Привет Хабр.
В первой части была рассмотрена некоторая статистика и опубликован рейтинг статей этого сайта. Во второй части будут рассмотрены другие статистические закономерности этого года, которые мне показались интересными, а также будет опубликован рейтинг авторов за этот, 2019 год.
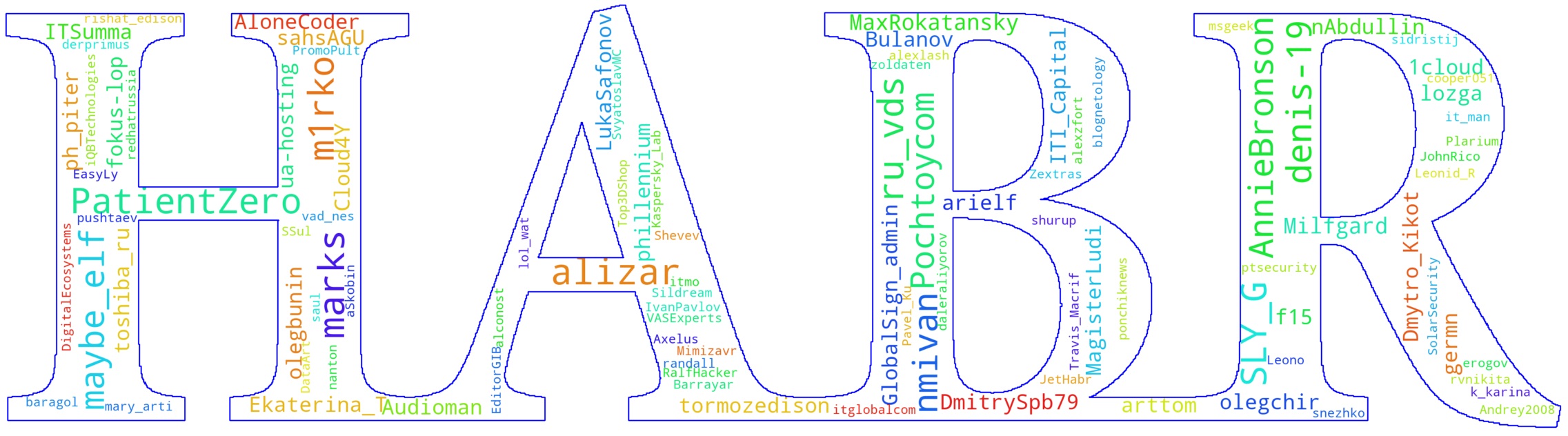
Первая часть рассчитана на читателей сайта, эта будет более интересна авторам, но и остальные надеюсь, найдут что-нибудь полезное — статьи авторов, попавших в рейтинг, определенно имеет смысл прочитать.
Продолжение под катом.
В первой части была рассмотрена некоторая статистика и опубликован рейтинг статей этого сайта. Во второй части будут рассмотрены другие статистические закономерности этого года, которые мне показались интересными, а также будет опубликован рейтинг авторов за этот, 2019 год.
Первая часть рассчитана на читателей сайта, эта будет более интересна авторам, но и остальные надеюсь, найдут что-нибудь полезное — статьи авторов, попавших в рейтинг, определенно имеет смысл прочитать.
Продолжение под катом.