
Кратко и по делу разберем основные принципы, чтобы помочь себе. А, исходя из них, вместе изучим реальную пользу методик и способов облегчения ситуации.

User
Кратко и по делу разберем основные принципы, чтобы помочь себе. А, исходя из них, вместе изучим реальную пользу методик и способов облегчения ситуации.

Круг DevOps – катаем квадратное, таскаем круглое
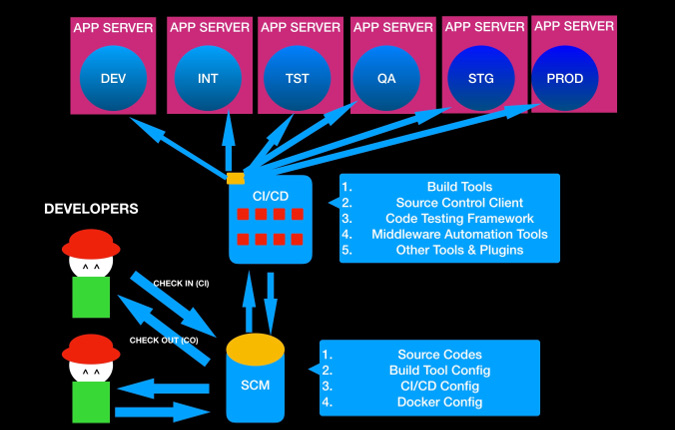
Всем привет! Это третья, завершающая, часть нашего рассказа о том, как «Ростелеком ИТ» внедряет CI/CD & DevOps в энтерпрайзовый ИТ-ландшафт и тяжелые монолитные Legacy-системы. Первую часть про внедрение CI/CD в десятки проектных команд очень большой компании можно прочитать на Хабре по ссылке здесь. Вторую часть – сугубо инженерную, с описанием прикладных подходов, инструментов и реализаций – читайте тут.
Сегодня мы расскажем про процесс внедрения в рамках Karma Framework в круге.

Приветствую всех! Меня зовут Георгий. Я работаю в компании servers.com. Я пришел рассказать про Ansible: про хороший Ansible и про плохой Ansible в основном, т. е. про то, как люди могут плохо делать на Ansible.
Публикуем новый перевод и надеемся, что рекомендации автора помогут вам оптимизировать образ Docker.

У меня никода не было мотивации заниматься физкультурой. Даже в детстве я предпочитал спорту киберспорт. С началом профессиональной деятельности поменялся только характер запускаемых программ. Спортивным стало программирование. И, как полагается профессиональному спортсмену, я продолжал хорошо питаться. Все поменялось когда мне стукнуло 25. Я поменял свое отношение к физическим нагрузкам - я стал их просто ненавидеть, они стали моим приговором. При росте 175 и весе в 120 кг я заимел гипертонию с аритмией. Выполнение обычных бытовых дел выматывало так, что на работу сил оставалось все меньше и меньше. Впереди начали маячить серьезные проблемы со здоровьем. Как я за 10 лет нашел выход из этой ситуации? Да никак. Подробности под катом.

В этом руководстве мы будем изучать, как тестировать код инфраструктуры, написанный на Ansible, с использованием инфраструктуры тестирования, известной как Molecule. Внутри Molecule мы будем использовать Ansible в качестве верификатора, чего я пока нигде не мог найти. Давай сделаем это!
FastCGI Cache — это система кэширования данных реализованая на уровне HTTP-сервера Nginx.
Преимущество FastCGI Cache заключается в том, что Nginx вернёт закешированный ответ пользователю сразу, как только получит запрос, при этом слой приложения не будет вовсе обрабатывать поступивший HTTP-запрос, если он имеется в кэше Nginx.
Использование FastCGI Cache — отличный способ снизить нагрузку на вашу систему.
Если на вашем сайте есть страницы, которые изменяются редко или задержка обновления информации на некоторое время не критична, то FastCGI Cache именно то, что нужно.



Привет! За последнее время вышло много классных инструментов автоматизации как для сборки Docker-образов так и для деплоя в Kubernetes. В связи с этим решил поиграться с гитлабом, как следует изучить его возможности и, конечно же, настроить пайплайн.
Вдохновлением для этой работы стал сайт kubernetes.io, который генерируется из исходных кодов автоматически, а на каждый присланный пул реквест робот автоматически генерирует preview-версию сайта с вашими изменениеми и предоставляет ссылку для просмотра.
Я постарался выстроить подобный процесс с нуля, но целиком построенный на Gitlab CI и свободных инструментах, которые я привык использовать для деплоя приложений в Kubernetes. Сегодня я, наконец, расскажу вам о них подробнее.
В статье будут рассмотрены такие инструменты как:
Hugo, qbec, kaniko, git-crypt и GitLab CI с созданием динамических окружений.


Перевод статьи подготовлен в преддверии старта курса «Администратор Linux. Виртуализация и кластеризация»

Балансировка нагрузки — это распространенное решение для горизонтального масштабирования веб-приложений по нескольким хостам с предоставлением пользователям единой точки доступа к сервису. HAProxy является одной из самых популярных программ для балансировки нагрузки с открытым исходным кодом, которая также обеспечивает высокую доступность и функциональность проксирования.
HAProxy стремится оптимизировать использование ресурсов, максимизировать пропускную способность, минимизировать время отклика и избежать перегрузки каждого отдельно взятого ресурса. Она может быть установлена на множестве дистрибутивов Linux, таких как CentOS 8, на котором мы остановимся в этом руководстве, а также в системах Debian 8 и Ubuntu 16.



Доброго времени суток, читатель!
22 апреля в GitLab выпустили релиз 12.10 и сообщили о том, что теперь CI-процесс может авторизовываться в Hashicorp's Vault через JSON Web Token (JWT), и для авторизации нет необходимости хранить токен для доступа к нужным policy в переменных окружения (или где-либо ещё).

Данная фича показалась нам полезной, поэтому предлагаем перевод соотвествующего туториала из официальной документации GitLab: