Искрографик (англ. sparkline) — это термин, который придумал Эдвард Тафти для обозначения миниатюрных (word-sized), но информационно-плотных графиков. Они показывают общую картину там, где нет места для размещения нормальных графиков с осями координат. Особенно полезными могут быть в таких областях как финансы и трейдинг, спортивные события, научный и медицинский анализ, системное администрирование.

Зак Холман (Zach Holman) из Github написал shell-скрипт Spark, который строит инфографику простой командой
Зак Холман (Zach Holman) из Github написал shell-скрипт Spark, который строит инфографику простой командой
spark прямо из шелла (достаточно добавить скрипт куда-нибудь в $PATH).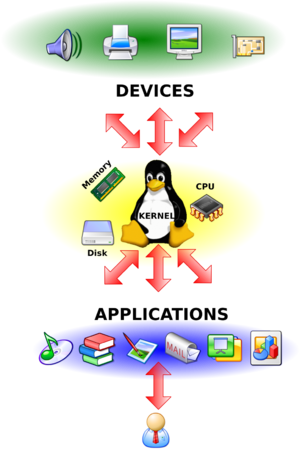
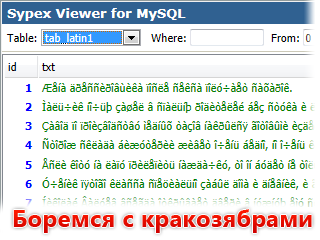 В связи с тем, что довольно много людей обращается с просьбой помочь исправить проблему с кодировками MySQL, решил написать статью с описанием, как «лечить» наиболее часто встречающиеся случаи.
В связи с тем, что довольно много людей обращается с просьбой помочь исправить проблему с кодировками MySQL, решил написать статью с описанием, как «лечить» наиболее часто встречающиеся случаи.
 Суть сводится к тому, что эту команду в виде «make install» или «sudo make install» использовать в современных дистрибутивах нельзя.
Суть сводится к тому, что эту команду в виде «make install» или «sudo make install» использовать в современных дистрибутивах нельзя. 
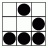
 Иногда возникают такие ситуации, когда нужно прочитать QR код, а смартфона под рукой нет. Что же делать? В голову приходит лишь попробовать прочитать вручную. Если кто-нибудь сталкивался с такими ситуациями или кому просто интересно как же читается QR код машинами, то данная статья поможет вам разобраться в этой проблеме.
Иногда возникают такие ситуации, когда нужно прочитать QR код, а смартфона под рукой нет. Что же делать? В голову приходит лишь попробовать прочитать вручную. Если кто-нибудь сталкивался с такими ситуациями или кому просто интересно как же читается QR код машинами, то данная статья поможет вам разобраться в этой проблеме.