
Фото: Александр Корольков/РГ
3 июня, в заключительный день Московского книжного фестиваля на Красной площади, лингвист Александр Пиперски выступал с рассказом о компьютерной лингвистике. Он говорил о машинных переводах, нейросетях, векторном отображении слов и поднимал вопросы границ искусственного интеллекта.
Лекцию слушали разные люди. Справа от меня, например, клевала носом китайская туристка. Александр, наверняка, тоже понимал — пара лишних цифр, формул и слов об алгоритмах, и люди убегут в соседнюю палатку слушать фантастов.
Я попросил Александра подготовить для Хабра «режиссерскую версию» лекции, где не вырезано ничего, что может усыпить случайных туристов. Ведь больше всего выступлению не хватало аудитории с толковыми вопросами и вообще хорошей дискуссии. Думаю, здесь мы ее сможем развить.
Где начинается ИИ
C недавних пор мы постоянно общаемся с компьютерами голосом, а всякие Алиса, Алекса и Сири голосом нам отвечают. Если посмотреть со стороны, кажется, что компьютер нас понимает, выдает списки релевантных сайтов, сообщает адрес ближайшего ресторана, указывает, как к нему пройти.
Похоже, мы имеем дело с довольно умным устройством. Можно даже сказать, это устройство обладает тем, что называется искусственный интеллект (ИИ). Хоть никто толком не понимает, что это значит и где проходят границы.
Когда нам говорят «ИИ выполняет творческие функции, которые считаются прерогативой человека» — что это значит? Что такое творческие функции? Какая функция творческая, а какая нет? Подбор ближайшего китайского ресторана — творческая функция? Сейчас кажется, что скорее нет.
Мы постоянно склонны отказывать компьютеру в искусственном интеллекте. Как только мы привыкли к интеллектуальным проявлениям, которые делает компьютер, мы говорим, «это не ИИ, это полная ерунда, шаблонные задачи, ничего интересного».
Простой пример — с нашей точки зрения нет ничего тупее карманного калькулятора. Он продается в любом ларьке за 50 рублей. Возьмите обычный восьмиразрядный калькулятор, потыкайте на кнопочки и получите результат в считанные секунды. Ну подумаешь, считает какие-то вещи. Это же не интеллект.
А представьте себе такую машинку в XVIII веке. Она казалась бы чудом, потому что вычисление было прерогативой человека.
Так же происходит и с компьютерной лингвистикой. Мы склонны презирать все ее достижения. Я ввожу в Google запрос «стихи Пушкина», он находит страницу на которой написано «А.С. Пушкин — Стихотворения». Казалось бы, что такого? Совершенно нормальное поведение. Но компьютерным лингвистам пришлось потратить десятки лет, чтобы по слову стихи находилось слово стихотворение, чтобы по слову Пушкина находилось слово Пушкин и не находилось Пушки.
Компьютерные шахматы и машинные переводы
Компьютерная лингвистика зародилась одновременно с компьютерными шахматами — а ведь шахматы когда-то тоже были прерогативой человека. Клод Шеннон, один из основоположников информатики, в 1950 году написал статью, как запрограммировать компьютер, чтобы он играл в шахматы. По его словам, мы можем выработать два типа стратегий.
A — с полным перебором продолжений. Надо тестировать все возможные ходы на каждом этапе.
B — перебирать только те продолжения, которые оцениваются как перспективные.
Человек, очевидно, использует стратегию B. Гроссмейстер, скорее всего, перебирает только разумные на его взгляд варианты, и за довольно быстрое время выдает хороший ход.
Стратегия A сложна для реализации. По подсчету Шеннона, чтобы просчитать три хода, надо перебрать 109 вариантов, и если позиция оценивается в одну микросекунду (что было сверхоптимистично в середине XX века), то на один ход понадобится 17 минут. А три хода вперед — это ничтожная глубина предсказания.
Вся дальнейшая история шахмат состоит в разработке приемов, которые позволят не перебирать все подряд, а понять — что надо перебирать, а что не надо. И победа над человеком уже достигнута, окончательно и бесповоротно. Компьютер обошел чемпиона мира по шахматам лет 20 назад, и с тех пор только совершенствуется.
Лучшей программа считалась Stockfish. В прошлом году с ней сыграла 100 партий программа AlphaZero.
| Белые | Черные | Победа белых | Ничья | Победа черных |
|---|---|---|---|---|
| AlphaZero | Stockfish | 25 | 25 | 0 |
| Stockfish | AlphaZero | 0 | 47 | 3 |
AlphaZero — это искусственная нейронная сеть, которая просто четыре часа играла в шахматы сама с собой. И научилась играть лучше, чем все программы до нее.
Похожее происходит в компьютерной лингвистике сейчас — всплеск нейросетевого моделирования. Над машинными шахматами начали работать одновременно с машинными переводами — в середине прошлого века. С тех пор выделяют три этапа развития.
— Машинный перевод на основе правил
Он устроен очень просто — примерно как на уроках грамматики, компьютер выделяет подлежащее, сказуемое, дополнение. Понимает, какими словами все это переводится на другой язык, узнает, как там выражать подлежащие, сказуемые, дополнения, и все.
Такой перевод развивался лет 30, не имея больших успехов.
— Статистический (фразовый) перевод
Компьютер опирается на большую базу данных текстов, переведенных человеком. Подбирает в ней слова и словосочетания, которые соответствуют словам и словосочетаниям оригинала, собирает их в предложения на языке перевода и выдает результат.
Когда в интернете пишут про очередные “20 самых тупых машинных переводов” — скорее всего, речь именно про фразовый перевод. Хотя он и достиг некоторых успехов.
— Нейросетевой перевод
Про него будем говорить подробнее. Он вошел в массовое использование буквально на наших глазах: Гугл включил нейросетевой перевод в конце 2016 года. Для русского он появился в марте 2017. Яндекс запустил в конце 2017 года гибридную систему основанную на нейросетях и статистике.
Нейросети
Нейросетевой перевод основан на такой идее: если математически смоделировать и воспроизвести работу нейронов в голове человека, то можно предположить, что и компьютер научится работать с языком так же, как человек.
Для этого взглянем на клетки в мозгу человека.
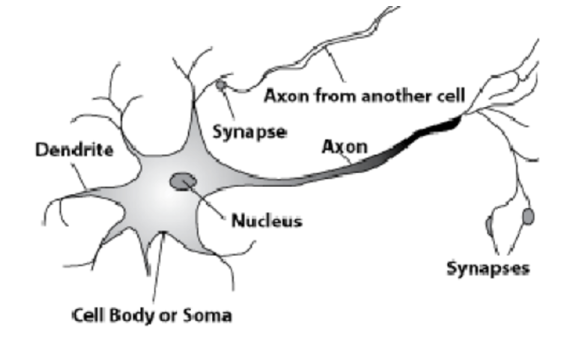
Вот естественный нейрон. От ядра отходит длинный отросток — аксон. Он крепится к отросткам из других клеток — синапсам. По аксонам в синапсы клетки клетки передают информацию о некоторых электрохимических процессах. Из каждой клетки выходит только один аксон, а синапсов может входить много. Сигналы распространяются, и так происходит передача информации.
Некоторые клетки связаны с внешним миром. Они получают сигналы, которые дальше обрабатываются нейронной сетью.
А вот простейшая математическая модель того, что мы можем здесь сделать. Я нарисовал девять связанных кружочков. Это нейроны.
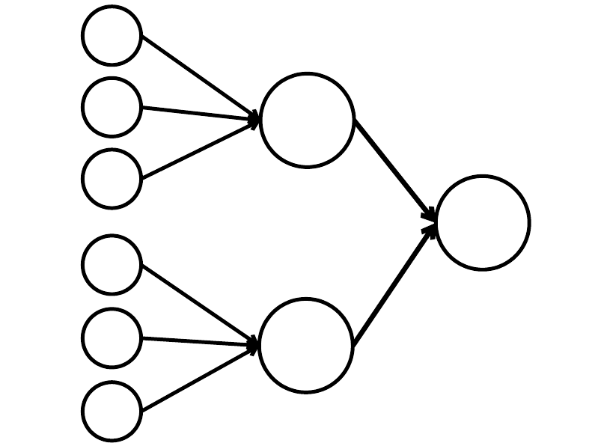
Шесть нейронов слева — входной слой, который получает сигнал от внешней среды. Нейроны второго и третьего слоя не соприкасаются с окружающей средой, а только с другими нейронами. Введем правило — если в нейрон входят по крайней мере две стрелочки от активированных нейронов, то этот нейрон тоже активируется.
Нейронная сеть обрабатывает сигнал, поступающий на вход, и в конечном итоге, правый — выходной — нейрон загорается или не загорается. При такой архитектуре, для активации правого нейрона нужно хотя бы четыре активированных нейрона в левом ряду. Если горят 6 или 5 — он точно загорится, если от 0 до 3 — точно не загорится. Но если горят четыре, то он загорится только если они распределены равномерно: 2 в верхней половине и 2 в нижней.
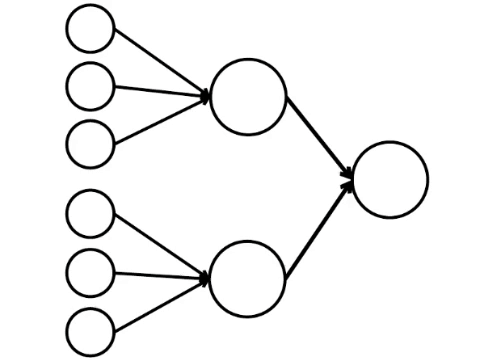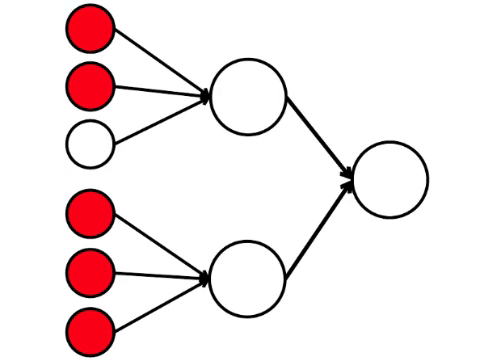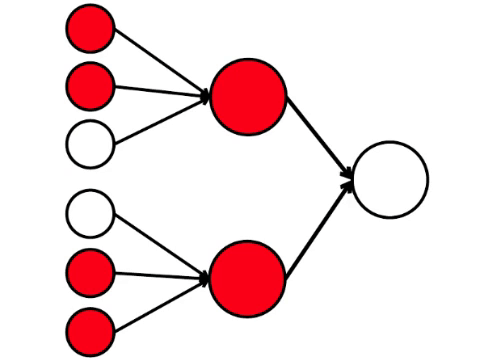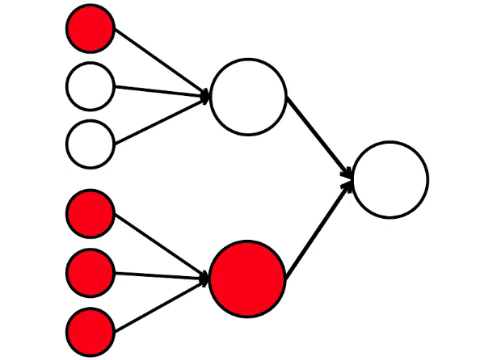
Получается, что простейшая схема из девяти кружочков приводит к довольно ветвистому рассуждению.
Искусственные нейронные сети работают примерно так же, но обычно не с такими простыми вещами, как “загорелось/не загорелось” (то есть 1 или 0), а с действительными числами.
Возьмём для примера сеть из 5 нейронов — два во входном слое, два в среднем (скрытом) и один в выходном. Между всеми нейронами соседних слоёв есть связи, к которым приписаны числа — веса. Чтобы узнать, что получается в пока незаполненном нейроне, сделаем очень простую вещь: посмотрим, какие связи в него ведут, домножим вес каждой связи на число, которое записано в нейроне предшествующего слоя, из которого идёт эта связь, и всё это просуммируем. В верхнем зелёном нейроне на схеме получается 50 × 1 + 3 × 10 = 80, а в нижнем — 50 × 0,5 − 3 × 10 = −5.
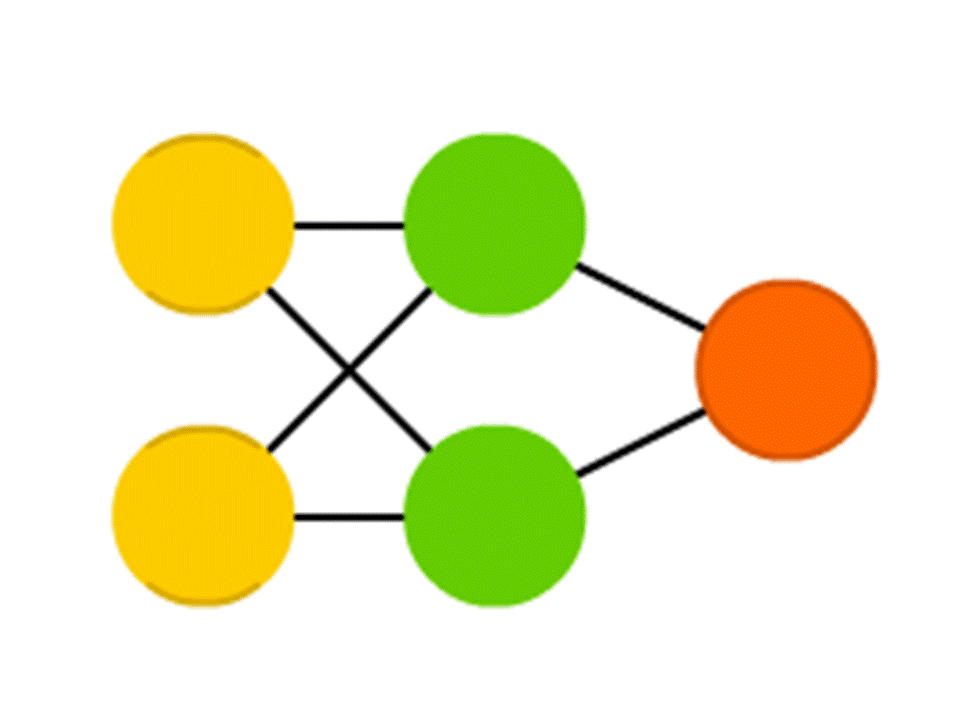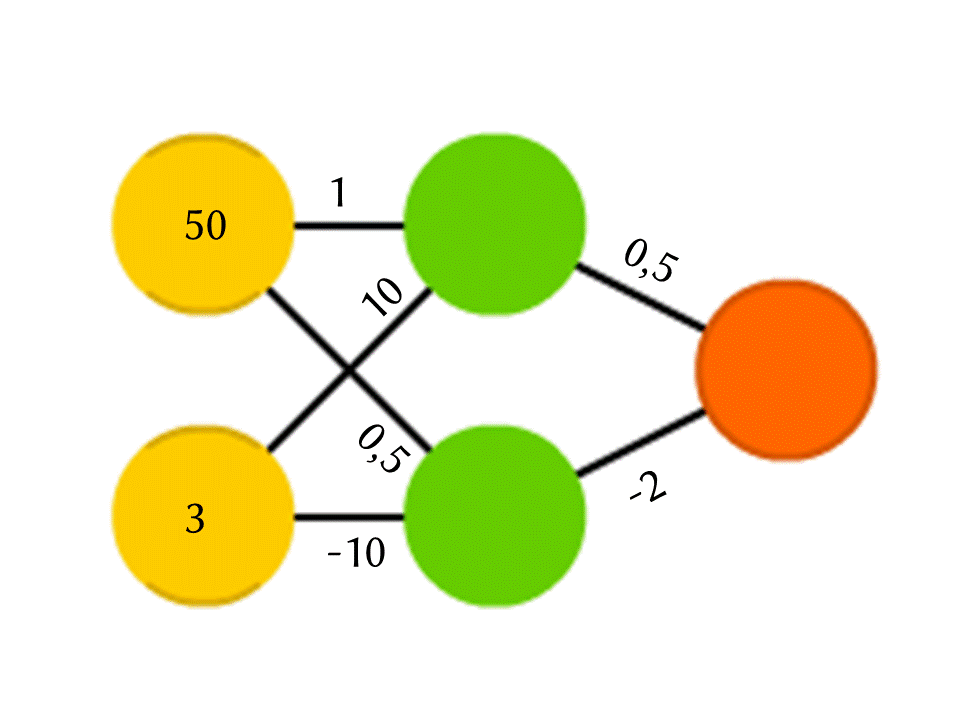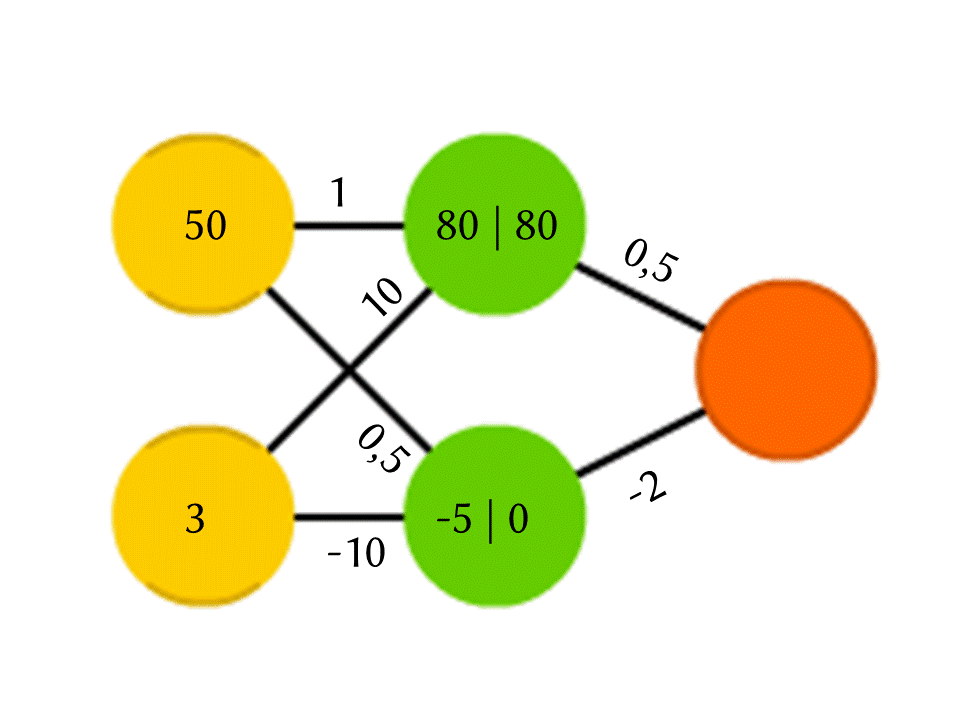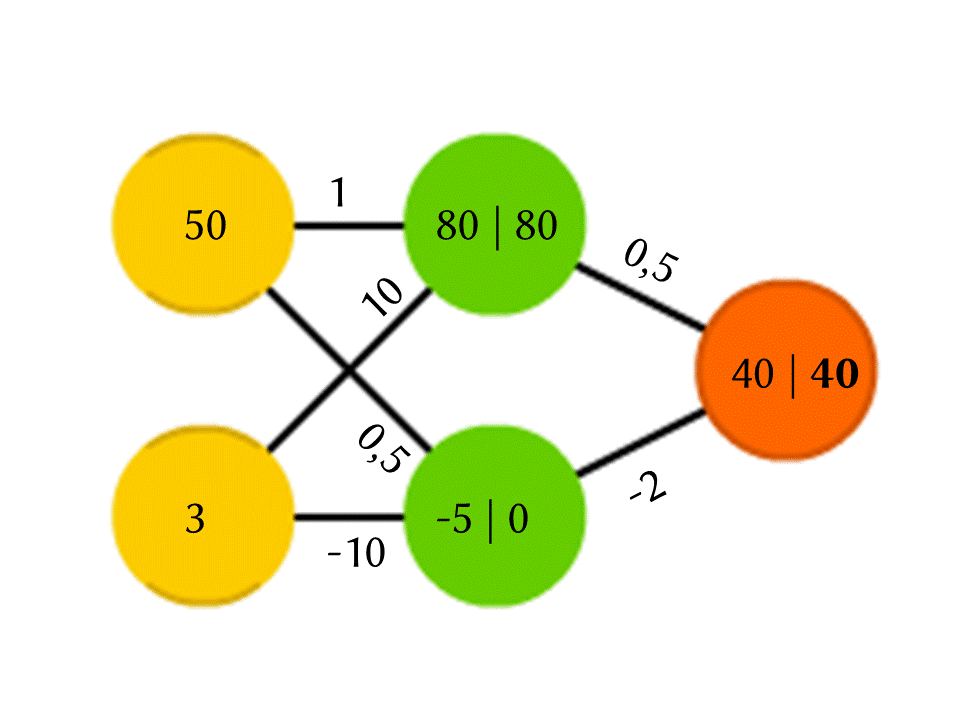
Правда, если делать только это, на выходе мы получим просто результат вычисления линейной функции от входных значений (в нашем примере выйдет 25 Y − 0,5 X, где X — число в верхнем жёлтом нейроне, а Y — в нижнем), поэтому договоримся, что внутри нейрона ещё что-то происходит. Самая простая и в то же время дающая хорошие результаты функция — ReLU (Rectified Linear Unit): если в нейроне получается отрицательное число, выдаём на выход 0, а если неотрицательное, то выдаём его в неизменном виде.
Так в нашей схеме −5 на выходе из нижнего зелёного нейрона превращается в 0, и именно это число используется в дальнейших вычислениях. Конечно, архитектура настоящих нейронных сетей, используемых на практике, куда сложнее, чем наши игрушечные примеры, да и веса берутся не с потолка, а подбираются путём обучения, но важен сам принцип.
Какое это отношение имеет к языку?
Самое прямое, при условии, что мы представим язык в виде чисел. Закодируем каждое слово и запустим в такую нейронную сеть.
Здесь на помощь приходит очень важное достижение компьютерной лингвистики, которое появилось в плане идеи 50 лет назад, а в плане реализации активно развивается последние лет 10: векторное представление слов.
эта и две следующие картинки — из презентации Штефана Эверта
Это представление слов в виде массива чисел на основе очень простого соображения. Чтобы узнать значение слова, мы смотрим не в словарь, а в огромные массивы текста и считаем, рядом с чем наше слово чаще встречается.
Например, знаете ли вы слово кашне? Если нет, попробуйте угадать, взглянув на тексты, где есть слово кашне.
— Черное пальто и белая кепка. Ну и еще какое-нибудь непременное кашне…
Рядом с ним предметы одежды, пальто и кепка, вероятно, и кашне из их ряда. Вряд ли это еда, вряд ли элемент архитектуры.
— На шее у него в душную ночь зачем-то было наверчено старенькое полосатое кашне.
На шее — значит, это не носки. Его можно навертеть — видимо, оно гибкое, сделано из ткани, а не, скажем, из дерева или камня.
— Мокроватое куцее вафельное полотенце Нержин повесил себе на шею вроде кашне.
Мы пополняем и пополняем банк примеров и, глядя на них, постепенно поймем, что такое кашне — нечто вроде шарфа. Ровно то же самое делает компьютер, который смотрит на текст и делает простую вещь — фиксирует слова, которые стоят рядом.
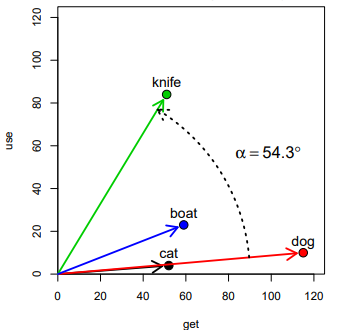
Вот египетские иероглифы.
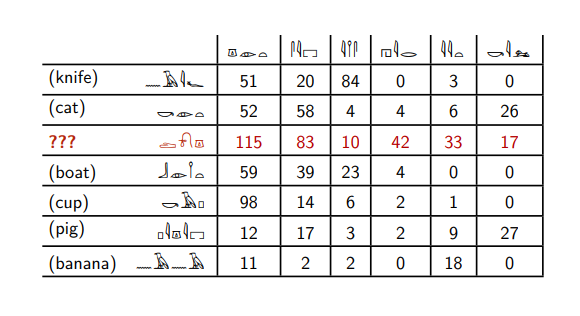
Предположим вы знаете значения шести из них, и хотите понять, что за слово выделено красным. В этой таблице написано, сколько раз эти слова встречаются рядом с другими египетскими иероглифами.
Красное слово встречается с шестым словом — так же, как слова кошка и свинья. А другие слова с ним не встречаются вообще.
Красное слово встречается со вторым словом заметно чаще, чем с третьим, в отличие от слов нож и банан. Так же ведут себя слова кошка, лодка, свинья и чашка.
Опираясь на такие рассуждения, мы можем сказать, что красное слово больше всего похоже на слова кошка и свинья — только они встречаются с шестым словом, у них похожее соотношение второго и третьего.
И мы не ошибемся, потому что красное слово — это слово собака.
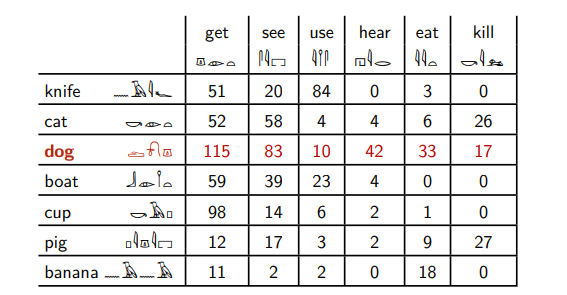
На самом деле — это не египетские иероглифы, а английские существительные и глаголы, для которых указано, сколько раз они встречаются рядом в большом собрании английских текстов. То самое шестое слово — это глагол kill.
Слова кошка, собака и свинья часто встречаются справа от слова убивать. Ножи, лодки и бананы убивают редко. Хотя по-русски при желании можно сказать, “я убил свою лодку”, но это вещь редкая.
Ровно так делает компьютер, когда обрабатывает текст. Просто считает, что встречается рядом с чем, и больше не происходит никаких шедевров понимания.
Дальше компьютер представляет слова в виде некоторого набора чисел: в примере выше слову dog соответствуют числа (115; 83; 10; 42; 33; 17). Вообще-то мы должны посчитать, сколько раз оно встречается не с шестью словами, а со всеми словами, которые есть в наших текстах: если всего у нас 100 000 разных слов, то слову dog мы поставим в соответствие массив из 100 000 чисел. Это не очень удобно на практике, поэтому обычно применяют методы уменьшения размерности, чтобы преобразовать полученные результаты для каждого слова в массив длиной несколько сотен элементов (подробнее об этом можно почитать здесь).
Есть готовые библиотеки для языков программирования, которые позволяют это сделать: например, gensim для Python. Подав ей на вход Брауновский корпус английского языка объёмом примерно 1 миллион слов, я за несколько секунд могу построить модель, в которой слово cat будет выглядеть следующим образом:

Мы представляем животное, с шерстью, хвостом, оно мяукает. Мой компьютер, который я учил английскому языку, представляет слово cat в виде ста чисел, которые получились от рядом стоящих слов.
Вот пример на русском материале с сайта RusVectōres. Я взял слово ворона и попросил компьютер мне сказать, какие слова больше всего на него похожи — или, иначе говоря, наборы чисел для каких слов больше всего похожи на набор чисел для слова ворона.

8 слов из 10 оказались названиями птиц. Ничего не зная, компьютер выдал отличный результат — понял, что на ворону похожи птицы. Но откуда-то взялись слова каление и рученька?
Догадаться можно
Со всеми тремя часто употеребляется слово белый: до белого каления, под белы рученьки, белая ворона.
Получая массивы чисел и пропуская их через себя, нейросети выдают поразительно хороший результат. Вот довольно сложный, философский текст из речи академика Андрея Зализняка, посвященной статусу науки в современном мире. Он переведен на английский гугл переводчиком месяц назад, и требует минимального вмешательства редактора.

Здесь возникает глобальный философский вопрос
Это проблема так называемой китайской комнаты — мыслительный эксперимент о границах искусственного интеллекта. Его сформулировал философ Джон Серл в 1980 году.
В комнате сидит человек, который не знает китайского языка. Ему даны инструкции, у него есть книжки, словари и два окна. В одно окно ему дают записочки на китайском языке, а в другое окно он выдает ответы — тоже на китайском языке, действуя исключительно по инструкциям.
Например, в инструкции может быть написано, “вот ты получил записку, найди иероглиф в словаре. Если это иероглиф №518, выдай в правое окно иероглиф №409, если поступил иероглиф №711, выдай в правое окно иероглиф №35 и так далее”. Если человек в комнате хорошо выполняет инструкции и если эти инструкции хорошо написаны, то человек на улице, который отдает и получает записочки, может предположить, что комната или тот, кто в ней находится, знает китайский язык. Ведь снаружи не видно, что происходит внутри.
Мы-то знаем, что это человек, которому просто дали тупейшие инструкции. Он делает по ним какие-то операции, а вовсе не знает китайский язык. Хотя с точки зрения наблюдателя — это знание языка.
Философский вопрос — как нам к этому относиться? Знает ли комната китайский язык? Может быть, китайский язык знает автор этих инструкций? А может быть и нет, потому что выдать инструкции можно, опираясь на массив готовых вопросов и ответов.
С другой стороны — а что вообще такое знать китайский язык? Вот вы знаете русский язык. Что вы умеете? Что у вас происходит в голове? Какие-то биохимические реакции. Уши или глаза получают некоторый сигнал, это вызывает какие-то реакции, вы что-то понимаете. Но что значит «понимаете»? Что вы делаете, когда понимаете?
И еще более сложный вопрос — а делаете ли вы это оптимальным способом? Верно ли, что вы работаете с языком лучше, чем мог бы работать с языком какой-нибудь аппарат? Можете ли вы представить, что будете говорить по-русски хуже, чем какой-нибудь компьютер? Мы всегда сравниваем Сири, Алису с тем, как говорим сами, и смеёмся, если они говорят неправильно с нашей точки зрения. С другой стороны, мы с вами отдали компьютеру очень многое из того, что раньше считалось прерогативой человека. Сейчас машины гораздо лучше считают и играют в шахматы, а раньше они этого не могли. Возможно, с говорящими компьютерами произойдет похожее: лет через 100, 10, или даже 5 мы признаем, что машина освоила язык гораздо лучше, понимает гораздо больше и вообще является намного лучшим носителем естественного языка, чем мы.
Что тогда делать с тем, что человек привык определять себя через язык? Ведь говорят, только человек владеет языком. Что будет, если мы признаем победу за компьютером и в этой области?
Оставляйте свои вопросы в комменатариях. Возможно чуть позже у нас получится сделать с Александром интервью. А может быть он и сам придет в комментарии по нашему инвайту и пообщается со всеми, кому интересно.
