Расширения браузера это web-приложения, которые устанавливаются в web-браузер чтобы расширить его возможности. Обычно для того чтобы воспользоваться расширением, пользователю нужно найти его в Chrome Web Store и установить.
В этой статье я покажу как создать расширение для браузера Google Chrome с нуля. Это расширение будет использовать API браузера для того чтобы получить доступ к содержимому web-страницы любой открытой вкладки. С помощью этих API можно не только читать информацию с открытых web-сайтов, но и взаимодействовать с этими страницами, например, переходить по ссылкам или нажимать на кнопки. Таким образом расширения браузера могут использоваться для широкого круга задач автоматизации на стороне клиента, таких как web-scrape или даже автоматизированное тестирование фронтенда.
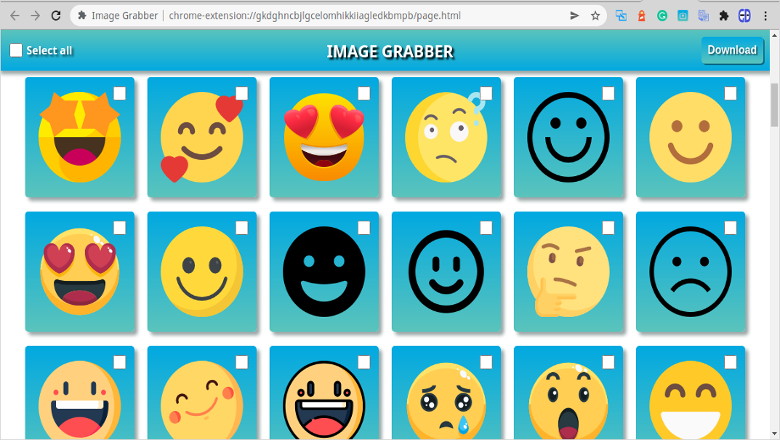
Мы создадим расширение, которое называется Image Grabber, которое будет содержать интерфейс для подключения к web-странице и для извлечения из нее информации о всех изображениях. Далее, при нажатии на кнопку "GRAB NOW" список абсолютных URL этих изображений будет скопирован в буфер обмена. В этом процессе вы познакомитесь с фундаментальными строительными блоками, которые в дальнейшем можно будет использовать для создания других расширений.
Расширения, создаваемые таким образом для браузера Chrome совместимы с другими браузерами, основанными на движке Chromium и могут быть установлены, например, в Yandex-браузер или Opera.
В результате, при правильном выполнении всех шагов, вы получите расширение, которое будет выглядеть и работать так, как показано на следующем видео: