Используйте глобально уникальные идентификаторы. Клиент всегда должен знать полное состояние системы. Избегайте двойных отрицаний…

AlexeiZhuravlev @AlexeiZhuravlev
Пользователь
GoLand 2020.3 — дамп горутин, запуск табличных тестов, расширенная поддержка Testify
7 min

Привет, Хабр!
Несколько недель назад вышел GoLand 2020.3, последний релиз уходящего года. Сегодня расскажем, почему стоит обновиться на новую версию или попробовать нашу IDE для Go разработчиков.
Коротко: в GoLand 2020.3 вы можете сдампить и отфильтровать горутины приложения, точечно запустить табличные тесты и воспользоваться расширенной поддержкой Testify фреймворка. Помимо этого мы добавили функциональность для редактирования кода, включая поддержку пакета time, улучшения пользовательского интерфейса, много нового для веб-разработки и работы с базами данных, сервис для совместной разработки и парного программирования.
Кстати, узнать о новой функциональности в интерактивной форме можно прямо в IDE. Пройдите урок What's New in GoLand 2020.3 на экране приветствия.
Kafka как хранилище данных: реальный пример от Twitter
6 min
Translation
Привет, Хабр!
Нас давно занимала тема использования Apache Kafka в качестве хранилища данных, рассмотренная с теоретической точки зрения, например, здесь. Тем интереснее предложить вашему вниманию перевод материала из блога Twitter (оригинал — декабрь 2020), в котором описан нетрадиционный вариант использования Kafka в качестве базы данных для обработки и воспроизведения событий. Надеемся, статья будет интересна и натолкнет вас на свежие мысли и решения при работе с Kafka.
Нас давно занимала тема использования Apache Kafka в качестве хранилища данных, рассмотренная с теоретической точки зрения, например, здесь. Тем интереснее предложить вашему вниманию перевод материала из блога Twitter (оригинал — декабрь 2020), в котором описан нетрадиционный вариант использования Kafka в качестве базы данных для обработки и воспроизведения событий. Надеемся, статья будет интересна и натолкнет вас на свежие мысли и решения при работе с Kafka.
Как разрабатывать сотни A/B экспериментов
8 min
А/Б-тестирование — это способ измерить эффективность нового функционала путем сравнения. Вы создаете новый заголовок, кнопку или изображение и показываете их только части аудитории сайта. В течение нескольких недель собираете статистику об использовании нового функционала и на основании этого принимаете решение об открытии новой фичи для 100% пользователей.
Senior Frontend Developer ЦИАН Иван Бабков, который разрабатывал приложения для регистрации доменов, интернет-банкинга и поиска по жилой недвижимости в своем докладе на конференции FrontendConf рассказал об инфраструктуре компании для работы с А/Б-экспериментами, проблемах и путях их решения.

Senior Frontend Developer ЦИАН Иван Бабков, который разрабатывал приложения для регистрации доменов, интернет-банкинга и поиска по жилой недвижимости в своем докладе на конференции FrontendConf рассказал об инфраструктуре компании для работы с А/Б-экспериментами, проблемах и путях их решения.
Apache Kafka – мой конспект
9 min
Это мой конспект, в котором коротко и по сути затрону такие понятия Kafka как:
— Тема (Topic)
— Подписчики (consumer)
— Издатель (producer)
— Группа (group), раздел (partition)
— Потоки (streams)
При изучении Kafka возникали вопросы, ответы на которые мне приходилось эксперементально получать на примерах, вот это и изложено в этом конспекте. Как стартовать и с чего начать я дам одну из ссылок ниже в материалах.
Apache Kafka – диспетчер сообщений на Java платформе. В Kafka есть тема сообщения в которую издатели пишут сообщения и есть подписчики в темах, которые читают эти сообщения, все сообщения в процессе диспетчеризации пишутся на диск и не зависит от потребителей.
— Тема (Topic)
— Подписчики (consumer)
— Издатель (producer)
— Группа (group), раздел (partition)
— Потоки (streams)
Kafka — основное
При изучении Kafka возникали вопросы, ответы на которые мне приходилось эксперементально получать на примерах, вот это и изложено в этом конспекте. Как стартовать и с чего начать я дам одну из ссылок ниже в материалах.
Apache Kafka – диспетчер сообщений на Java платформе. В Kafka есть тема сообщения в которую издатели пишут сообщения и есть подписчики в темах, которые читают эти сообщения, все сообщения в процессе диспетчеризации пишутся на диск и не зависит от потребителей.
Как из PostgreSQL и ClickHouse в Python много, быстро и сразу в numpy
4 min
Разбил много кружек в поисках решения для быстрого получения длинных историй цен для большого количества активов в Python. Ещё имел смелость желать работать с ценами в numpy-массивах, а лучше сразу в pandas.
Стандартные подходы в лоб работали разочаровывающе, что приводило к выполнению запроса к БД в течение 30 секунд и более. Не желая мириться, я нашёл несколько решений, которые полностью меня удовлетворили.
Стандартные подходы в лоб работали разочаровывающе, что приводило к выполнению запроса к БД в течение 30 секунд и более. Не желая мириться, я нашёл несколько решений, которые полностью меня удовлетворили.
На что мы обращаем внимание при расчете статистической значимости A/B-теста
11 min
В Учи.ру мы стараемся даже небольшие улучшения выкатывать A/B-тестом, только за этот учебный год их было больше 250. A/B-тест — мощнейший инструмент тестирования изменений, без которого сложно представить нормальное развитие интернет-продукта. В то же время, несмотря на кажущуюся простоту, при проведении A/B-теста можно допустить серьёзные ошибки как на этапе дизайна эксперимента, так и при подведении итогов. В этой статье я расскажу о некоторых технических моментах проведения теста: как мы определяем срок тестирования, подводим итоги и как избегаем ошибочных результатов при досрочном завершении тестов и при тестировании сразу нескольких гипотез.

Увеличение чувствительности A/Б-тестов с помощью Cuped. Доклад в Яндексе
12 min
CUPED (Controlled-experiment Using Pre-Experiment Data) — техника A/Б-экспериментов, которую стали применять в продакшене сравнительно недавно. Она позволяет увеличить чувствительность метрик за счёт использования данных, полученных ранее. Чем больше чувствительность, тем более слабые изменения можно замечать и учитывать в эксперименте. Первой компанией, внедрившей CUPED, была Microsoft. Теперь этой техникой пользуются многие международные фирмы. В своём докладе Валерий Бабушкин venheads объяснил, в чём заключается смысл CUPED и каких результатов можно достичь, а перед этим разобрал метод стратификации, который также улучшает чувствительность.
— Меня зовут Валерий Бабушкин, я директор по моделированию и анализу данных в X5 Retail Group и советник в Яндекс.Маркете. В свободное время преподаю в Высшей школе экономики и частенько летаю в Казахстан, преподаю в Нацбанке Казахстана.
— Меня зовут Валерий Бабушкин, я директор по моделированию и анализу данных в X5 Retail Group и советник в Яндекс.Маркете. В свободное время преподаю в Высшей школе экономики и частенько летаю в Казахстан, преподаю в Нацбанке Казахстана.
Курс молодого бойца PostgreSQL
13 min
Tutorial

Хочу поделиться полезными приемами работы с PostgreSQL (другие СУБД имеют схожий функционал, но могут иметь иной синтаксис).
Постараюсь охватить множество тем и приемов, которые помогут при работе с данными, стараясь не углубляться в подробное описание того или иного функционала. Я любил подобные статьи, когда обучался самостоятельно. Пришло время
Данный материал будет полезен тем, кто полностью освоил базовые навыки SQL и желает учиться дальше. Советую выполнять и экспериментировать с примерами в pgAdmin'e, я сделал все SQL-запросы выполнимыми без разворачивания каких-либо дампов.
Поехали!
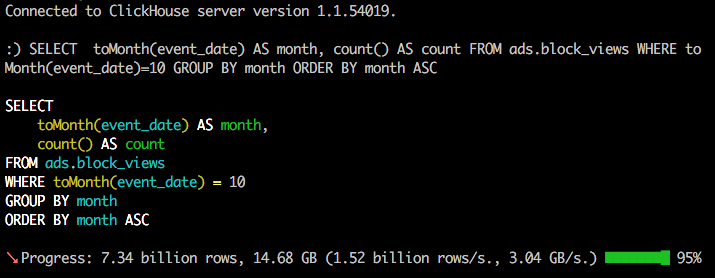
ClickHouse для продвинутых пользователей в вопросах и ответах
44 min
В апреле инженеры Авито собирались на онлайн-посиделки с главным разработчиком ClickHouse Алексеем Миловидовым и Кириллом Шваковым, Golang-разработчиком из компании Integros. Обсуждали, как мы используем систему управления базами данных и какие сложности у нас возникают.
По мотивам встречи мы собрали статью с ответами экспертов на наши и зрительские вопросы про бэкапы, решардинг данных, внешние словари, Golang-драйвер и обновление версий ClickHouse. Она может быть полезна разработчикам, которые уже активно работают с СУБД «Яндекса» и интересуются её настоящим и будущим. По умолчанию ответы Алексея Миловидова, если не написано иное.
Осторожно, под катом много текста. Надеемся, что содержание с вопросами поможет вам сориентироваться.

Как запустить ClickHouse своими силами и выиграть джекпот
15 min
Мы решили описать простой и проверенный путь для тех, кто хочет внедрить аналитическую СУБД ClickHouse своими силами или просто испробовать ClickHouse на собственных данных. Именно этот путь прошли мы сами в новостном агрегаторе СМИ2 и добились впечатляющих результатов.
В предисловии статьи — небольшой рассказ о наших попытках внедрить Druid и InfluxDB. Почему после успешного запуска ClickHouse мы смогли отказаться от использования InfiniDB и Cassandra.
Как я заработал 1 000 000 $ без опыта и связей, а потом потратил их, чтобы сделать свой переводчик
20 min
Как все начиналось
Эта история началась 15 лет назад. Работая программистом в столице, я накапливал деньги и увольнялся, чтобы потом создавать собственные проекты. Для экономии средств уезжал домой, в небольшой родной город, где работал над сайтом для студентов, программой для торговли, играми для мобильных телефонов. Но из-за отсутствия опыта ведения бизнеса это не приносило дохода, и вскоре проекты закрывались. Приходилось снова ехать в столицу и устраиваться на работу. Эта история повторилась несколько раз.
Когда у меня в очередной раз закончились деньги, наступил кризис. Я не смог найти работу, ситуация стала критической. Пришло время посмотреть на все вещи трезвым взглядом. Нужно было честно признаться себе, что я не знаю, какие ниши выбрать для бизнеса. Создавать проекты, которые просто нравятся, — путь в никуда.
Дизайн и подходы создания Big Data пайплайнов
23 min
Translation

(Корень всех зол в data engineering лежит в излишне сложном конвейере обработки данных)
Исторический контекст
Разработка конвейера данных достаточно серьезная задача, а с учетом областей с огромными объемами данных, эта сложность многократно увеличивается. Инструменты и концепции, связанные с большими данными, начали развиваться примерно в начале 2000-х годов, когда масштабы и скорость интернета резко начали возрастать. Компании внезапно обнаружили, что им приходится иметь дело с огромными объемами и скоростью передачи данных. Возможно, одним из пионеров в этой области был Google, инженеры которого боролись с поисковым сканером и индексатором. По сути это по, которое в то время лежало в основе поисковика Google. Поскольку количество веб-сайтов и страниц астрономически росло, Google не мог решить, как масштабировать свой сканер/индексатор, используя существующие вычислительные ресурсы, которые были распределены географически. Ни одна из коммерческих баз данных или технологий в то время не могла масштабироваться быстро и с минимальными затратами, и обе эти технологии были необходимы Google для масштабирования своего основного продукта.
Apache Kafka для чайников
11 min
Данная статья будет полезной тем, кто только начал знакомиться с микросервисной архитектурой и с сервисом Apache Kafka. Материал не претендует на подробный туториал, но поможет быстро начать работу с данной технологией. Я расскажу о том, как установить и настроить Kafka на Windows 10. Также мы создадим проект, используя Intellij IDEA и Spring Boot.
Быстрый поиск по всем пользователям ВК
8 min
Tutorial

Задача:
Нужно пройтись по 650 000 000 пользователям ВК и вытащить только тех, кто живет в Москве. Затем отдельно обработать уже полученные айдишники.
Решение:
- генерация токенов для вк api
- асинхронные запросы
- код проекта в Google Colab (Python)
75 лекций на русском от Y Combinator (из 172)
14 min

Патрик и Джон Коллинсон, основатели Stripe (в 22 года и в 21 год), с капитализацией $35 млрд.
Y Combinator — лучший в мире акселератор для стартапов по количеству единорогов (21), по объему привлеченных инвестиций ($27 млрд) и по капитализации выпускников ($155 млрд). Важно отметить еще то, что среди выпускников YC было несколько основателей моложе 18 лет (и один 20-летний из России).
А ещё Y Combinator выкладывает все свои учебные материалы бесплатно, уже более 10 лет.
Основатели и техдиры миллиардных стартапов Amazon ($1.55 трлн), Facebook ($720 млрд), PayPal ($127 млрд), AirBnb ($40 млрд), Pinterest ($38 млрд), Stripe ($35 млрд), LinkedIn ($26.2 млрд), Slack ($23 млрд), WatsApp ($19 млрд), Doordash ($16 млрд), Twitch ($15 млрд), Netscape ($10 млрд), Sun Microsystems ($7.4 млрд), Zenefits ($4 млрд), Segment ($4 млрд), Box ($2.76 млрд), Quora ($2 млрд), Asana ($1.5 млрд), Zappos ($1.2 млрд), Docker ($1.2 млрд), Pebble, Jawbone, Opsware, Weebly, Yahoo!Mail, Gmail, Mixpanel, Scribd и пр, а так же основатели венчурных фондов Andreessen Horowitz, Cowboy Ventures делятся своим опытом со всем миром. Это контент невероятного качества для тех, кто хочет играть в «высшей лиге», на международном уровне.
Сейчас у Y Combinator 172 видео-лекции в плейлистах: 2012, 2013, 2014 NY, 2014 Europe, 2014 SV, How to Start a Startup (2014 Lectures), 2016, 2017, 2018, Startup Investor School 2018, 2019, 2020. Ниже приведены переводы, субтитры и транскрипты 75 из них.
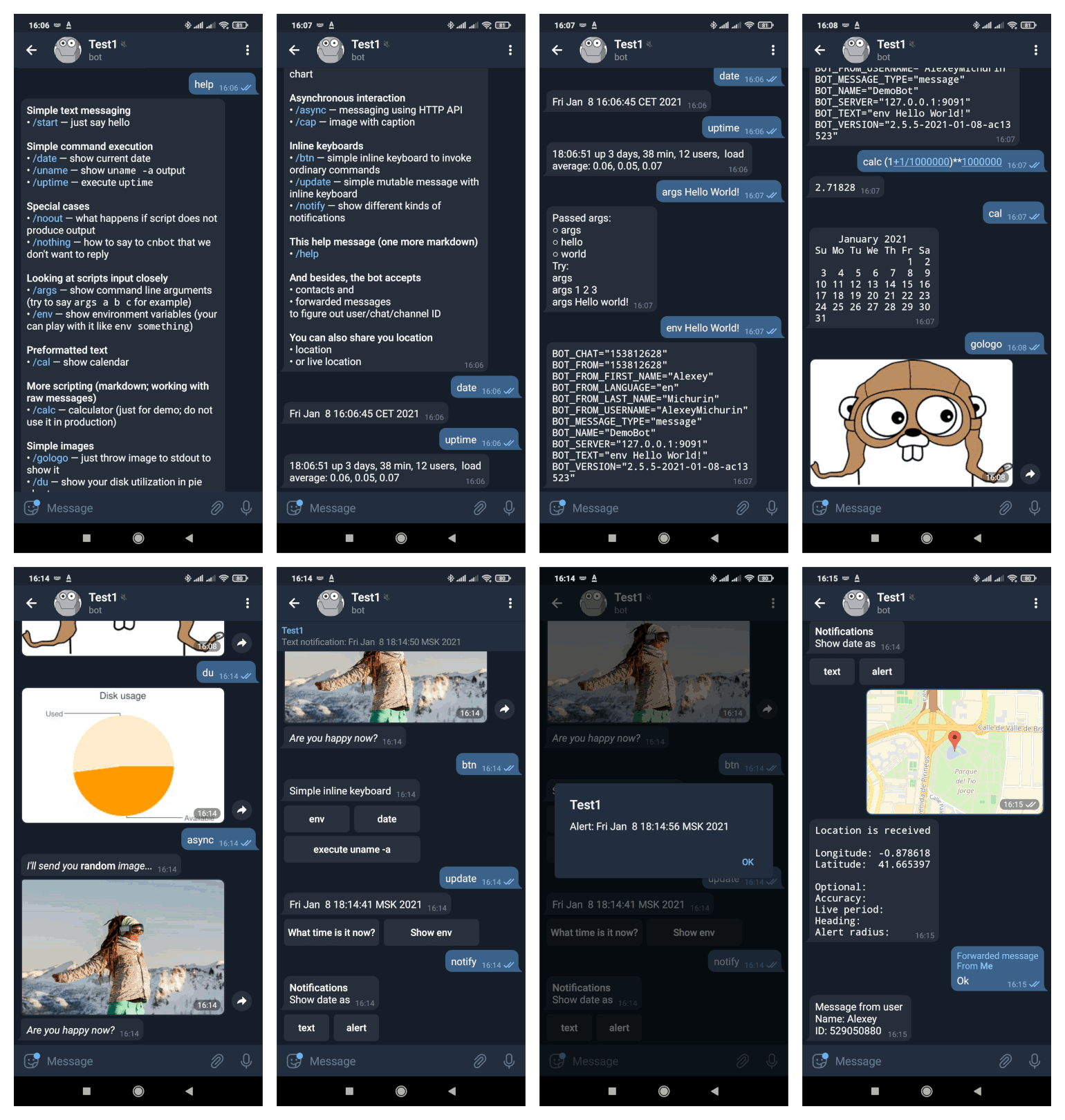
Как превратить любой скрипт в Telegram-бота
6 min
Tutorial
Если вам нужен простенький Telegram bot, способный выполнять скрипты (написанные на любом языке) и отвечать текстом и картинками, то вам под кат. Там вы найдёте рассказ о бот-движке, который делает то, что вам надо.
Удобное логирование на бэкенде. Доклад Яндекса
12 min
Что-то всегда идет не по плану. Приходится отвечать на вопросы, «Что сломалось?», «Почему тормозит?» и «Почему мы не увидели этого раньше?». На примере простого приложения Даниил Галиев zefirior из Яндекс.Путешествий показал, как отвечать на эти вопросы и какие инструменты в этом помогут. Настроим логирование, прикрутим трассировку, разложим ошибки, и все это в удобном интерфейсе.
— Давайте начинать. Я расскажу об удобном логировании и инфраструктуре вокруг логирования, которую можно развернуть, чтобы вам с вашим приложением и его жизненным циклом было удобно жить.
— Давайте начинать. Я расскажу об удобном логировании и инфраструктуре вокруг логирования, которую можно развернуть, чтобы вам с вашим приложением и его жизненным циклом было удобно жить.
Определяем пол и возраст по фото
2 min

В практике внутреннего аудита встречаются задачи, при которых необходимо осуществить проверку по выявлению некорректного ввода данных о клиенте. Одной из таких проблем может быть несоответствие введенных данных и фото клиента, в момент оформления продукта.
К примеру, имеется следующая информация: пол, возраст и ссылка на фото. Для проверки соответствия воспользуемся библиотекой py-agender языка Python.
Работа библиотеки осуществляется в два этапа. На первом, opencv определяет расположение лица на фото. На втором, нейронная сеть архитектуры EfficientNetB3, которая обучена на наборе данных UTKFace DataSet, определяет пол и возраст обладателя лица на фото.
Салют от Сбера в Яндекс.Облаке
7 min
Tutorial

В сентябре 2020 г. Сбербанк переименовал себя просто в Сбер (т.н. ребрендинг), и на радостях запустил собственную платформу голосовых ассистентов под названием Салют. Особенностью Салюта является наличие сразу трёх голосовых ассистентов на выбор пользователей: Сбер — мужчина, стиль обращения на «вы», Афина — женщина, обращается также на «вы», и Джой — девушка с дружеским «ты».
Сбер (банк, не его тёзка — голосовой ассистент) открыл эту платформу для сторонних разработчиков, пригласив их делать для неё приложения, т.н. смартапы — аналог навыков голосовой помощницы Алисы, и учредив для них конкурс с весьма щедрым призовым фондом. В этом туториале мы рассмотрим как сделать смартап на Node.js, разместить его код в Яндекс.Облаке (используя функции), и, наконец, создать проект в Салюте, пройти там модерацию, и опубликовать наш смартап, чтобы он стал общедоступным.