Читать дальше →

235 @235
User
Highcharts: Красивые, динамические чарты за 5 минут!
2 min
Highcharts — библиотека для создания чартов написанная на JavaScript, позволяет легко добавлять интерактивные, анимированные графики на сайт или в веб-приложение. На данный момент чарты поддерживают большое количество диаграмм линейных, круговых, колоночных рассеивающих и многих других типов.
 Чарты работают со всеми популярными браузерами, включая Safari на iPhone.
Чарты работают со всеми популярными браузерами, включая Safari на iPhone.Минимальная версия для IE составляет 6+. Также браузеры поддерживающие Canvas элемент, и в некоторых случаях SVG для графического рендеринга.
nginx + apache. Кеширование
4 min
Привет, %username%
Тут я хочу рассказать о том, как я настраивал кеширование на одном сервере, точнее VDS. Характеристики сервера: 2000MHz, 2GB RAM, 80Gb HDD, технология виртуализации — OpenVZ.
Было решено использовать Nginx версии 0.7.64. На сервере находилось около 200 сайтов. И несколько высоко нагруженных проектов. Вот эти самые проекты и давали ощутимые тормоза и нагрузку на сервер. Мы будем рассматривать DLE в этом примере.
Тут я хочу рассказать о том, как я настраивал кеширование на одном сервере, точнее VDS. Характеристики сервера: 2000MHz, 2GB RAM, 80Gb HDD, технология виртуализации — OpenVZ.
Было решено использовать Nginx версии 0.7.64. На сервере находилось около 200 сайтов. И несколько высоко нагруженных проектов. Вот эти самые проекты и давали ощутимые тормоза и нагрузку на сервер. Мы будем рассматривать DLE в этом примере.
Триграммный индекс или «Поиск с опечатками»
4 min
Как-то по долгу службы появилась необходимость добавить к поиску на сайте всем известную фичу, сервис «Возможно вы имели в виду…» или «Поиск с опечатками». Стали думать как реализовывать. Сторонние сервисы и api использовать не хотелось, ибо время до чужого сервера и назад, да и в целом не очень хорошо. Как раз кстати пришелся модуль pg_trgm, который ищет близкие к запросу слову на основе триграммного индекса.
Основы работы с потоками в языке Python
20 min
Предисловие
Данную статью я затеял написать после учащающихся вопросов как на форуме так и вопросов в icq на тему многопоточности в CPython. Проблема людей, которые их задают происходит, в основном, из незнания или непонимания основных принципов работы многопоточных приложений. По крайней мере, это относится к используемой мной модели многопоточности, которая носит название Thread Pool (Пул потоков). Часто встречаемой проблемой является и другое: люди не имеют элементарных навыков работы со стандартными модулями CPython. В статья я постараюсь привести примеры такого незнания, не останавливаясь на личностях, так как это по моему скромному мнению неважно. Исходя из условий, в которых пишется эта статья, то мы немного затронем и работу через proxy серверы (не путать с SOCKS).
jQuery.keyboard v0.1.0
2 min

У меня есть на примете как минимум два проекта, в которых понадобится активное управление с помощью клавиатуры. Поэтому, я сел и написал удобный и красивый плагин для jQuery, который выкладываю во всеобщий доступ под свободной лицензией LGPL.
Python и emacs, несколько удобных решений
5 min
Расскажу немного о том, как быстро превратить emacs в полноценную python IDE. Начнем с интересного способа автозавершения кода + по ходу дела добавим еще пару интересных и полезных возможностей. Наверняка многие используют что-то типа rope (или может свои какие-то решения) и это довольно разумно, но не слишком наглядно. Расскажу об одном дополнительном способе.
Теперь по нажатию TAB мы будем получать вот это:

Теперь по нажатию TAB мы будем получать вот это:
Все что нужно знать о секционировании (Часть 1)
5 min
Часть 2
Добрый вечер/день/утро уважаемые хабралюди! Продолжаем развивать и дополнять блог о моей любимой open source rdbms Postgresql. Чудесным образом так получилось, что тема сегодняшнего топика еще ни разу здесь не подымалась. Надо сказать, что секционирование в postgresql очень хорошо описано в документации, но разве ж это меня остановит?).
Добрый вечер/день/утро уважаемые хабралюди! Продолжаем развивать и дополнять блог о моей любимой open source rdbms Postgresql. Чудесным образом так получилось, что тема сегодняшнего топика еще ни разу здесь не подымалась. Надо сказать, что секционирование в postgresql очень хорошо описано в документации, но разве ж это меня остановит?).
Фундаментальный баг Adobe Flash не будут исправлять
1 min
Специалисты по безопасности из Foreground Security обнаружили проблему с Adobe Flash, которая затрагивает почти все сайты, поддерживающие загрузку пользовательского контента, даже если сам сайт формально не показывает Flash. Дело в том, что ничто не мешает сделать object/embed на какой-нибудь страничке, не имеющей отношения к сайту, потому как Flash имеет доступ к куки того домена, с которого он загружен (а не того, где расположен тег object).
Проблема заключается в свойстве ActionScript same-origin, которое допускает выполнение активного контента в рамках данного домена. Но если UGC можно загрузить на доверенный сайт, то вредоносный скрипт будет выполнится у всех посетителей этого сайта, у которых установлен Flash.
Компания Adobe сказала, что исправить баг очень непросто и переложила всю ответственность за защиту от вредоносного кода на администраторов сайтов. Рекомендуется выделять для хранения UGC отдельный домен. Но не всегда это возможно: даже сайт самой компании Adobe подвержен данной уязвимости.
Атаку можно проводить в том числе через Gmail (см. видео).
Проблема заключается в свойстве ActionScript same-origin, которое допускает выполнение активного контента в рамках данного домена. Но если UGC можно загрузить на доверенный сайт, то вредоносный скрипт будет выполнится у всех посетителей этого сайта, у которых установлен Flash.
Компания Adobe сказала, что исправить баг очень непросто и переложила всю ответственность за защиту от вредоносного кода на администраторов сайтов. Рекомендуется выделять для хранения UGC отдельный домен. Но не всегда это возможно: даже сайт самой компании Adobe подвержен данной уязвимости.
Атаку можно проводить в том числе через Gmail (см. видео).
Map/Reduce: решение реальных задач — TF-IDF — 2
3 min
Продолжая статью “Использование Hadoop для решения реальных задач”, хочу напомнить, что в прошлой статье мы остановились на том, что посчитали такую характеристику как tf(t,d), и сказали, что в следующем посте мы будем считать idf(t) и завершим процесс вычисления значения TF-IDF для данного документа и термина. Поэтому предлагаю долго не откладывать и переходить к этой задаче.
Важно заметить, что idf(t) не зависит от документа, потому как считается на всем корпусе. Это нетрудно увидеть, посмотрев на формулу:
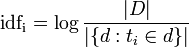
Вероятно, она нуждается в некоторых пояснениях. Итак, |D| это мощность корпуса документов — иными словами, просто количество документов. Мы знаем его, поэтому считать ничего не надо. Знаменатель же логарифма — это количество таких документов d которые содержат интересующий нас токен t_i.
Важно заметить, что idf(t) не зависит от документа, потому как считается на всем корпусе. Это нетрудно увидеть, посмотрев на формулу:
Вероятно, она нуждается в некоторых пояснениях. Итак, |D| это мощность корпуса документов — иными словами, просто количество документов. Мы знаем его, поэтому считать ничего не надо. Знаменатель же логарифма — это количество таких документов d которые содержат интересующий нас токен t_i.
Map/Reduce: решение реальных задач — TF-IDF
6 min
Вчера я задал вопрос в своем ХабраБлоге — интересно ли людям узнать, что такое Hadoop с точки зрения его реального применения? Оказалось, интересно. Дело недолгое — статью я написал довольно быстро (по крайней мере, ее первую часть) — как минимум, потому, что уже давно знал, о чем собираюсь написать (потому как еще неплохо помню как я сам тыкался в поиске информации, когда начинал пользоваться Hadoop). В первой статье речь пойдет об основах — но совсем не о тех, про которые обычно рассказывают :-)
Перед прочтением статьи я настоятельно рекомендую изучить как минимум первый и последний источники из списка для чтения — их понимание или хотя бы прочтение практически гарантирует, что статья будет понята без проблем. Ну что, поехали?

Ну скажите, какой смысл об этом писать? Уже не раз это проговаривалось, неоднократно начинали писаться посты на тему Hadoop, HDFS и прочая. К сожалению, обычно все заканчивалось на довольно пространном введении и фразе “Продолжение следует”. Так вот: это — продолжение. Кому-то тема, затрагиваемая в этой статье может показаться совершенно тривиальной и неинтересной, однако же лиха беда начало — любые сложные задачи надо решать по частям. Это утверждение, в частности, мы и реализуем в ходе статьи. Сразу замечу, что я постараюсь избежать написания кода в рамках этой конкретной статьи — это может подождать, а понять принципы построения программ, работающих с Map/Reduce можно и “на кошках” (к тому же с текущей частотой кардинального изменения API Hadoop любой код становится obsolete примерно через месяц).
Когда я начинал разбираться с Хадупом, очень большой сложностью лично для меня стало первоначальное понимание идеологии Map/Reduce (я предпочитаю писать это словосочетание именно так, чтобы подчеркнуть, что речь идет не о продукте, а о принципе). Суть и ценность метода станет понятна в самом конце — после того, как мы решим несложную задачу.
Перед прочтением статьи я настоятельно рекомендую изучить как минимум первый и последний источники из списка для чтения — их понимание или хотя бы прочтение практически гарантирует, что статья будет понята без проблем. Ну что, поехали?
Что такое Hadoop?
Ну скажите, какой смысл об этом писать? Уже не раз это проговаривалось, неоднократно начинали писаться посты на тему Hadoop, HDFS и прочая. К сожалению, обычно все заканчивалось на довольно пространном введении и фразе “Продолжение следует”. Так вот: это — продолжение. Кому-то тема, затрагиваемая в этой статье может показаться совершенно тривиальной и неинтересной, однако же лиха беда начало — любые сложные задачи надо решать по частям. Это утверждение, в частности, мы и реализуем в ходе статьи. Сразу замечу, что я постараюсь избежать написания кода в рамках этой конкретной статьи — это может подождать, а понять принципы построения программ, работающих с Map/Reduce можно и “на кошках” (к тому же с текущей частотой кардинального изменения API Hadoop любой код становится obsolete примерно через месяц).
Когда я начинал разбираться с Хадупом, очень большой сложностью лично для меня стало первоначальное понимание идеологии Map/Reduce (я предпочитаю писать это словосочетание именно так, чтобы подчеркнуть, что речь идет не о продукте, а о принципе). Суть и ценность метода станет понятна в самом конце — после того, как мы решим несложную задачу.
Тестирование Django приложений с помощью Selenium
6 min

Selenium
Selenium — это очень удобный (имхо) инструмент для тестирования веб-приложений.
Тесты создаются с помощью дополнения для Firefox, которое может генерировать код теста на различных языках, в том числе и на Python. Затем эти тесты выполняются специальным сервером, Selenium RC.
Сам по себе Selenium не привязан ни к языкам ни к фреймворкам, поэтому чтобы интегрировать его в систему тестирования Django-приложений, нужно приложить очень небольшие усилия.
Для решения задачи интеграции я буду использовать библиотеку Django: Sane Testing. Это библиотека, расширяющая возможности стандартной системы тестирования Django, в том числе и поддержкой тестов Selenium.
Рекурсивные (Иерархические) запросы в PostgreSQL
7 min
Вслед за Ораклом со своим ‘connet by prior ‘ все остальные СУБД вводят свои реализации иерархических запросов (ИЗ). Хотелось бы рассказать широкой аудитории как это сделано в PostgreSQL.
Мелочи, облегчающие жизнь
3 min
Postgresql, без сомнения, великолепная СУБД. Она обладает обширнейшими возможностями, отличной документации, и при всем при этом является бесплатной. Однако, всегда найдется что-то, чего пользователю не будет хватать. И в postgresql это легко исправляется, ведь он позволяет создавать функции на языках на любой вкус, будь то Plpgsql, Perl или даже Java.
Приведу пример. Мне всегда не хватало функции, получающей DDL выбранной таблицы. В oracle, например, вы можете воспользоваться для этого средствами пакета dbms_metadata. А вот в postgresql аналога почему-то нет. То есть можно конечно использовать pgdump, но это уже немного не то, мне хотелось бы иметь функцию бд. И так далее, думаю у каждого найдется несколько таких небольших «хотелок».
В любой моей базе я создаю в схеме «public» определенный набор вот таких облегчающих мне жизнь функций. В этом топике я хочу поделиться ими. Приглашаю всех также поделиться в комментариях своими наработками.
Приведу пример. Мне всегда не хватало функции, получающей DDL выбранной таблицы. В oracle, например, вы можете воспользоваться для этого средствами пакета dbms_metadata. А вот в postgresql аналога почему-то нет. То есть можно конечно использовать pgdump, но это уже немного не то, мне хотелось бы иметь функцию бд. И так далее, думаю у каждого найдется несколько таких небольших «хотелок».
В любой моей базе я создаю в схеме «public» определенный набор вот таких облегчающих мне жизнь функций. В этом топике я хочу поделиться ими. Приглашаю всех также поделиться в комментариях своими наработками.
Расширения Firefox — Работа с настройками
5 min
Сегодня я хотел бы рассказать о том, как можно реализовать систему настроек для своего расширения. Начиная с определения опций и заканчивая добавлением в ваше расширение возможности менять настройки с помощью созданных вами диалоговых окон.
Первую статью, надеюсь из будущего цикла моих статей, можно найти здесь.
Первую статью, надеюсь из будущего цикла моих статей, можно найти здесь.
Создание расширения FireFox для начинающих
8 min
В данной статье представлена пошаговая инструкция по разработке простейшего расширения для FireFox.
Это частичный перевод оригинальной статьи.
Это не моя статья, а моего друга (его мыльце: templar8@gmail.com).Он очень хочет попасть на Хабр. У меня самого не хватает кармы для инвайта.
Это частичный перевод оригинальной статьи.
Это не моя статья, а моего друга (его мыльце: templar8@gmail.com).
Обзор e-Learning трекеров или Век живи — век учись!
3 min
Все чаще можно услышать про универсальных трекеров-монстров типа ThePirateBay.org, torrents.ru или упоминания трекеров музыкальной либо игровой тематики. Но помимо них давно существуют торрент-трекеры обучающей направленности, о которых мало что известно рядовому пользователю. В основном, это закрытые сообщества образованных людей с регистрацией по приглашениям, которые обмениваются обучающими материалами, будь-то электронные книги, обучающее видео, CBT (computer based trainings), аудио-книги, презентации с конференций или софт для обучения. Преобладающая часть материалов связана с ИТ-технологиями и поэтому будет особенно полезна ИТ-специалистам, от студента, изучающего Linux, PHP или C# и до гуру, который готовится к сдаче CCIE. Также присутствует материал, посвященный изучению иностранных языков, психологии, саморазвитию, соблазнению, развитию бизнес-навыков. Если ты подумываешь сдать на CCNA, MCSE, RHCE, CISSP, Network+, PMP, IELTS/TOEFL и так далее — то здесь можно найти все необходимое и даже больше. Под катом находится обзор англоязычных ресурсов обучающей направленности.
Кеширование FastCGI-запросов в nginx
2 min
Доброе утро, Хабр!
В данной статье я приведу пример конфигурации nginx для кеширования FastCGI-запросов. При желании его можно использовать его для защиты от хабраэффекта, частично от DDoS'а и, как вариант, для облегчения жизни сервера с высокой нагрузкой.
В данной статье я приведу пример конфигурации nginx для кеширования FastCGI-запросов. При желании его можно использовать его для защиты от хабраэффекта, частично от DDoS'а и, как вариант, для облегчения жизни сервера с высокой нагрузкой.
Полная визуализация интернет-аналитики
4 min
Приступая к этим заметкам, пересмотрел хрестоматийный ролик «1984», которым компания Apple в свое время ярко противопоставила себя миру серости и занудства, под которым тогда подразумевались персональные компьютеры IBM.
Именно такие ассоциации порождает стартап Webvisor (Вебвизор). Он предлагает не просто принципиально новый подход к интернет-аналитике. Среди всех подобных систем он выделяется яркостью и наглядностью, противопоставляющими себя определенному занудству отчетов интернет-счетчиков, хотя бы и не похожих на Большого Брата. Подход WebVisor основан на детальном визуальном анализе поведения каждого посетителя.
Именно такие ассоциации порождает стартап Webvisor (Вебвизор). Он предлагает не просто принципиально новый подход к интернет-аналитике. Среди всех подобных систем он выделяется яркостью и наглядностью, противопоставляющими себя определенному занудству отчетов интернет-счетчиков, хотя бы и не похожих на Большого Брата. Подход WebVisor основан на детальном визуальном анализе поведения каждого посетителя.
Древнейший стресс-менеджмент
2 min
Хочу поделиться с вами одной интересной медитацией (медитация как известно — древнейший способ стресс-менеджмента), которой поделился со мной мой учитель в ту светлую пору, когда я увлекался разными духовными практиками.

С моим учителем ей поделился в своё время один лаосский монах. И дошла она до нас в неизменном виде (не считая перевода) через много столетий.
Цель этой медитации — добиться стабильного уравновешенного состояния и стрессоустойчивости, проще говоря перестать нервничать, психовать и переживать по различным поводам, а уметь в любой ситуации принимать обдуманные хладнокровные решения (поругался с заказчиком, обманули подрядчики, любимая девушка мозг вынесла, начальник идиот, сайт лёг, да мало ли поводов попариться).
С моим учителем ей поделился в своё время один лаосский монах. И дошла она до нас в неизменном виде (не считая перевода) через много столетий.
Цель этой медитации — добиться стабильного уравновешенного состояния и стрессоустойчивости, проще говоря перестать нервничать, психовать и переживать по различным поводам, а уметь в любой ситуации принимать обдуманные хладнокровные решения (поругался с заказчиком, обманули подрядчики, любимая девушка мозг вынесла, начальник идиот, сайт лёг, да мало ли поводов попариться).