
Привет, Хабр! Вдохновившись последними достижениями в области прикладного ИИ и личных помощников (Siri, Google Now и им подобные), я решил написать под себя помощника, пусть и не такого продвинутого как коммерческие аналоги, зато со
Знакомьтесь, Сузи

Главная изюминка моего псевдо-ИИ заключается в очень простой реализации и быстром обучении большому количеству фраз. Достигается это следующим образом:
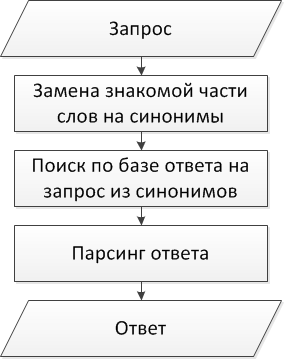
Логика Сузи
В папке с исполняемым файлом есть (на данный момент) три файла: sinonims.txt, faq.txt, и phrases.txt. Они заполняются мною, в дальнейшем планирую добавить функцию заполнения голосом и/или какое ни будь подобие самообучения.
sinonims.txt
— база исходных слов их заменпривет=hi
здравствуй=hi
хай=hi
…
дела=state
жизнь=state
...
faq.txt
— база вопрос-ответ. Ответ может содержать текст, команду или переменную*hi*={&hi}, {%name}
*как*state*={&state}
…
*off*debug*={@dbg0}{&ok}
В правой части содержится маска, под которую подставляется текст с синонимами, в левой ответ. Спец символы "@", "%" и "&" указывают на то, что нужно вставить вместо конструкции — команду, переменную или фразу соответственно.
phrases.txt
— база частых фраз в нескольких вариантахhi1=здравствуйте
hi2=приветствую
…
state1=хорошо
state2=нормально
state3=все в норме
...
Если есть желание по заполнять базы — пишите в комментариях, я выложу базы, исходники, exeшник.
Пример обработки запроса
Исходный текст: привет, как дела -> Очищаем строку, заменяем синонимы по словарю: hi как state -> Смотрим под какие маски он попадает: *hi* и *как*state* -> Парсим ответ: заменяем {&hi} и {&state} случайным образом на варианты, присутствующие в базе фраз, а {%name} на переменную curusr -> Результат: приветствую, Сэр все в норме (Вы, наверное, могли подумать, что Сузи не очень грамотная, но грамотность ей не нужна, в моих планах прикрутить к ней распознавание речи и TTS, а в этом случае ей не понадобится ставить знаки препинания и писать слова с заглавных букв)

Внутренности Сузи
Процедура инициализации
procedure init;
var
path: string;
begin
canspeak := true;
path := extractfilepath(application.ExeName) + '\brains\'; //Путь к базам
faq := tstringlist.Create; // Создание и загрузка массивов данных
words := tstringlist.Create;
words.LoadFromFile(path + 'phrases.txt');
faq.LoadFromFile(path + 'faq.txt');
sins := tstringlist.Create;
sins.LoadFromFile(path + 'sinonims.txt');
curusr := 'dysha'; // Текущий пользователь
name := sino(curusr); // Имя из логина по базе синонимов
say('Инициализация завершена');
say('Моя база знаний на данный момент позволяет распознавать ' +
inttostr(faq.Count * sins.Count) + ' выражений и выводить ' +
inttostr(faq.Count * words.Count));
end;
Процедура парсинга
procedure parce(s: string);
var
p, o, i, t, i1: Integer;
t1: string;
str: tstringlist;
begin
str := tstringlist.Create;
said := false;
s := ansilowercase(s); // Очистка строки
trim(s);
stringtowords(s, str);
s := '';
for i := 0 to str.Count - 1 do // Цикл замены слов на синонимы
s := s + sino(str[i]) + ' ';
delete(s, length(s), 1);
s := answ(s); // Парсинг синонимов на предмет команд или переменных, они там встречаются, например, я={%cname}
d(s); // Отладочный вывод
tparce := s;
rootcmdparce; // Поиск в тексте внутренних команд
faqparce; // Поиск ответа по маске
end;
Остальную часть кода я приводить не стал так как
Заключение
Планов относительно Сузи у меня много, я хочу добавить к ней распознавание и синтезирование речи (но это занятие долгое, а времени мало — сессия, студенты и им сочувствующие поймут), возможность запоминать то, что говорит оператор, анализировать это, сохранять напоминания, заметки. Всю эту систему я хочу поставить на отдельную машину, благо на даче их валяется куча, прикрутить хорошую колонку к ней, микрофон, датчик движения, релешки через com-порт, чтоб я мог зайти в комнату и сказать: «Сузи, закрой дверь, вруби кондиционер и поставь мою любимую песню» или что то в этом роде… Ах, как это круто, черт побери.
Пока искал картинку для топика, наткнулся на это, кто знает, тот поймет.

UPD
Выкладываю исходники с exeшником: docs.google.com/file/d/0B1vVuifL615WVzNmQllOUGEwd00/edit?usp=sharing. Если найдутся те, кто до заполнит базы, буду очень благодарен, если Вы мне их скинете. За возможное наличие быдлокода прошу понять и простить.
