Здравствуйте, в данной статье я хотел бы поделиться опытом о том как прошел путь от идеи до готового устройства.
Мне очень нравиться читать Хабр, и вот я наткнулся на статью о том как быстро и без хлопотно можно привязать дозиметр к iphone (статья). Статья написанная lexeresser меня очень заинтересовала и мне захотелось попробовать сделать такую привзяку, но наткнулся на сложности: первый момент — бытовой дозиметр, который описывается купить не так просто, нашел всего два на продаже и они продаются не в России, второй момент — в статье описывалась программа для iphone, а у меня смартфон на Android. Я поставил себе задачу уложиться в 1000 рублей, т.к. дозиметры стоят от 3500 рублей. Чтобы уложиться в бюджет я решил не искать готовое устройство, а сделать самому, а программу для андроида создать. Данный проект я назвал SyGeiger и он не несет коммерческую идею, он просто для фана: Смогу ли я?
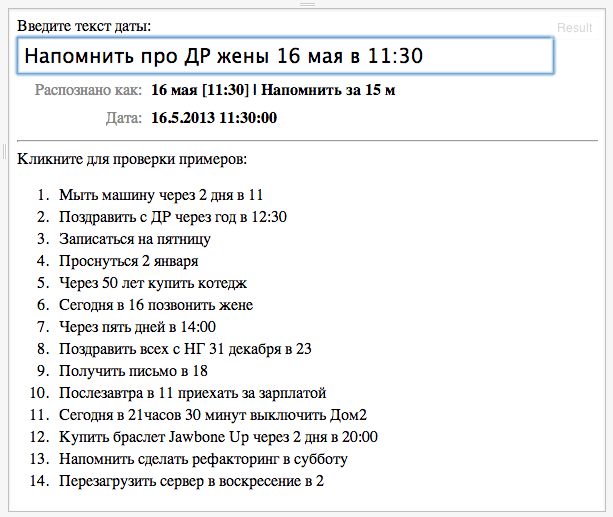






 и
и  ).
).
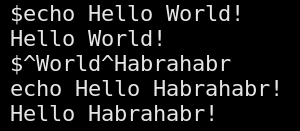 В данном посте я расскажу о наиболее интересных командах, которые могут быть очень полезны при работе в консоли. Однозначных критериев определения какая команда лучше другой — нет, каждый сам для своих условий выбирает лучшее. Я решил построить список команд на основе наиболее рейтинговых приемов работы с консолью от commandlinefu.com, кладовой консольных команд. Результат выполнения одной из таких команд под Linux приведен на картинке. Если заинтересовало, прошу под кат.
В данном посте я расскажу о наиболее интересных командах, которые могут быть очень полезны при работе в консоли. Однозначных критериев определения какая команда лучше другой — нет, каждый сам для своих условий выбирает лучшее. Я решил построить список команд на основе наиболее рейтинговых приемов работы с консолью от commandlinefu.com, кладовой консольных команд. Результат выполнения одной из таких команд под Linux приведен на картинке. Если заинтересовало, прошу под кат.