Сегодня (прим. переводчика: т.е. 6 лет назад) я перебирал список List, используя конструкцию foreach, и чувствуя небольшое самодовольство, осознавая насколько это производительнее, того что было бы, попытайся я использовать ArrayList. Благодаря чуду Generic компилятор C# аккуратно избегает многочисленные упаковочные операции с помощью экземпляров
System.Collections.Generic.IEnumerator вместо старых System.Collections.IEnumerator. Тогда я подумал: "действительно ли это самый быстрый способ?" По результатам расследования, получается, что, нет, это не самый быстрый способ.
NET Framework 2.0 (прим. переводчика: да, статья старая) полон маленьких вкусняшек, которые делают жизнь легче, а код элегантнее. Среди моих любимых, дополнительные методы для массивов и списков, такие как Action, Converter<TInput,TOutput> и Predicate, которые принимают создаваемые делегаты. Судя по всему, я одержим ими. Эти методы действительно сияют, когда используются с анонимными методами и лямбда выражениями. В частности, я заинтересовался методом List.ForEach(Action). Я захотел узнать, ForEach медленнее, быстрее или примерно такой же по производительности как и стандартный Foreach?
Рассмотрим этот код:
long Sum(List<int> intList)
{
long result = 0;
foreach (int i in intList)
result += i;
return result;
}
Компилятор C# будет генерировать IL инструкцию для приведенного выше кода, который транслируется примерно так:
long Sum(List<int> intList)
{
long result = 0;
List<T>.Enumerator enumerator = intList.GetEnumerator();
try
{
while (enumerator.MoveNext())
{
int i = enumerator.Current;
result += i;
}
}
finally
{
enumerator.Dispose();
}
return result;
}
По сути, компилятор C # генерирует два вызываемых метода за одну итерацию: IEnumerator .MoveNext () и IEnumerator .Current. Использование структуры List.Enumerator (которая реализует IEnumerator) позволяет компилятору генерировать вызываемые IL инструкции вместо callvirt, чтобы обеспечить крошечный прирост скорости на нижнем уровне.
Для разнообразия, рассмотрим этот код:
long Sum(List<int> intList)
{
long result = 0;
intList.ForEach(delegate(int i) { result += i; });
result result;
}
Или тот же код, на использующий лямбда выражения:
long Sum(List<int> intList)
{
long result = 0;
intList.ForEach(i => result += i);
return result;
}
В результате, используя List.ForEach создаётся только один метод за итерацию, где Action<Т> любой делегат, который вы предоставляете. Он будет вызывать callvirt IL инструкцию, но два вызова медленнее, чем один callvirt. Итак, я ожидаю, что List.ForEach на самом деле будет быстрее.
Вооруженный моим предположениям, я создал небольшое консольного приложения, которое замеряло время суммирования всех элементов списка List для четырёх различных способов перебора:
- for (int i = 0; i < List.Count; i++)
for (int i = 0; i < NUM_ITEMS; i++)
foreach (int i in List)
List.ForEach(delegate(int i) { result += i; });
Первые, результаты я сгенерировал без оптимизации компилятора:
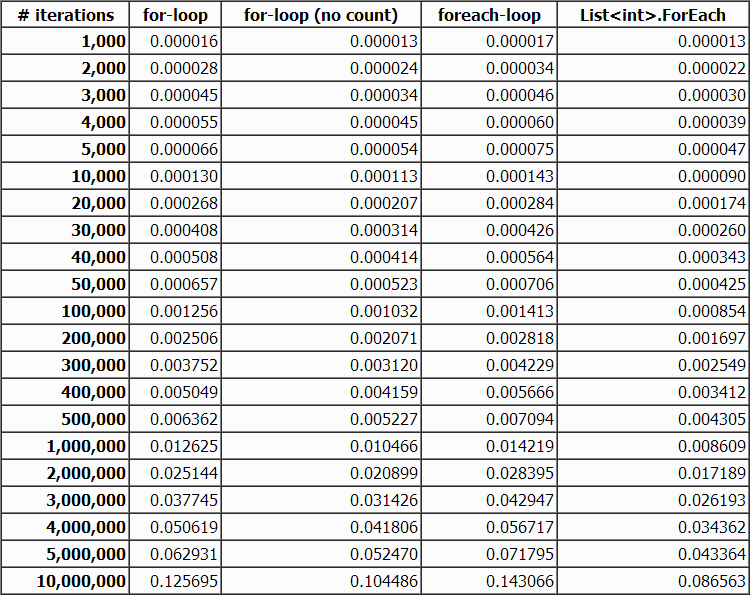
Эти результаты невероятны. Оказывается, что без оптимизации, List.ForEach даже быстрее, чем стандартные конструкции! Не меньший интерес представляет, что (без оптимизации компилятора) Foreach почти так же быстр, как стандартные циклы. Итак, если вы собираете приложение, без оптимизации компилятора, то List.ForEach является самым быстрым методом.
Далее, я прогнал мои тесты с поддержкой оптимизации компилятора, чтобы получить результаты приближенные к "реальному миру":

Глядя на эти цифры, я находился под впечатлен от того, как эффективно компилятор оптимизирует циклы, чтобы получить более, чем 50% экономии. ForEach-петлям также удалось урезать около 20%. List.ForEach не оптимизируется так хорошо, но главное, что он по-прежнему обгоняет Foreach-петли со значительным отрывом. List.ForEach быстрее, чем стандартный Foreach.
Замечу, что эти тесты проводились на ноутбуке Dell Inspiron 9400 с Core Duo T2400 и 2 Гб оперативной памяти. Если вы хотите прогнать эти тесты у себя, вы можете скачать консольное приложение здесь: ForEachTest.zip (3,82 Кб).
И так как одна картинка стоит тысячи слов, я создал пару графиков, чтобы продемонстрировать различия в скорости тестов. На графиках показано 5 различных образцов, позволяющие перебирать 10000000 в 50000000 целых значений.
Без оптимизации компилятора:
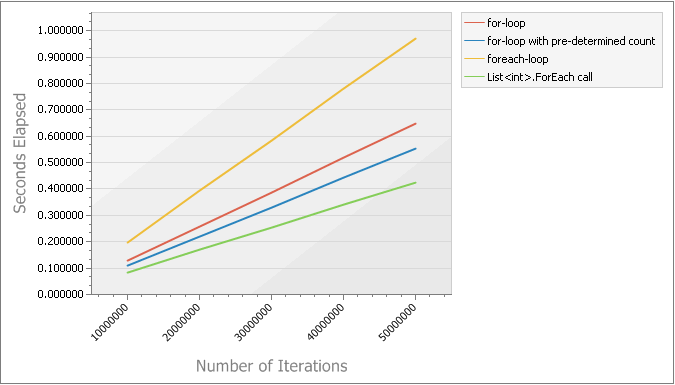
С оптимизацией компилятора:

И наконец: в то время как метод ForEach намного быстрее для перебора List, это не применимо для случаев с массивами. Метод Array.ForEach существует для одномерных массивов (или векторов) и он на самом деле медленнее, чем используемый стандартный foreach. Причина в том, что компилятор не генерирует код, использующий IEnumerator для foreach-петель через векторы. Вместо этого, он генерирует специальные инструкции IL, которые предназначены для работы с векторами. Таким образом, используя foreach на векторах, методы в итоге не вызываются, в то время как Array.ForEach еще требует один вызов для предоставленного делегата.
Примечание переводчика:
Т.к. для написания скриптов на Unity3D я использую C#, то я не смог устоять от соблазна проверки описанных выводов на практике. Я написал небольшой скрипт
using UnityEngine;
using System.Collections;
using System.Collections.Generic;
public class testspeed : MonoBehaviour {
public enum LoopType {none, for_loop, for_loop_no_count, foreach_loop, ListintForEach}
public LoopType type;
public int Count=2;
public int iterationCount=1000;
private List<int> lint = new List<int>();
private int[] alint;
private long result;
void Start () {
for (int i = 0 ; i<Count; i++) {int r=UnityEngine.Random.Range(0,1000); lint.Add(r);}
}
void Update () {
for (int j =0; j<iterationCount;j++)
{
result=0;
switch (type)
{
case LoopType.for_loop: for (int i = 0; i < lint.Count; i++) {result += lint[i];} break;
case LoopType.for_loop_no_count: for (int i = 0; i < Count; i++){result += lint[i];} break;
case LoopType.foreach_loop: foreach (int i in lint) {result += i;} break;
case LoopType.ListintForEach: lint.ForEach(i => result += i); break;
}
}
}
}
В результате, я заметил одно лукавство в приведённых выше данных, заключающееся в том, что нижней границей для таблицы выбрано 1000 членов списка. Если список содержит в себе больше 1000 элементов, то всё вышеописанное верно. Но у меня на практике такое такое встречается не часто, обычно список ограничивается десятками, ну может сотнями элементов.
Поэтому я привожу свою таблицу:
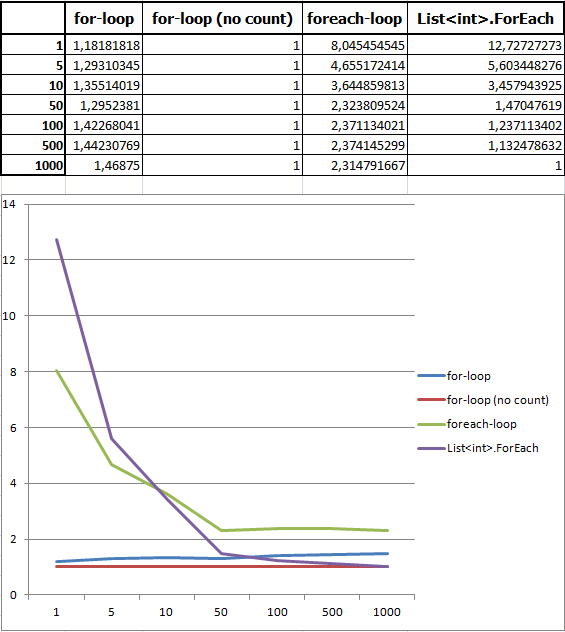
Как видно, для небольших списков лучше всего использовать стандартный цикл с внешним счётчиком. По производительности ForEach проигрывает ему в разы.
