так как я оперирую данными именно в системе значений выраженными двойкой в степени. Я до сих пор не вижу явных причин обуславливающих такую систему наращивания емкости. Перечитал несколько статей по низкоуровневому форматированию, но не нашел ответа.
Более того, судебное разбирательство в отношении Seagate наглядно демонстрирует тот факт, что такая метрика вносит определенные неудобства для пользователей. Собственно саму суть вопроса и затрагивает текст данной статьи.
Очевидно, что производители наращивают объем, увеличивая плотность размещения магнитных доменов целенаправленно с учетом типичных и удобных значений емкостей (на это должны быть объективные причины): 250, 500, 1000, 1500, 2000, 3000 (GB),… но не 371.456, 683.97, 954, 1739 (GB)…
Почему? Что мешает делать диски таким объемом, чтобы у целевой аудитории (обычных пользователей) не возникало неудобств с пересчетом из TB в GiB?
P.S. Мы с вами можем по большому счету и не задумываться над этим, но проблема недопонимания у абсолютного большинства людей имеет место быть.
Теперь вопрос: почему все остальные должны следовать этому?
Ответ на «почему?» очень простой. Потому что они сделали диск, который чуть больше, чем 250 миллиардов (300 и т.д.) байт форматированной ёмкости.
2. Вы, вероятно, так и не поняли на что именно я акцентировал внимание. Уж простите меня великодушно, если я не совсем лаконично выражаю свои мысли. Я постарался задать вопрос дважды и дважды увидел ответы, взгляните сами:
— Что технологически мешает созданию HDD емкостью 1 TiB, вместо 1TB?
— " не мешает. но и не помогает"
— Почему? Что мешает делать диски таким объемом, чтобы у целевой аудитории (обычных пользователей) не возникало неудобств с пересчетом из TB в GiB?
— «Потому что они сделали диск, который чуть больше, чем 250 миллиардов (300 и т.д.) байт форматированной ёмкости»
Если вы не совсем поняли о чем я, я попробую в третий раз — Почему «они сделали» диск, который «чуть больше, чем 250 миллиардов байт форматированной емкости», но при этом продолжают делать такие диски, что их объем всегда выражен в целом числе GB, а не GiB. Почему производители делают пластины емкостями по 500GB, а не 500GiB? Что мешает, какие могут быть проблемы технологического уровня и почему существует определенная кратность 250, 320, 500, 750, 1000 (GB)…? Очевидно же, что это целенаправленный подход в производстве, который привносит путаницу в потребительском секторе. Я не зря привел в пример ситуацию с судебным разбирательством, причем производитель суд проиграл в пользу потребителей.
3. Почему все остальные должны следовать этому?
Они не должны, просто, на мой взгляд, очевидно, что, допустим, моему отцу, который покупает себе жесткий диск значительно удобнее оперировать понятием GB = GiB, так как он, как потребитель не связанный напрямую с разницей в метриках, руководствуется при покупке логикой что 1000GB — это то, что мы называем 1000 GiB.
4. Я за права и ожидания потребителей. Я не имею ничего против стандартов, но я не понимаю, что мешает сделать HDD с емкостями в эквивалентных значениях GiB, а не GB.
Не принимайте близко, это не критика, это мое любопытство!
С уважением.
потому что очень понравилось примерное употребление GB, GiB, TB, TiB!
только ради того, чтоб увидеть такую красоту стоило написать такую статью :) ч.т.д.
спасибо
Например, цитата из справочника 1996-ого года:
«В состав серии К565 входят микросхемы с информационной емкостью 4K, 16K, 64K и 256K.»
Так, например, друг недавно возмущался, почему у него в тарифном плане заявлена скорость 50 Мегабит/с его торрент клиент тянет файлы с внешки с максимальной скоростью в 6 Мегабит/с. А всё оказалось просто, оказывается он просто не знал, что скорость может измеряться ещё и мегабайтами в секунду.
Может тут это для всех прописная истина, но я вот заметил, что довольно многие ещё об этом не знают.
Но мегабайт как 1024^2 используется не поэтому. Сила привычки и обратная совместимость. Однажды ошиблись и прижилось. Проще продолжать, чем объяснять идиотам что за разница возникла. Бурление говн будет небось сопоставимо с пропавшей кнопкой «пуск».

{kind=link}
В-третьих, неправильное использование величин, может привести к очень дорогим последствиям:
В этом случае NASA потеряла зонд Mars Orbiter стоимостью 125 MUSD (=119,2 MiUSD) в сентябре 1999 года именно из-за проблем в использовании правильных единиц измерения!
Вообще ваш тезис непонятен. Что значит правильная единица измерения? Дело не в «правильности», а в том, что из-за раздолбайства они заранее не договорились о системе единиц. И проблема, насколько я помню, была не в том кто и что использовал, а в том, что величины в какой-то момент неверно друг между другом конвертировались.
«правильных единиц измерения» — я имел ввиду тех же самых, которые использовала другая команда и для них они были правильными; но для другой команды программистов «правильные» единицы измерения были совсем другие!
т.е. тоже самое теоретически могло бы случиться если бы одна команда работала с МБ по основанию 1000, а другая с МБ по основанию 1024
Много думал, из ВУЗа ушёл со словами «Закапывайте»
Проблемы начались потом, когда не очень дружные со стандартами люди стали путать такие единицы измерения, как К и КБ. Ну а другие люди стали этим пользоваться.
К слову сказать, производители оперативной памяти руководствуются по-старинке степенями двойки, в отличие от производителей дисков. И у них есть свой стандарт на эту тематику — en.wikipedia.org/wiki/JEDEC_memory_standards
Ну и напоследок. В ГОСТ 8.417-2002 в приложении А указано дословно следующее:
Исторически сложилась такая ситуация, что с наименованием «байт» некорректно (вместо 1000 = 103 принято 1024 = 210) использовали (и используют) приставки СИ: 1 Кбайт = 1024 байт, 1 Мбайт = 1024 Кбайт, 1 Гбайт = 1024 Мбайт и т.д. При этом обозначение Кбайт начинают с прописной буквы в отличие от строчной буквы «к» для обозначения множителя 103.
Что вполне можно интерпретировать, как допустимость использования таких едениц как ГБ в значении ГиБ.
А про ваше негодование «а как же стандарт»… Ну вот мощность по науке измеряется ваттами, однако «лошадиная сила» никуда не делась и вряд ли денется, хотя это вообще внесистемная единица.
Посмотрите на сокращённую запись: KiB, Kibit, MiB, Mibit, GiB, Gibit, TiB. Подумалось тут, может быть стоило бы по-русски читать буквально: кибайты, кибиты, мибайты, мибиты, гибайты, гибиты, тибайты :) Не во всех случаях звучит хорошо, но мне кажется, что всё-таки немного лучше, чем в оригинале :)
Не помню откуда и как, но я разобрался что 250Гб = 250 000 000 000 байт, а не 268 435 456 000 байт чтобы в итоге получилось красивое «250Гб».
Чтобы в дальнейшем не морочить себе голову таким «обманом», нашел коэффициент такой погрешности — как раз 0,93 (что видно из таблицы в топике). Потом тупо брал «рекламный размер» и умножал на 0,93 — и знал что я увижу в windows.
Это нормально, что жаргон не всегда понятен остальным, на то он и профессиональный. И кратные приставки давно уже стали частью профессионального жаргона компьютерщиков, которые прекрасно понимают, чем «кило» отличается в килобайте и километре.
Во-вторых, приставка «кило» широко используется в отраслях, напрямую не связанных с компьютерами (в частности, «килограмм» — это основная единица СИ, хотя по строению — кратная, образованная от «грамма»). А вот приставки «мега» и уж тем более «гига» и ещё более кратные — практически никем, кроме компьютерщиков, не используются. Я с ходу не смог вспомнить примеров, чтобы звучали слова «мега-что-то», «гига-что-то», и «что-то» не было бы «байтом». Никто никогда не говорит «мегаметр», «мегаграмм», «гигаампер», «теравольт» и «терарубль».
Фактически сложилось так, что приставки «мега», «гига» и старшие фактически используют только компьютерщики, причём традиционно в значении «ещё десять порядков двойки». И вместо того, чтобы закрепить это традиционное значение, в котором их применяет единственная группа пользователей, этот ваш стандарт предлагает переучить эту единственную группу, в угоду всем остальным, которым эти приставки вообще не нужны и которые толком даже не знают, что бывают приставки «тера» и «пета», не говоря про «экса» и далее.
В третьих, система «СИ» — это стандарт «теоретически». На практике используется довольно редко, т.к. она не является удобной в большинстве прикладных задач.
В быту мы электроэнергию измеряем в киловатт-часах, а не в джоулях; мощность бесперебойников указывают в вольамперах, а не в ваттах; расход воды и газа — в кубометрах, а не в литрах и не в килограммах, температуру — в градусах Цельсия, а не в Кельвинах.
Математикам единицы измерения не нужны.
Физики используют всегда естественные единицы измерения, характерные для данной задачи, такие, как электронвольт, боровский радиус, магнетон Бора, постоянная Планка. В КЭД используется система единиц «h=e=c=1», так формулы получаются гораздо проще — все эти коэффициенты просто можно не писать, меньше шансов ошибиться. В классических электродинамических задачах принято использовать систему единиц Гаусса — в ней тоже пропадают коэффициенты (и нет идиотского понятия «диэлектрическая проницаемость вакуума», которое пришлось ввести в СИ, чтобы согласовать в ней единицы, выбранные неестественным образом).
Химики тоже часто используют свои удобные естественные единицы, такие как объёмные проценты и тому подобное.
А вообще мне кажется у физиков скорее всего половина произносимых слов будут с приставками «мега» «кило» «гига» и пр.
мегавольты по-моему только в мультфильмах есть. Там пофигу, что конкретно означает приставка, главное, что много :)
на практике физики реально не используют такие единицы. В естественной системе единиц задачи получаются куда более удобные для человека величины, а если уж нужно указать именно огромное число — так и пишут что-то вроде 5.34321 * 10^15, без приставок.
Приставка пико-, кстати, тоже встречается нередко (хотя она с другой стороны). Вот фемтосекундами приходилось оперировать только несколько раз, пока и пикосекунд хватает.
хотя опять же они используются не с единицами СИ, как в «гигакалориях» и «мегатоннах»
А про дольные приставки я и не говорил — они в информатике по сути бессмысленны, так как хотя в теории и встречаются «дробные биты», на практике их нет.
Я против форса СИ как таковой — она мне напоминает тот самый «пятнадцатый стандарт» из анекдота про разработку нового стандарта.
Хотя…
Сверкающая дуга фарфора на металле была разделена тонкими черточками на Столетия, Децистолетия и Сантистолетия
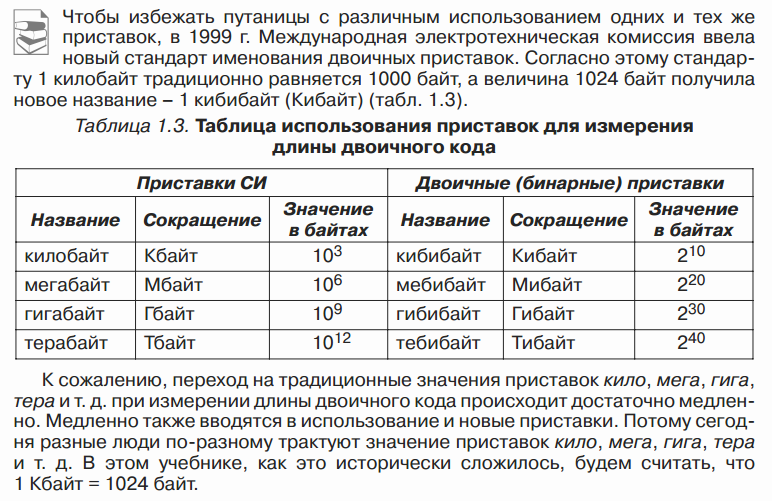
Может быть в других учебниках так же и все школьники уже давно в курсе, что такое Кибайты и т.д.? :)
Вот Вы когда энергетику собираетесь переводить на двоичную систему счисления? АЭС, например?
Я вот как-то привык, что в километре 1000 метров…
Я понимаю, что я старенький и мне пора на кладбище, но не можете ли Вы немного подождать с такими радикальными предложениями?
С 0-го нуляля 0x800-го года :)
А в километре будет 1073741824 микрон… Или, еще лучше, 1/262144 световой секунды.
Кстати, движение Земли вокруг Солнца придется слегка замедлить, чтобы в году стало 32 мебисекунды.
Правильный вопрос — не «когда», а «зачем». Лично я не вижу причин для этого. А речь вообще идёт о измерении объёмов компьютерной информации.
Для обозначения 2^10=1024 байт изначально использовали единицу «К» (ка, очевидно, искажённое «кило»).
А в российском ГОСТе 8.417-2002 («Единицы величин») в «Приложении А» констатируется факт, что с наименованием «байт» «стандартные» приставки (обозначающие десятичные кратные единицы) используются некорректно, однако, не предлагается никакой альтернативы. Кроме, разве что, обозначения 1 Кбайт = 1024 байт (в отличие от 1 кбайт = 1000 байт).
Не знаю, хорошо это или плохо, но время расставит всё по местам.
Есть же ворды в нашем лэнгвидже, которые дискрайбят зе сейм?
Давайте НЕ будем использовать надуманных мертворожденных стандартов, пусть они даже и от Международной Электротехнической Комиссии родом. Рождены они исключительно для потакания вранью маркетоидов в их рекламном булшите и не имеют ни какой практической пользы.
Кило- мегабайты использовались (и используются) в 1024-ичном значении задолго до вашего рождения и все, кто использовал эти еденицы были в курсе и не испытывали неудобств. Ваша забота о мамах-бабушках трогательна, но мама-бабушкам на самом деле совершенно безразлично сколько байтов в килобайте вся «проблема» состоит в несоответствии цифирек на наклейке винчестера реальным цифрам. Вот она причина! А приставки-стандарты — это лишь следствие. Единственно-разумным решением во всей этой глупой истории было с самого начала заехать по наглой рыжей морде брехливым рекламистам производителей устройств хранения и не было бы ни головняка с безумными префиксами, да и бабушки спали бы спокойно. К сожалению, момент упущен :(. Остаётся только игнорировать этот дебилизм и надеяться, что бабушки не будут принимать враньё рекламщиков так близко к сердцу.
1. В словосочетании КИЛОБАЙТ, КИЛОБИТ уже есть ссылка на то, что измеряется количество информации.
2. Все должно быть в едином стандарте. Я не хочу пересчитывать, сколько документов, размером 1 «гебибайт», уместится на диске, размером 1 «теробайтбайт». (931)
3. То что все операционные системы врут — в корне не верно. Они не пользуются этим идиотским стандартом, это их право. Общепринятый стандарт(я считаю в нем с 1998 года) — 1KB это 1024B. А вот маркетологи, рожей их об асфальт, нашли «удачную» лазейку.
4. если я правильно понял, в ГОСТ 8.417—2002 указано:
«Исторически сложилась такая ситуация, что с наименованием «байт» некорректно (вместо 1000 = 10^3 принято 1024 = 2^10) использовали (и используют) приставки СИ: 1 Кбайт = 1024 байт, 1 Мбайт = 1024 Кбайт, 1 Гбайт = 1024 Мбайт и т. д. При этом обозначение Кбайт начинают с прописной буквы в отличие от строчной буквы «к» для обозначения множителя 10^3.»
PS: Если у Apple на коробке написано 2TB винт, а замечательная ОС показывает меньше — их можно попробовать засудить.
Хоть я и айтишник, но когда я вижу такую картину:

Не знаю как вам, а мне так и хочется сказать: 276 мегабайт, 564 мегабайта, 745 мегабайт и т. д. Проходит доля секунды, и тут я вспоминаю о 1024 и понимаю, что неплохо было бы «пересчитать». Запускается калькулятор, и получается 263 мегабайта, 538 мегабайт и 711 мегабайт — совсем другие цифры. А ведь из записи 276 517 019 при предлагаемом подходе мы можем легко прочитать размер не только в мегабайтах, но и в килобайтах, если это необходимо.
Почему бы и нет. Получится с небольшим запасом. Для большинства практических целей вполне годно. А вот точное значение скорее менее годное — при записи на устройство придётся учитывать «хвосты».
>А ведь из записи 276 517 019 при предлагаемом подходе мы можем легко прочитать размер не только в мегабайтах, но и в килобайтах
$ ls -gG
-rw-r--r-- 1 161201 дек. 14 2011 tvnjviewer-2.1-src.zip
$ ls -gGh
-rw-r--r-- 1 158K дек. 14 2011 tvnjviewer-2.1-src.zip
ни какого мошенства
И, даже если внезапно захотелось стандарта
$ ls -gGh --si
-rw-r--r-- 1 162k дек. 14 2011 tvnjviewer-2.1-src.zip
Расхождение же из-за адресации памяти возникло, информация памятью измерялась еще до того, как устройства долговременного хранения возникли.
Конечному пользователю будет конечно же удобнее считать свои файлы, но каково будет разработчикам? Всякие размеры кэша, буферов, порций данных, всё внезапно станет состоять из нецелых цифр.
И если с жесткими дисками как то еще можно понять — как разметили, так и будет, то теперь в моду входят ССД диски, они же тоже на память делятся, полмикросхемы для ровного счета не впаяешь.
Очень хочется подарить вам инвайт. Если вы заинтересованы — дайте знать.
IEC60027-2: Давайте использовать стандарты, или 1024 B == 1 KiB && 1024 B != 1 KB && 1000 B == 1 kB