
Когда участники HighLoad++ пришли на доклад Александра Крашенинникова, они надеялись услышать про обработку 1 600 000 событий в секунду. Ожидания не оправдались… Потому что во время подготовки к выступлению эта цифра улетела до 1 800 000 — так, на HighLoad++ реальность превосходит ожидания.
3 года назад Александр рассказывал, как в Badoo построили масштабируемую систему near-realtime обработки событий. С тех пор она эволюционировала, в процессе росли объёмы, приходилось решать задачи масштабирования и отказоустойчивости, а в определённый момент потребовались радикальные меры — смена технологического стека.

Из расшифровки вы узнаете, как в Badoo заменили связку Spark + Hadoop на ClickHouse, в 3 раза сэкономили железо и увеличили нагрузку в 6 раз, зачем и какими средствами собирать статистику в проекте, и что с этими данными потом делать.
О спикере: Александр Крашенинников (alexkrash) — Head of Data Engineering в Badoo. Занимается BI-инфраструктурой, масштабированием под нагрузки, руководит командами, которые строят инфраструктуру обработки данных. Обожает всё распределённое: Hadoop, Spark, ClickHouse. Уверен, что классные распределенные системы можно готовить из OpenSource.
3 года назад Александр рассказывал, как в Badoo построили масштабируемую систему near-realtime обработки событий. С тех пор она эволюционировала, в процессе росли объёмы, приходилось решать задачи масштабирования и отказоустойчивости, а в определённый момент потребовались радикальные меры — смена технологического стека.
Из расшифровки вы узнаете, как в Badoo заменили связку Spark + Hadoop на ClickHouse, в 3 раза сэкономили железо и увеличили нагрузку в 6 раз, зачем и какими средствами собирать статистику в проекте, и что с этими данными потом делать.
О спикере: Александр Крашенинников (alexkrash) — Head of Data Engineering в Badoo. Занимается BI-инфраструктурой, масштабированием под нагрузки, руководит командами, которые строят инфраструктуру обработки данных. Обожает всё распределённое: Hadoop, Spark, ClickHouse. Уверен, что классные распределенные системы можно готовить из OpenSource.

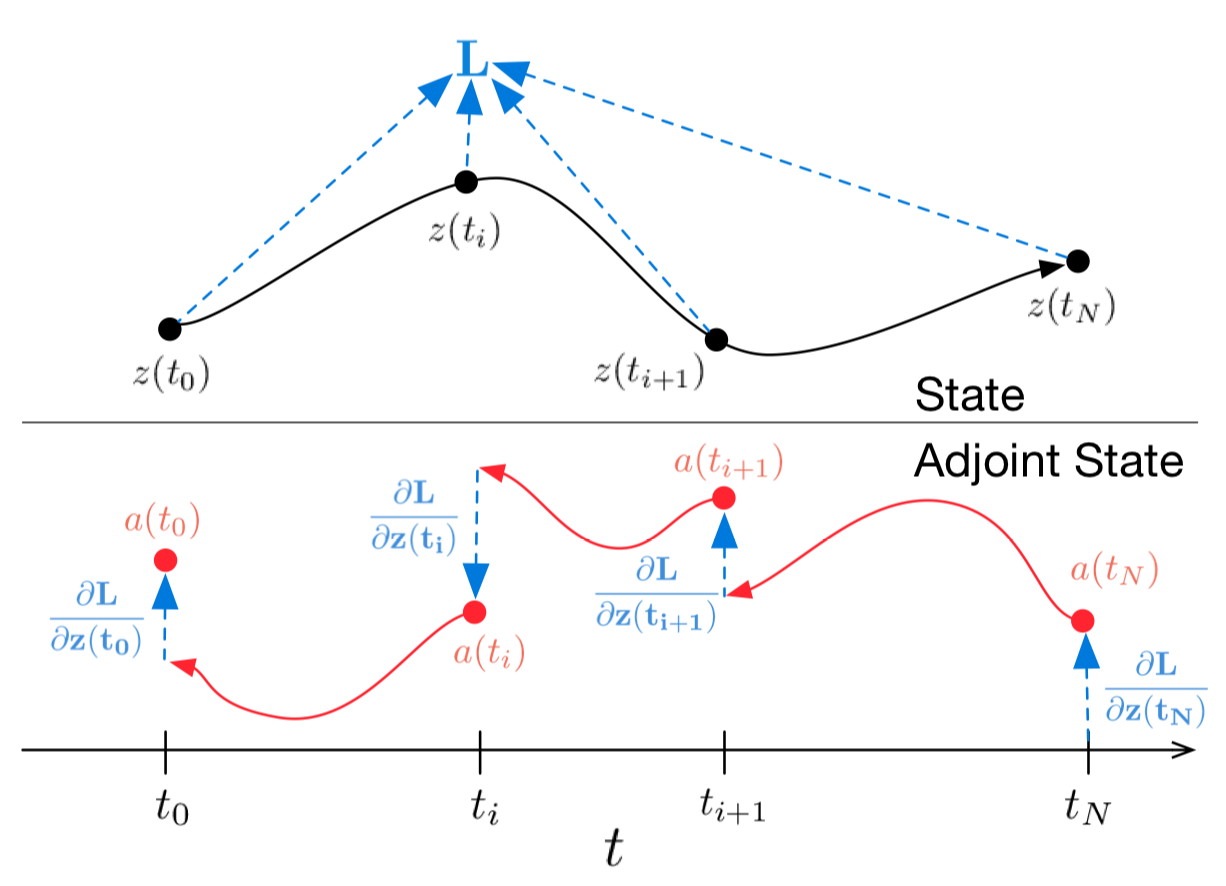










 Современные проекты по оптимизации и автоматизации бизнес-процессов, как правило, предполагают на начальном этапе анализ больших объемов документов Заказчика с целью моделирования на их основе бизнес-процессов «as-is» в сжатые сроки. Перечень анализируемых документов может включать нормативно-правовые акты, отраслевые стандарты, протоколы интервью, регламенты, положения, технические задания и другие корпоративные документы.
Современные проекты по оптимизации и автоматизации бизнес-процессов, как правило, предполагают на начальном этапе анализ больших объемов документов Заказчика с целью моделирования на их основе бизнес-процессов «as-is» в сжатые сроки. Перечень анализируемых документов может включать нормативно-правовые акты, отраслевые стандарты, протоколы интервью, регламенты, положения, технические задания и другие корпоративные документы.