Идет 2020 год. Если вам нужно пояснение, что такое микросервисы — лучше потратьте свое драгоценное время на что-то другое. Но если вы впечатлены историями успеха о микросервисах и хотите нырнуть в "панацею" с головой — продолжайте читать. Прошу прощения, будет немного длинновато (не очень, прим. переводчика).

Константин Садовский @AsmodeusL
User
Как найти удаленную работу в США и Европе: списки ~1000 компаний, полезные инструменты для поиска + личный опыт инженера
6 min

Изображение: Unsplash
Вопрос поиска удаленной работы в хороших компаниях из США и Европы актуален всегда – не все хотят переезжать в другую страну, а участвовать в интересных проектах хочется в любое время. В период пандемии, когда перемещение между странами и иммиграция серьезно усложнились, и экономического кризиса, который во многих странах только разгорается, желающих найти удаленку в американской или европейской компании станет еще больше.
Я решил разобраться в том, что для этого нужно сделать инженеру с постсоветского пространства. Для этого я изучил компании, которые предлагают remote-позиции для ИТ-специалистов, нашел несколько полезных сервисов и поговорил с Никитой Львовым, инженером, который как раз недавно нашел такую работу и согласился поделиться опытом. Надеюсь, получилось полезно. Поехали!
SQL HowTo: 1000 и один способ агрегации
5 min
Наш СБИС, как и другие системы управления бизнесом, не обходится без формирования отчетов — каждый руководитель любит сводные цифры, особенно всякие суммы по разделам и красивые "Итого".
А чтобы эти итоги собрать, необходимо по исходным данным вычислить значение некоторой агрегатной функции: количество, сумма, среднее, минимум, максимум,… — и, как правило, не одной.
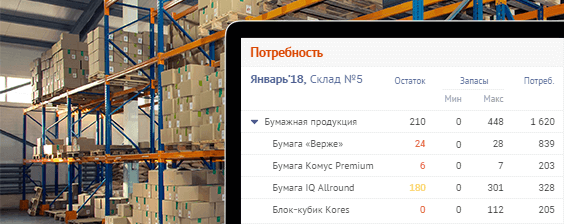
Сегодня мы рассмотрим некоторые способы, с помощью которых можно вычислить агрегаты в PostgreSQL или ускорить выполнение SQL-запроса.
А чтобы эти итоги собрать, необходимо по исходным данным вычислить значение некоторой агрегатной функции: количество, сумма, среднее, минимум, максимум,… — и, как правило, не одной.
Сегодня мы рассмотрим некоторые способы, с помощью которых можно вычислить агрегаты в PostgreSQL или ускорить выполнение SQL-запроса.
Zabbix — расширяем макро границы
5 min
Делая решение для клиента, возникло 2 задачи, которые хотелось решить красиво и штатным функционалом Zabbix.
Задача 1. Отслеживание актуальной версии прошивки на роутерах Mikrotik.
Задача решается легко — добавлением в шаблон HTTP агента. Агент получает актуальную версию с сайта Mikrotik, а триггер сравнивает актуальную версию с текущей и в случае расхождения выдает алерт.
Когда у вас 10 роутеров, такой алгоритм не критичен, а что делать с 3000 роутеров? Слать 3000 запросов на сервер? Работать, конечно, такая схема будет, но сама идея 3000 запросов меня не устраивала, хотелось найти другое решение. К тому же, недостаток в подобном алгоритме все-таки был: другая сторона может посчитать такое количество запросов с одного IP за DoS атаку, могут просто забанить.
Задача 2. Использование сессии авторизации в разных HTTP агентах.
Когда через HTTP агент нужно получать информацию с «закрытых» страниц, нужна кука авторизации. Для этого обычно существует стандартная форма авторизации с парой «логин/пароль» и установкой ID сессии в куку.
Но есть проблема, нельзя из одного айтема HTTP агента обратиться к данным другого айтема для подстановки этого значение в Header.
Существует еще «Веб сценарий», у него другое ограничение, он не дает получить контент для анализа и дальнейшего сохранения. Можно только проверить наличие необходимых переменных на страницах или передавать ранее полученные переменные между шагами веб сценария.
Немного поразмыслив над этими задачами, решил использовать макросы, которые отлично видны в любой части системы мониторинга: в шаблонах, хостах, триггерах или айтемах. А обновлять макросы можно через API веб интерфейса.
Задача 1. Отслеживание актуальной версии прошивки на роутерах Mikrotik.
Задача решается легко — добавлением в шаблон HTTP агента. Агент получает актуальную версию с сайта Mikrotik, а триггер сравнивает актуальную версию с текущей и в случае расхождения выдает алерт.
Когда у вас 10 роутеров, такой алгоритм не критичен, а что делать с 3000 роутеров? Слать 3000 запросов на сервер? Работать, конечно, такая схема будет, но сама идея 3000 запросов меня не устраивала, хотелось найти другое решение. К тому же, недостаток в подобном алгоритме все-таки был: другая сторона может посчитать такое количество запросов с одного IP за DoS атаку, могут просто забанить.
Задача 2. Использование сессии авторизации в разных HTTP агентах.
Когда через HTTP агент нужно получать информацию с «закрытых» страниц, нужна кука авторизации. Для этого обычно существует стандартная форма авторизации с парой «логин/пароль» и установкой ID сессии в куку.
Но есть проблема, нельзя из одного айтема HTTP агента обратиться к данным другого айтема для подстановки этого значение в Header.
Существует еще «Веб сценарий», у него другое ограничение, он не дает получить контент для анализа и дальнейшего сохранения. Можно только проверить наличие необходимых переменных на страницах или передавать ранее полученные переменные между шагами веб сценария.
Немного поразмыслив над этими задачами, решил использовать макросы, которые отлично видны в любой части системы мониторинга: в шаблонах, хостах, триггерах или айтемах. А обновлять макросы можно через API веб интерфейса.
Все о коллекциях в Oracle
12 min
Статья имеет довольно таки тезисный стиль. Более подробное содержание можно найти в приложенном внизу статьи видео с записью лекции по коллекциям Oracle.
Коллекции присутствую в том или ином виде в большинстве языков программирования и везде имеют схожую суть в плане использования. А именно – позволяют хранить набор объектов одного типа и проводить над всем набором какие-либо действия, либо в цикле проводить однотипные действия со всеми элементами набора.
Таким же образом коллекции используются и в Oracle.
Коллекции присутствую в том или ином виде в большинстве языков программирования и везде имеют схожую суть в плане использования. А именно – позволяют хранить набор объектов одного типа и проводить над всем набором какие-либо действия, либо в цикле проводить однотипные действия со всеми элементами набора.
Таким же образом коллекции используются и в Oracle.
Содержание статьи
- Общие сведения о коллекциях в pl/sql
- Типы коллекций
- Ассоциативный массив
- Varray
- Nested table
- Set operations с nested tables
- Логические операции с коллекциями
- Методы коллекций
- Bulk Collect
- Цикл forall
- Collection exceptions
- DBMS_SESSION.FREE_UNUSED_USER_MEMORY
Почему список в кортеже ведет себя странно в Python?
3 min
В языках программирования меня всегда интересовало их внутреннее устройство. Как работает тот или иной оператор? Почему лучше писать так, а не иначе? Подобные вопросы не всегда помогают решить задачу «здесь и сейчас», но в долгосрочной перспективе формируют общую картину языка программирования. Сегодня я хочу поделиться результатом одного из таких погружений и ответить на вопрос, что происходит при модификации
tuple'а в list'е.Как живется в США «неайтишникам». Другая сторона
10 min

На Хабре есть не только айтишники. Тут и электрики, и схемотехники, и химики, и маркетологи и кого только нет. И возможность переезда в другую страну в качестве специалиста широкого профиля интересна и им тоже. В довесок к истории Дудя и аналогичным статьям я хочу рассказать свою историю про переезд в США, на противоположный от Калифорнии берег с противоположной от IT профессии. Про жизнь, траты, поиск и смены работы и перспективы. Мне 36, я по образованию биотехнолог, семья — два человека, английский язык — так себе. Живу в Северной Каролине почти два года.
Поскольку написанного вышло много, вот короткая версия. При переезде практически гарантировано снижение социального статуса. Прожить можно на $1500. Средняя зарплата «неайтишника» $30к-50к в год. Средняя стоимость дома $200к. Получить медицинскую страховку бесплатно можно. Много плюшек от государства. Поиск нормальной работы очень нетривиален. Язык сам не учится, но есть бесплатные курсы. Жить комфортно. Наше образование никому не нужно. Очень многие мечтают о карьере в IT.
Важно! Все что я тут пишу это исключительно мой опыт и мое мнение. Я не претендую на истину в последней инстанции, а просто рассказываю как это было у меня, тем более что у всех неайтишных мигрантов весь путь довольно похожий.
ICQ New: инструкция по разведению ботов
10 min

Каждый раз, заходя в мессенджер, мы встречаем ботов в самых различных своих проявлениях. Одни рассказывают про погоду, другие разыгрывают бургеры, а третьи так и вообще кидают мемы под настроение. Наверняка у многих из вас проскакивала мысль: «А не сделать ли мне своего бота?». К сожалению, частенько такие мысли разбиваются о непонимание, как вообще сделать бота. Наверное, для этого нужно быть крутым айтишником и разбираться в миллионах технологий? На самом деле, нет. И сегодня мы попытаемся показать, что создание своего бота — процесс простой и понятный. Разберем полный цикл создания бота, от получения необходимых данных из мессенджера до написания кода и его запуска на сервере.
Некоторое время назад в ICQ сильно обновилась платформа ботов. Она стала более дружелюбной, понятной и удобной. С помощью Python-библиотеки от разработчиков мы и будем создавать своего первого бота.
In-memory архитектура для веб-сервисов: основы технологии и принципы
5 min
In-Memory — набор концепций хранения данных, когда они сохраняются в оперативной памяти приложения, а диск используется для бэкапа. В классических подходах данные хранятся на диске, а память — в кэше. Например, веб-приложение с бэкендом для обработки данных запрашивает их в хранилище: получает, трансформирует, а по сети перегоняется много данных. В In-Memory вычисления отправляются к данным — в хранилище, где обрабатываются и сеть нагружается меньше.
Благодаря своей архитектуре, в In-Memory в разы, а иногда и на порядки, быстрее скорость доступа к данным. Например, аналитики банка хотят посмотреть в аналитическом приложении отчет по выданным кредитам в динамике по дням за прошлый год. Этот процесс на классической СУБД займет минуты, а c In-Memory появится почти сразу. Всё потому, что подход позволяет кэшировать гораздо больше информации и она хранится в оперативной памяти «под рукой». Приложению не нужно запрашивать данные у жесткого диска, доступность которых ограничена скоростью сети и диска.
Какие еще возможности доступны с In-Memory и что это за подход, расскажет Владимир Плигин — инженер компании GridGain. Этот обзорный материал будет полезен разработчикам бэкенда веб-приложений, которые не работали с In-Memory и хотят попробовать, или интересуются современными трендами разработки программных решений и проектированием архитектуры.
Примечание. Статья основана на расшифровке доклада Владимира на конференции #GetIT Conf. До введения самоизоляции мы регулярно проводили митапы и конференции для разработчиков в Москве и Санкт-Петербурге: обсуждали тренды, актуальные вопросы разработки, проблемы и их решения. Сейчас конференции не провести, зато самое время поделиться полезными материалами с прошлых.
Благодаря своей архитектуре, в In-Memory в разы, а иногда и на порядки, быстрее скорость доступа к данным. Например, аналитики банка хотят посмотреть в аналитическом приложении отчет по выданным кредитам в динамике по дням за прошлый год. Этот процесс на классической СУБД займет минуты, а c In-Memory появится почти сразу. Всё потому, что подход позволяет кэшировать гораздо больше информации и она хранится в оперативной памяти «под рукой». Приложению не нужно запрашивать данные у жесткого диска, доступность которых ограничена скоростью сети и диска.
Какие еще возможности доступны с In-Memory и что это за подход, расскажет Владимир Плигин — инженер компании GridGain. Этот обзорный материал будет полезен разработчикам бэкенда веб-приложений, которые не работали с In-Memory и хотят попробовать, или интересуются современными трендами разработки программных решений и проектированием архитектуры.
Примечание. Статья основана на расшифровке доклада Владимира на конференции #GetIT Conf. До введения самоизоляции мы регулярно проводили митапы и конференции для разработчиков в Москве и Санкт-Петербурге: обсуждали тренды, актуальные вопросы разработки, проблемы и их решения. Сейчас конференции не провести, зато самое время поделиться полезными материалами с прошлых.
Как синхронизация времени стала безопасной
10 min

Как сделать так, чтобы время per se не врало, если у вас есть миллион больших и малых устройств, взаимодействующих по TCP/IP? Ведь на каждом из них есть часы, а время должно быть верным на всех. Эту проблему без ntp невозможно обойти.
Представим себе на одну минуту, что в одном сегменте промышленной ИТ инфраструктуры возникли трудности с синхронизацией сервисов по времени. Немедленно начинает сбоить кластерный стек Enterprise ПО, распадаются домены, мастера и Standby узлы безуспешно стремятся восстановить status quo.
Возможна также ситуация, когда злоумышленник намеренно старается сбить время через MiTM, или DDOS атаку. В такой ситуации может произойти все что угодно:
- истечет срок действия паролей учетных записей пользователей;
- истечет срок действия X.509 сертификатов;
- двухфакторная аутентификация TOTP перестанет работать;
- бэкапы «устареют» и система удалит их;
- сломается DNSSec.
Понятно, что каждый первый департамент ИТ заинтересован в надежной работе служб синхронизации времени, и хорошо бы они были надежны и безопасны в промышленной эксплуатации.
Глоссарий терминов Oracle: история создания
3 min
Приветствуем всех читателей нашего хаба!
Как и обещали, рассказываем о глоссарии терминов Oracle, который был создан командой технических специалистов РДТЕХ и сейчас доступен всем, кто работает с базами данных. Глоссарий размещен в свободном доступе на нашем сайте и на данный момент содержит 14 537 терминов.
Словари, конечно, есть, но при переводе узкоспециализированных текстов, например, материалов по медицине или технической документации, а также если текста очень много и над разными частями перевода работают разные люди, без глоссария не обойтись.
Глоссарий сам по себе – очень важная часть процесса перевода, обеспечивающая единообразие терминов во всей переводимой документации, вне зависимости от количества переводчиков и их сменяемости.

Как и обещали, рассказываем о глоссарии терминов Oracle, который был создан командой технических специалистов РДТЕХ и сейчас доступен всем, кто работает с базами данных. Глоссарий размещен в свободном доступе на нашем сайте и на данный момент содержит 14 537 терминов.
Для чего вообще нужен глоссарий, если есть словари?
Словари, конечно, есть, но при переводе узкоспециализированных текстов, например, материалов по медицине или технической документации, а также если текста очень много и над разными частями перевода работают разные люди, без глоссария не обойтись.
Глоссарий сам по себе – очень важная часть процесса перевода, обеспечивающая единообразие терминов во всей переводимой документации, вне зависимости от количества переводчиков и их сменяемости.
Почему функциональное программирование такое сложное
15 min
Tutorial
Я несколько раз начинал читать статьи из серии «Введение в функциональное программирование», «Введение в Теорию Категорий» и даже «Введение в Лямбда Исчисление». Причем и на русском, и на английском. Каждый раз впечатление было очень сходным: во-первых, много новых непонятных слов; во-вторых, много новых определений, которые возникают из ниоткуда; в-третьих, совершенно непонятно, как это использовать.
Самым непонятным и зубодробительным оказалось, наверное, Теория Категорий. Я освоился в ней только с третьего подхода. В первые два раза я честно все прочитал, кажется понял, но т.к. никакой связки с реальной жизнью она не имела, то спустя неделю она благополучно полностью выветривалась.
Попытки использовать как-то в работе изученные концепции разбивались о полное непонимание, как применить полученное глубокое знание. Ведь, напомню, что парадигму ФП (где-то удобнее, где-то не очень, но) можно использовать практически в любом ЯП, совсем необязательно для этого изучать условный Хаскель.
Все нововведения Windows 10 2004 (20H1)
8 min
Translation
Сегодня вечером был выпущен финальный ISO-образ Windows 10 2004 (20H1). Им стал билд за номером 19041.208.vb_release_svc_im.200416-2050. Образы для разработчиков уже доступны на MSDN как вскоре и сами знаете где.
Как PostgreSQL работает с диском. Илья Космодемьянский
20 min
Расшифровка доклада 2014 года Ильи Космодемьянского "Как PostgreSQL работает с диском".
Часть поста, конечно, устарела, но здесь рассмотрены фундаментальные моменты PostgreSQL при работе с диском, которые актуальны и сейчас.
Диски, память, цена, процессор — в таком порядке смотрят на характеристики сервера админы, покупающие машину под базу данных. Как эти характеристики взаимосвязаны? Почему именно они?
В докладе будет объяснено, для чего нужен диск базе данных вообще, как PostgreSQL взаимодействует с ним и в чем заключаются особенности PostgreSQL по сравнению с другими базами.
"Железо", настройки операционной системы, файловой системы и PostgreSQL: как и для чего выбирать хороший setup, что делать, если конфигурация "железа" не оптимальна, и какие ошибки могут сделать бесполезным самый дорогой RAID-контроллер. Увлекательное путешествие в мир батареек, "грязных" и "чистых" страниц, хороших и плохих SSD-дисков, покрасневших графиков мониторинга и ночных кошмаров системных администраторов.

Про перевод слов «полезно»/«пользоваться» без use/useful
4 min
Tutorial

В телеграм-комментариях нас попросили сделать подборку фраз по тому, как переводить слова на тему «пользы» без слова use. Нам показалась эта тема любопытной, и мы ее копнули.
Вариантов оказалось немыслимо много, поэтому мы выбрали только наиболее частотные, да и то просмотрели не все (там получилось свыше 500 страниц цитат, мы просмотрели около 200-300). Как обычно, разложили по полкам, смотрите.
Слова
Good, best
Я попытался собрать самые полезные из них в одном месте…
I have tried to gather together the best of these into one place…
Linux tuning to improve PostgreSQL performance. Илья Космодемьянский
19 min
Расшифровка доклада 2015 года Ильи Космодемьянского "Linux tuning to improve PostgreSQL performance"
Disclaimer: Замечу что доклад этот датирован ноябрем 2015 года — прошло больше 4 лет и прошло много времени. Рассматриваемая в докладе версия 9.4 уже не поддерживается. За прошедшие 4 года вышло 5 новых релизов PostgreSQL вышло и 15 версий ядра Linux. Если переписывать эти места, то получится в итоге другой доклад. Но здесь рассмотрен фундаментальный тюнинг Linux для PostgreSQL, который актуален и сейчас.

Что нового в Zabbix 5.0
12 min
В середине мая вышла версия Zabbix 5.0, и мы организовали серию онлайн митапов на разных языках с целью наглядно продемонстрировать сообществу все изменения и нововведения. Предлагаем вам ознакомиться с докладом исполнительного директора и создателя Zabbix Алексея Владышева, в котором он пошагово рассказал, что нового в Zabbix 5.0.

Домашний интернет-шлюз. Начальная настройка 6-портового мини-компьютера на Ubuntu Server 20.04 LTS
5 min

На просторах интернета присутствует бесчисленное количество информации касательно настройки сервера на Ubuntu, но на каждом шагу можно встретить неочевидные для новичка моменты. Я хочу поделиться своим опытом и, возможно, решить чью-то проблему. В статье будет рассказано, как настроить многопортовый сервер (6 портов): Netplan, DHCP-сервер, UFW(Uncomplicated Firewall). А теперь обо всем по порядку.
Топ-10 причин для перехода в Oracle Cloud. Как бизнесу ускорить инновации?
9 min
Привет, Хабр!
Сегодня хотим поделиться со всеми, кому интересна облачная тема, переводом whitepaper от Oracle на тему перехода на облачную инфраструктуру. За перевод благодарим нашего коллегу и постоянного хаброавтора obieesupport.
РДТЕХ — один из старейших партнеров Oracle в России (первое партнерское соглашение между компаниями было подписано в 1993 году). Сегодня наша компания имеет высший партнерский статус Oracle Platinum Partner, а Учебный центр РДТЕХ — один из главных центров авторизованного обучения Oracle в России (думаем, кто-то из числа наших читателей посещал курсы в нашем Учебном центре или даже учится в нем сейчас дистанционно).
Еще наши коллеги создали легендарный глоссарий терминов Oracle, которым пользуются многие представители «базоданческого сообщества» (спойлер: в одном из последующих постов мы расскажем подробнее о глоссарии).
А сейчас предлагаем углубиться в лонгрид по облачной инфраструктуре Oracle и узнать, как облака и автономная база данных Oracle ускоряют внедрение инноваций в бизнесе. Оригинал «белой книги» можно также скачать на нашем сайте.

Сегодня хотим поделиться со всеми, кому интересна облачная тема, переводом whitepaper от Oracle на тему перехода на облачную инфраструктуру. За перевод благодарим нашего коллегу и постоянного хаброавтора obieesupport.
РДТЕХ — один из старейших партнеров Oracle в России (первое партнерское соглашение между компаниями было подписано в 1993 году). Сегодня наша компания имеет высший партнерский статус Oracle Platinum Partner, а Учебный центр РДТЕХ — один из главных центров авторизованного обучения Oracle в России (думаем, кто-то из числа наших читателей посещал курсы в нашем Учебном центре или даже учится в нем сейчас дистанционно).
Еще наши коллеги создали легендарный глоссарий терминов Oracle, которым пользуются многие представители «базоданческого сообщества» (спойлер: в одном из последующих постов мы расскажем подробнее о глоссарии).
А сейчас предлагаем углубиться в лонгрид по облачной инфраструктуре Oracle и узнать, как облака и автономная база данных Oracle ускоряют внедрение инноваций в бизнесе. Оригинал «белой книги» можно также скачать на нашем сайте.
Resolve IP адресов в Linux: понятное и детальное описание
12 min
Настройка сетевого взаимодействия сервисов не самая простая задача и часто осуществляется без глубокого понимания как требуется настраивать систему и какие настройки на что влияют. После миграции сервисов в docker контейнерах с centos 6 на centos 7 я столкнулся со странным поведением вебсервера: он пытался присоединиться к сервису по IPv6, а сервис же слушал только IPv4 адрес. Стандартный совет в такой ситуации — отключить поддержку IPv6. Но это не поможет в ряде случаев. Каких? В этой статье я задался целью собрать и детально объяснить как приложения resolve'ят адреса.