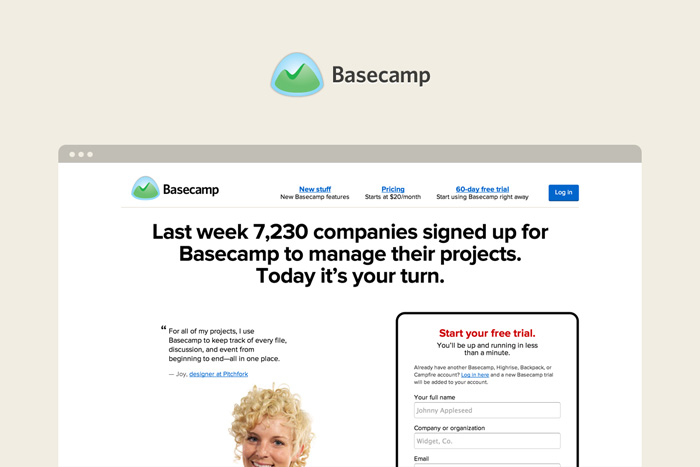
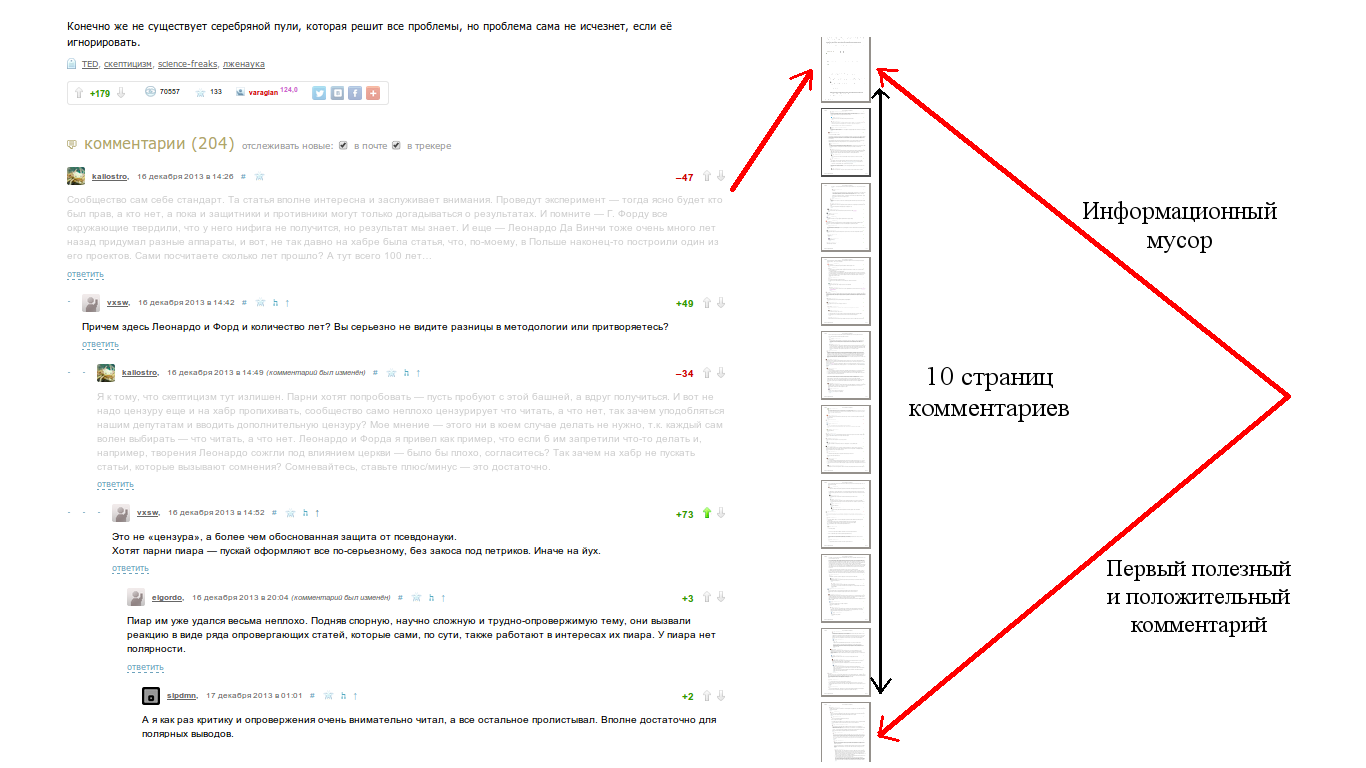
Мечта о том, чтобы машина понимала человеческий язык, завладела умами еще когда компьютеры были большими, а их производительность – маленькой. Главная проблема на пути к этому заключается в том, что грамматика и семантика естественных языков слабо поддаются формализации. Кроме того, от языков программирования их отличает присутствие многозначности.
Конечно, мечта о полноценной коммуникации с компьютером на естественном языке пока еще далека от полноценной реализации примерно настолько же, как и мечта об искусственном интеллекте. Однако некоторые результаты есть уже сейчас: машину можно научить находить нужные объекты в тексте на естественном языке, находить между ними связи и представлять необходимые данные в формализованном виде для дальнейшей обработки. В Яндексе уже достаточно давно применяется такая технология. Например, если вам придет письмо с предложением о встрече в определенном месте и в определенное время, специальный алгоритм самостоятельно извлечет нужные данные и предложит внести ее в календарь.
Вскоре мы планируем отдать эту технологию в open source, чтобы любой мог пользоваться ей и развивать ее, приближая тем самым светлое будущее свободного общения между человеком и компьютером. Подготовка к открытию исходных кодов уже началась, но процесс этот не такой быстрый, как нам бы хотелось, и, скорее всего, продлится до конца этого года. За это время мы постараемся как можно больше рассказать о своем продукте, для чего запускаем серию постов, в рамках которой расскажем об устройстве инструмента и принципах работы с ним.
Называется технология Томита-парсер, и по большому счету, любой желающий может воспользоваться ей уже сейчас: бинарные файлы доступны для скачивания. Однако прежде чем пользоваться технологией, нужно научиться ее правильно готовить.
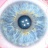
 Иногда возникает необходимость ускорить вычисления, причем желательно сразу в разы. При этом приходится отказываться от удобных, но медленных инструментов и прибегать к чему-то более низкоуровневому и быстрому. R имеет довольно развитые возможности для работы с динамическими бибиотеками, написанными на С/С++, Fortran или даже Java. Я по привычке предпочитаю С/С++.
Иногда возникает необходимость ускорить вычисления, причем желательно сразу в разы. При этом приходится отказываться от удобных, но медленных инструментов и прибегать к чему-то более низкоуровневому и быстрому. R имеет довольно развитые возможности для работы с динамическими бибиотеками, написанными на С/С++, Fortran или даже Java. Я по привычке предпочитаю С/С++.




 В последнее время пользователи все чаще получают изображения документов при помощи фотокамер или мобильных устройств, прибегая к помощи сканера изредка, в особых случаях. В то же время, для изображений, получаемых фотокамерами, характерны следующие недостатки: геометрические искажения (о них мы говорили в
В последнее время пользователи все чаще получают изображения документов при помощи фотокамер или мобильных устройств, прибегая к помощи сканера изредка, в особых случаях. В то же время, для изображений, получаемых фотокамерами, характерны следующие недостатки: геометрические искажения (о них мы говорили в