Deep Dive into Animations in Flutter. How a Widget Turns into a Pixel on the Screen
Medium
5 min
Have you ever wondered what actually happens inside Flutter when you press a button and watch a smooth animation?
Have you ever wondered what actually happens inside Flutter when you press a button and watch a smooth animation?

За последние два месяца я написал несколько маленьких GLSL-демо. О первом из них, Red Alp, я написал статью. В ней я подробно расписал весь процесс, поэтому рекомендую прочитать её, если вам незнакома эта сфера.
Мы рассмотрим четыре демо: Moonlight, Entrance 3, Archipelago и Cutie. Но на этот раз я расскажу лишь о паре уроков, которые извлёк из каждого. Мы не будем углубляться во все аспекты, потому что это было бы излишне.

I'm stunned by the illogicality of others, and they are stunned by the fact that I'm a robot." This phrase perfectly describes the peculiarities of my interaction with the world around me. I'm like this robot. Or an alien. I can only guess how the other people see me. But now I know for sure that others consider me at least strange. The feeling is mutual. Many actions of people around me seem completely irrational and illogical to me.
For a long time, this baffled me. I didn't understand what was going on, and considered myself a deep introvert, a withdrawn, gloomy dude who did not understand people and their feelings at all. I kept wondering what was wrong with me…
Have you ever wondered what actually happens inside Flutter when you press a button and watch a smooth animation?

We continue our series of articles reviewing changes in PostgreSQL 19. This time we'll look at what emerged from the September 2025 CommitFest.
The highlights from the first July CommitFest are available here: 2025-07.
GROUP BY ALL
Window functions: NULL value handling
Event triggers in PL/Python
More precise error message for incorrect routine parameter names
random: random date/time within a specified range
base64url format for encode and decode functions
New debug_print_raw_parse parameter
The log_lock_waits parameter is now enabled by default
pg_stat_progress_basebackup: backup type
vacuumdb: collecting statistics on partitioned tables
Buffer cache: using clock-sweep algorithm to find free buffers
Fake table aliases in queries

TDE comes in many flavors — from encryption at the TAM level to full-cluster encryption and tablespace markers. We take a close look at Percona, Cybertec/EDB, Pangolin/Fujitsu, and show where you lose performance and reliability, and where you gain flexibility.
On top of that, Vasily Bernstein, Deputy head of product development, and Vladimir Abramov, senior security engineer, will share how Postgres Pro Enterprise implements key rotation without rewriting entire tables — and why AES-GCM was the clear choice.

This article reviews the November 2025 CommitFest.
For the highlights of the previous two CommitFests, check out our last posts: 2025-07, 2025-09.
Planner: eager aggregation
Converting COUNT(1) and COUNT(not_null_col) to COUNT(*)
Parallel TID Range Scan
COPY … TO with partitioned tables
New function error_on_null
Planner support functions for optimizing set-returning functions (SRF)
SQL-standard style functions with temporary objects
BRIN indexes: using the read stream interface for vacuuming
WAIT FOR: waiting for synchronization between replica and primary
Logical replication of sequences
pg_stat_replication_slots: a counter for memory limit exceeds during logical decoding
pg_buffercache: buffer distribution across OS pages
pg_buffercache: marking buffers as dirty
Statistics reset time for individual relations and functions
Monitoring the volume of full page images written to WAL
New parameter log_autoanalyze_min_duration
psql: search path in the prompt
psql: displaying boolean values
pg_rewind: skip copying WAL segments already present on the target server
pgbench: continue running after SQL command errors

We're launching a new series of articles covering the changes coming up in PostgreSQL 19. This first article focuses on the events from last summer's July CommitFest.
Connection service file in libpq parameter and psql variable
regdatabase: a type for database identifiers
pg_stat_statements: counters for generic and custom plans
pg_stat_statements: FETCH command normalization
pg_stat_statements: normalizing commands with parameter lists in IN clauses
EXPLAIN: Memoize node estimates
btree_gin: comparison operators for integer types
pg_upgrade: optimized migration of large objects
Optimized temporary table truncation
Planner: incremental sort in Append and MergeAppend nodes
Domain constraint validation no longer blocks DML operations
CHECKPOINT command parameters
COPY FROM: skipping initial rows
pg_dsm_registry_allocations: dynamic shared memory (DSM) usage

Bulk config rollouts, built-in OpenTelemetry, and two-click HA cluster control are all part of one goal: making PostgreSQL admin simpler and safer. PPEM 2.3 is a big step toward that — with user-defined presets, a reworked alerting system, and stronger RBAC — helping you bring order to messy configs and trust the system to warn you before things go sideways.
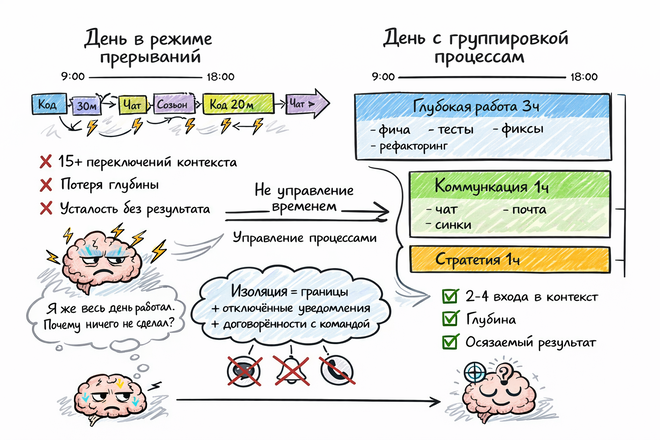
Временем управлять нельзя - это не ресурс и почему у меня внутри умирает один инженер? Предлагаю это проверить, получится ли прийти к чему-то общему.

September 25th marks the release of PostgreSQL 18. This article covers the March CommitFest and concludes the series covering the new features of the upcoming update. This article turned out quite large, as the last March CommitFest is traditionally the biggest and richest in new features.
You can find previous reviews of PostgreSQL 18 CommitFests here: 2024-07, 2024-09, 2024-11, 2025-01.

The story of the PostgreSQL logo was shared by Oleg Bartunov, CEO of Postgres Professional, who personally witnessed these events and preserved an archive of correspondence and visual design development for the database system.
Our iconic PostgreSQL logo — our beloved “Slonik” — has come a long way. Soon, it will turn thirty! Over the years, its story has gathered plenty of myths and speculation. As a veteran of the community, I decided it’s time to set the record straight, relying on the memories of those who were there. Who actually came up with it? Why an elephant? How did it end up in a diamond, and how did the Russian word “slonik” become a part of the global IT vocabulary?

Now that pgpro-otel-collector has had its public release, I’m excited to start sharing more about the tool — and to kick things off, I’m launching a blog series focused entirely on the Collector.
The first post is an intro — a practical guide to installing, configuring, and launching the collector. We’ll also take our first look at what kind of data the collector exposes, starting with good old Postgres metrics.

Continuing the series of CommitFest 19 reviews, today we're covering the January 2026 CommitFest.
The highlights from previous CommitFests are available here: 2025-07, 2025-09, 2025-11.
Partitioning: merging and splitting partitions
pg_dump[all]/pg_restore: dumping and restoring extended statistics
file_fdw: skipping initial rows
Logical replication: enabling and disabling WAL logical decoding without server restart
Monitoring logical replication slot synchronization delays
pg_available_extensions shows extension installation directories
New function pg_get_multixact_stats: multixact usage statistics
Improvements to vacuum and analyze progress monitoring
Vacuum: memory usage information
vacuumdb --dry-run
jsonb_agg optimization
LISTEN/NOTIFY optimization
ICU: character conversion function optimization
The parameter standard_conforming_strings can no longer be disabled

You’ve probably had this happen too: a service runs smoothly, keeps users happy with its stability and performance, and your monitoring stays reassuringly green. Then, the next moment — boom, it’s gone. You panic, dive into the error logs, and find either a vague segfault or nothing at all. What to do is unclear, and production needs saving, so you bring it back up — and everything works just like before. You try to investigate what happened, but over time you switch to other tasks, and the incident fades into the background or gets forgotten entirely.
That’s all fine when you’re on your own. But once you have many customers, sooner or later you start feeling that something isn’t right, and that you need to dig into these spikes of entropy to find the root cause of such incidents.
This article describes our year-long investigation. You’ll learn why PostgreSQL (and any other application) can crash because of a bug in the Linux kernel, what XFS has to do with it, and why memory reclamation might not be as helpful as you thought.

Today we want to talk about choosing a DBMS for WMS not as a dry technical discussion, but as a strategic decision that determines the security, budget, and future flexibility of your business. This is not about "why PostgreSQL is technically better," but about why it has become the only safe, cost-effective, and future-proof solution for Russian warehouse systems in the new reality.
This is not just another database article. It is a roadmap for those who do not want to wake up one day with a paralyzed warehouse and multi-million fines due to a bad decision made yesterday. At INTEKEY we have gone this path deliberately, and today our WMS projects for the largest market players run on PostgreSQL. We know from experience where the pitfalls are and how to avoid them.

Throughout their careers engineers build systems that protect data and guard it against corruption. But what if the right approach is the opposite: deliberately corrupting data, generating it out of thin air, and creating forgeries indistinguishable from the real thing?
Maksim Gramin, systems analyst at Postgres Professional, explains why creating fake data is a critical skill for testing, security, and development — and how to do it properly without turning your database into a junkyard of “John Smith” entries.

It all started as a joke by the office coffee machine. But, as with every decent joke, it suddenly sounded worth trying — and before we knew it, we were knee-deep in an experiment that turned out to be anything but trivial, complete with a whole minefield of gotchas.
It began simply: while everyone else was busy debating hardware tuning and squeezing out extra TPS from their systems, we thought — why not just shove a huge chunk of data into PostgreSQL and see how it holds up? Like, really huge. Say, a one-petabyte database. Let’s see how it survives that.
It was December 10, the boss wanted the report by January 20, and New Year was less than a month away. And that itch that all engineers know? It hit hard.

You may have already read in the news that on the eve of Cosmonautics Day, a new stable release of Angie 1.9.0 was released, an nginx fork that continues to be developed by the team of former nginx developers. Approximately every quarter, we try to release new stable versions and delight users with numerous improvements. This release is no exception, but it's one thing to read a dry changelog and quite another to get to know the functionality in more detail, to learn how and in which cases it can be applied.
The list of innovations that we will discuss in more detail:
— Saving shared memory zones with cache index to disk;
— Persistent switching to a backup group of proxied servers;
— 0-RTT in the stream module;
— New busy status for proxied servers in the built-in statistics API;
— Improvements to the ACME module, which allows automatic obtaining of Let's Encrypt TLS certificates and others;
— Caching TLS certificates when using variables.

Hey, Habr! Ivan Glinkin is here again, head of the hardware research group from the Bastion team.
"A flash drive with a combination lock," "a flash drive with hardware encryption," "an encrypted USB drive," and finally, the proper term — "Cryptographic Module". An encrypted USB flash drive goes by many names, but the core concept remains the same.
The purpose of such a device is to protect sensitive information from unauthorized access at both the software and hardware levels through encryption, anti-tampering mechanisms, and various other safeguards. But are these secure USB drives really as reliable as they're made out to be, or is it all just smoke and mirrors?
We decided to look past the marketing claims and conduct our own investigation, attempting to crack several of these devices using hardware reverse engineering. We attempted to extract data, identify the encryption algorithms used, physically open the drives, and read their memory chips.
The results were quite interesting. Read on for the details.