Comments 795
Доступно всё рассказано, и ни одного упоминания монад — спасибо!
Но, определения в начале статьи всё-таки отличаются от общепринятых (см википедию):
- Функциональная программа — программа, состоящая из чистых функций
- Функция f является чистой если выражение f(x) является ссылочно прозрачным для всех ссылочно прозрачных x
Есть ссылки на первоисточники этих определений?
Доступно всё рассказано, и ни одного упоминания монад — спасибо!
Про монады расскажу в следующий раз (если увижу что эта статья зашла), они совсем не такие страшные как кажется. Не сложнее того что уже в статье написано. Не знаю почему, но видимо ФПшникам нравится нагонять страху. А на самом деле монада — это просто интерфейс с парой методов. Но это недостаточно магически, поэтоум обязательно нужно запудрить мозги про моноид в категории эндофункторов. Тогда собеседнику сразу станет страшно, а значит вы победили)
Есть ссылки на первоисточники этих определений?
Я взял определения всё из той же книги. Судя по тому как я сейчас понимаю эти вещи, определения вполне точные. Самое главное, в отличие от субъективных оценочных суждений и смутных интуитивных представлений, эти свойства можно объективно проверять, нужно только определиться, какие эффекты совершаемые программой мы считаем важными (запись в логи/хождение в БД/совершение HTTP запросов/...), а какие — нет (нагревание процессора/порядок вычисления аргументов/...)
Монада это переопределенная функция композиции функций. Все остальное от лукавого.
А ещё функтор и аппликативный функтор. И ещё законы там всякие должны выполняться.
На самом деле, не совсем. Есть много вещей, которые являются формально не монадами, а чем-то похожим (ну, например, потому что соответствующий "функтор" — нифига не функтор, а про выполнение монадических законов я вообще молчу, они постоянно нарушаются в реальных монадах) и их можно спокойно считать монадами и использовать как монады, несмотря на то, что монадами они не являются. Так что с точки зрения прикладной монада — это именно интерфейс. И тот факт, что для этого интерфейса не выполняются какие-то специфические доп. условия, не накладывает каких-либо ограничений на основные варианты его использования.
Иными словами, если вы говорите "монада" в контексте математическом (теоркат и вот это вот все) — то, конечно, тут вполне строго и четкое определение. Если же это контекст прикладного программирования — этими факторами можно пренебречь (и постоянно на практике пренебрегается).
Можно пример того, что используется как монада, но не монада? Просто мне тяжело представить, как можно пренебречь, например, отсутствием ассоциативности.
Ну, вот я например недавно использовал монадический интерфейс для сетевого взаимодействия, чтобы работать с запросами в виде аналогичном x <- query1, y <- query2, return x + y (ну для примера), надо это было в силу не совсем тривиального процесса отправки и получения ответа. Если у нас query — это промисы (ну как при обычных хттп запросах), то мы получаем, с-но, промис-монаду (которая, к слову, в том же js не является монадой из-за некоторых особенностей семантики, нарушающих монадические законы. но всем пофиг, кто вообще знает, что promise в js — не монада?). В моем же случае у меня типы x и query1 были типами произвольных сообщений (x тип приходящих, query — тип исходящих), с-но, не было никакого соответствующего функтора и даже нельзя было написать сколько-нибудь осмысленные return и fmap. Но, несмотря на то, что полученная конструкция была прям уж совсем не монада, взаимодействие с ней выглядит вполне монадически ну и концептуально оно тоже вполне монада.
Как же тогда у вас в коде return x+y используется, когда нельзя осмысленный return написать?
У меня в коде и не используется, очевидно же :)
Это просто пример был, для того чтобы понятно, о чем речь в общем. В реальном коде вместо этого везде что-то вроде someFunction(x+y) где someFunction исполняет какой-то нужный сайд-эффект (setState реактовский, например).
Но это достаточно вырожденный пример, когда от монады, действительно, мало что осталось и такое не так уж распространено. А вот неисполнение монадических законов — как в промис-монаде жс — штука обыденная. Try в скале, насколько я помню, еще из распространенных примеров.
В Linq, кстати, тоже return не используется (если даже написать аналог return'а, то шарп не сможет вывести полиморфный аргумент). И вообще монадическая нотация там рассахаривается совсем не как в хаскеле, т.к. SelectMany — не бинд.
Смысл в том, что есть математические абстракции, и есть реальные объекты реального мира. И одно не в точности соответствует другому — абстракции описывают реальные объекты лишь с точностью до. Всегда есть какая-то погрешность. Даже какой-нибудь канонический Maybe в хаскеле — это не идеальная сферическая монада в вакууме (просто потому, что ваш пека — это не идеальная сферическая в вакууме машина Тьюринга, а просто обычный конечный автомат) и можно построить специфические кейзы, когда оно не будет себя вести как должно. Но мы разумно пренебрегаем подобными кейзами.
Ключевой момент тут "разумно", коненчо — т.е. надо понимать какие есть погрешности и где они важны.
Например, альтернативное рассахаривание шарпа работает т.к. fmap f x = x >>= return. f (т.к. from x' in x select f(x') как раз непосредственно в Select aka fmap и преходит), и вы, будучи неосторожным, вполне можете встретиться с неожиданным поведением монады, которая этому закону не удовлетворяет
Because of these difficulties, Haskell developers tend to think in some subset of Haskell where types do not have bottom values. This means that it only includes functions that terminate, and typically only finite values. The corresponding category has the expected initial and terminal objects, sums and products, and instances of Functor and Monad really are endofunctors and monads.
В Linq, кстати, тоже return не используется (если даже написать аналог return'а, то шарп не сможет вывести полиморфный аргумент).
static IEnumerable<T> Return<T>(T value) {
yield return value;
}Который из аргументов не получится тут вывести?
SelectMany — не бинд
а что это такое тогда?
а что это такое тогда?
Просто функция, никакой теоретической конструкции, которой бы она соответствовала, мне неизвестно (хотя может она и есть). Есть много функций, которые "не бинд". Не понятно, что вас удивило тут. У SelectMany, собственно, три аргумента. А у бинда — два.
Который из аргументов не получится тут вывести?
Причем тут определение Return, я про применение. Если вы напишите Return(1) то за счет какой магии шарп узнает, что там должен быть IEnumerable? Хотя, сейчас вот я вспомнил, что недавно в определенных контекстах шарп научился по возвращаемому типу выводить аргументы, может, сейчас и выведет (хотя не уверен). Раньше точно не мог.
Просто функция, никакой теоретической конструкции, которой бы она соответствовала, мне неизвестно (хотя может она и есть). Есть много функций, которые "не бинд". Не понятно, что вас удивило тут. У SelectMany, собственно, три аргумента. А у бинда — два.
Потому что это liftM2, из которого бинд можно вывести.
У SelectMany, собственно, три аргумента. А у бинда — два.
А это тогда что? SelectMany<TSource,TResult>(IEnumerable<TSource>, Func<TSource,IEnumerable<TResult>>)
Если вы напишите Return(1) то за счет какой магии шарп узнает, что там должен быть IEnumerable?
Понял. Но направление вывода типов в C# никак не мешает IEnumerable<> быть монадой.
А это тогда что? SelectMany<TSource,TResult>(IEnumerable, Func<TSource,IEnumerable>)Это перегрузка НЕ используется при десугаринге Linq, в том-то и дело. В Linq используется вот эта перегрузка:
this IEnumerable<TSource> source, Func<TSource, IEnumerable<TCollection>> collectionSelector, Func<TSource, TCollection, TResult> resultSelector )``` она позволяет десугарить Linq не во вложенные замыкания, а просто в последовательность вызовов something.SelectMany(...).SelectMany(...).SelectMany(). и если вы хотите что-то сделать используемым в Linq, то вам надо будет именно эту перегрузку писать (ну только IEnumerable на свой генерик замените), иначе ошибка типов. А обычный бинд, напротив, не требуется. Понятно, конечно, что одно можно написать через другое. >Понял. Но направление вывода типов в C# никак не мешает IEnumerable<> быть монадой. А кто говорил, что ей что-то мешает быть монадой?
Ну, начинали-то вы ветку не с десугаринга Linq, а с неисполнения монадических законов...
Ну, начинали-то вы ветку не с десугаринга Linq, а с неисполнения монадических законов...
Так а где я говорил, что конкретно для IEnumerable что-то не исполняется (ну, если пренебречь тем, что "настоящих" монад в программировании не бывает в принципе)?
Linq был приведен как пример того, что чтобы что-то было "linq-монадой" этому чему-то не нужен ни стандартный bind, ни return.
ФП без ТК это конечно хорошо, но — плохо.
Спойлер: return в хаскеле НЕ ключевое слово.
ФП без ТК это конечно хорошо, но — плохо.
ТК без ФП — хорошо, и ФП без ТК — тоже хорошо. А вот вместе — всегда плохо, т.к. эти вещи несовместимы. Нельзя о функторах/монадах/етц. из фп рассуждать так, как будто это обычные функторы/монадц/етц. Так как это не они.
как они связаны с join и причем тут какие-то «законы»
join вам в ФП не нужен, а законы не при чем вообще. На практике хватит одного бинда. Даже кривого.
Вам просто нужны неизменяемые коллекции и репл. Когда вы пишете класс в половину экрана ради элементарных действий, это никакое не ФП, а имитация.
Да я на самом деле только рад. Я же говорю, что это подход, направленный на большее переиспользование и меньшую связность (coupling) компонентов. То, что нам так любят продавать на ООП конференциях.
Кто развел всё это шаманство и мистицизм вокруг ФП не берусь судить. Берусь только немного развеять и показать, что всё очень приземленно, практично и полезно для живых разработчиков, а не только для высоколобых математиков.
И я — на Паскале лет тридцать назад. ;)
единственное разумное использование такого аргумента — вернуть дефолтное значение когда массив пустой
Найти первое недефолтное значение массива.
Нет, так не получится — у вас не определена операция равенства для T.
Зависит от языка? В той же scala у всех есть equals(). Может имеется ввиду не равный, а идентичный (та же ссылка)?
Ну, зависит от языка. Как я уже говорил, в большинстве популярных вы этого сделать не сможете:

Чтобы это сделать в нормальном языке вам нужно будет явно затребовать возможность сравнивать:
bool Eq<T>(T a, T b) where T : IEquatable<T> => a.Equals(b);Хотя с языках с недостаточно сильной типизацией можно нахачить, но я как раз и говорю о том, что лучше их не использовать. В том же сишарпе можно обойти это через object.Equals/object.ReferenceEquals/..., но это скорее всего только выйдет боком (потом бегать выяснять, почему класс поменяли на структуру и всё сломалось).
В конце концов это лишняя писанина, поэтому если автор это написал, то значит как-то скорее всего это использует.
Может использует, может нет. Гадание по сигнатуре — такое себе занятие. А уж предполагать, что все люди всегда предельно рациональны — вообще глупо.
Вряд ли вы так делаете для всех функций которые явно не подозреваете во вредительских намерениях?
Здесь речь о том что для чистых функций предположения о их работе по сигнатуре можно делать легче и с большей степенью вероятности они будут подтверждаться.
Ну а если всё же ракета на Марс запустится, то поможет «многочасовая отладка». Но вероятность что к ней придётся прибегнуть будет меньше.
Если есть сомнения в чистоплотности автора кода, то такой код я не буду использовать независимо от сигнатуры. А если сомнений нет, то достаточно и её названия.
Если бы каждый раз когда функция с именем вроде GetItem обновляет записи в БД или глобальном стейте мне давали бы рубль я бы уже давно стал миллионером.
Где же ваша дедукция, которой вы так кичитесь? Префикс Get означает, что Item будет возвращён из базы в любом случае. А если его там ещё нет, то очевидно он должен быть тут же создан.
Префикс Get означает, что Item будет возвращён из базы в любом случае. А если его там ещё нет, то очевидно он должен быть тут же создан.
Если по префиксу Get вам понятно что будет идти запись в базу, то я даже не знаю что вам на это сказать..
Что до дедукции, то она отлично работает в языках, где сигнатуры не врут. В сишарпе, как я показал, увы, это не так.
Это называется "абстракция". Клиента не волнует, что система делает там у себя под капотом, её задача выдать элемент по идентификатору. Если допускается его несуществование, то метод называется findItem, если не допускается — getItem. Яркий пример такой абстракции: https://ru.wikipedia.org/wiki/Touch
Если допускается несуществование записи — метод обычно должен называться GetOrCreate или как-то схоже по смыслу. А еще лучше, когда по типам видно, что возвращается Option<T>, и понятно что происходит, если объект не нашелся.
Это уже протечка абстракции. Клиента не должно волновать создаётся оно там, клонируется или ещё что — для него ресурс существует всегда. То, что он создаётся лениво — не его ума дело. Собственно, мне ли объяснять это любителю бесконечных списков?
Во-вторых, getItem — должен вернуть либо Item, либо пустой элемент/null/ошибку, если item'а не существует. Создавать что-либо он не должен, для этого должны быть методы getItemOrCreate или getItemOrDefault.
getItem должен делать ровно то, что указано в названии. Не больше и не меньше. Не null возвращать ибо тогда он был бы getItemOrNull. Не ошибку кидать, иначе он был бы getItemOrThrows. А вот создавать ли новый, дефолтный или вообще прокси — скрыто за абстракцией.
Боюсь, с таким чинильщиком абстракций, никакого ломальщика абстракций уже не нужно.
Если у него машины нет, но он подписал со мной контракт, что по моему запросу предоставит мне машину, то он должен её предоставить. Где он её достанет — его проблемы, а не мои. Может угнать, может купить за свой счёт, может собрать в гараже из мусора.
Извините, но вы с таким подходом не сможете реализовать ни одну реальную работающую программу, потому что идеальных программ не бывает и не учитывать ситуацию «что-то пошло не так» — делает все вашу архитектуру изначально нежизнеспособной.
Если контракт нарушен — паника и экстренное закрытие матрицы.
С каким "таким" подходом? Что за слова надо отвечать? Так я и не называют метод getItem, если не могу гарантировать его возврат.
Если назовёте её deliveryMessage, то да, должна гарантировать.
А вам не кажется, что если тип возвращаемого значения в сигнатуре функции может принимать значение null, то возможность его возврата это уже часть контракта?
И это при том, что у вас полный холодильник жратвы, есть и уха, и икра с маслом, есть всё кроме борща.
Но жена ваша проста — сказал «ещё борща» — запускаю протокол «борщ», еду по ночной Москве искать свёклу.
А вот если бы вместо добавки вы получили ответ «борща нет», а затем спросили бы «а что есть» и уже на основе этого принимали бы решение что делать (не есть, есть что есть, ехать за продуктами) — то не попали бы в идиотскую ситуацию, когда детей укладывать некому, потому что жена уехала на ночь глядя за проклятой свёклой…
Такой пример, без заумных слов DDOS и RPS, покажется вам более полезным.
Правильно реализованная жена, поддерживающая контракт "ещё борща" приготовит этого самого борща с запасом именно на случай, если я попрошу добавки. Причём с таким запасом, чтобы как бы быстро и много я ни ел, она всегда могла сгонять в Ашан за свеклой.
Давайте закончим с этой спец олимпиадой по наркоманским метафорам и попробуем понять, что вам говорит собеседник?
А если борща вдруг не хватило, то это жена неправильная, ага
В данном случае
Правильно реализованная женавообще не должа заниматься добычей свеклы, это должен делать «правильно реализованный» муж.
P. S: Получается анти-паттерн «Отказ от ответственности».
В современных реалиях правильно реализованный муж майнит число на сервере банка, а правильно реализованная жена наоборот уменьшает это число до неотрицательного значения и предоставляет сервис "борщ on demand".
1) Ресурсы бесконечны
2) Несвежий борщ вкусен
Когда речь идёт о производительности, выраженной в RPS / Core, то все эти варианты с «запасом» уже не могут быть использованы.
А в программировании я вообще ожидаю что Get это идемпотентная операция, которая не изменяет состояние системы.
Я же код пишу не для того чтобы его писать. Я, в первую очередь, пишу его так чтобы большинство моих коллег могли его читать, понимать, модифицировать и использовать.
Если вы имеете ввиду, что в некоторых случаях нужно иметь возможность получить существующий «борщ» или сварить новый — используйте FindOrCreate, например. И любой другой разработчик поймёт что именно произойдёт при вызове метода, не глядя на сигнатуру.
в программировании я вообще ожидаю что Get это идемпотентная операция, которая не изменяет состояние системы
Она не изменяет видимого состояния системы. Внутреннее состояние меняется всегда (банально пишутся логи).
То есть вы ожидаете что Get какой-нибудь сущности типа "дай мне текущее время" упадет с HttpException потому что он полез на сервер часы синхронизировать?
Как раз таки не упадёт и выдаст мне его в любом случае.
Ну вообще может упасть, потому что полез в, например, базу время последнего доступа к ресурсу модифицировать. Или место на диске под логи кончилось, а у нас бизнес-правило: ни одного ответа без логов, лучше не отдать ответ, записав его в логи как отданный (почти отданный), чем отдать и не записать.
Но чаще всё же превалирует конвенция getItem() без видимых сайд-эффектов и getOrCreateItem(тут обычно полные данные), поэтому новичкам в вашем проекте нужно больше времени для адаптации (дороже).
Если уж говорить про мою конвенцию, то я пишу просто Item безо всяких get. Выглядит это так:
@ $mol_mem_key
User( id : string ) {
return new this.$.$my_user( id )
}Есть такой гайдлайн, называть сущность — существительными, а методы — глаголами. Очень помогает не запутаться, особенно во всяких флюент интерфейсах.
Это уже протечка абстракции. Клиента не должно волновать создаётся оно там, клонируется или ещё что — для него ресурс существует всегда
Именно в ФП клиента не волнует что внутри функции если тип возвращаемого значения T. А вот в императивных языках нет такого четкого контракта, приходится везде проверять на null либо потом ловить NRE в runtime, вместо compile time проверки.
В нормальных императивных языках есть чёткие контракты и non-nullable типы.
А можно пример этих нормальных языков? А то на вскидку только Swift на ум приходит.
TypeScript, например. Ну и в принципе легко добавляется в любой язык с дженериками.
TypeScript, например.Вот написали Вы либу с надеждой на TypeScript, а я стал ее использовать в проекте без strictNullChecks или вообще с чистым JavaScript… а потом буду разбираться со стректрейсом, который полностью в node_modules из-за того, что какой-то умник не проверил на null понадеявшийся на «строгий» (нет!) компилятор…
И таких библиотек на npm в последнее время стало очень много…
Ну и в принципе легко добавляется в любой язык с дженериками.А можно пример такого добавления?
я стал ее использовать в проекте без strictNullChecks или вообще с чистым JavaScript
Ну и ССЗБ.
С серьезным кодом я не работал, так что могу быть неправ.
Когда в проекте используются сотни библиотек, и у каждой новая версия выходит раз в пару месяцев, а раз в пару лет АПИ полностью меняется, уследить за всем невозможно.
Поэтому поддержка со стороны компилятор и системы типов жизненно необходима.
Начитавшись всяких «best practices» многие с умным видом пишут избыточный код, попросту забыв про KISS. Универсального подхода попросту не может быть, все зависит от ситуации.
Я до сих пор не могу понять от кого мы пытаемся защитить код: от программиста, которому мешает нога, или от подлой машины возвращающей неожиданные результаты? От непонимания этого вопроса и возникают такие выводы.
Никакого непонимания нет, машина делает то, что вы ей приказали, а не то, что вы хотели, чтобы она сделала.
Соответственно, нужно стремиться к тому, чтобы и вы, и машина написанный текст воспринимали одинаково. Этому способствует, когда и для вас, и для машины метод GetItem возвращает результат. И не способствеует, кона для вас он возвращает результат, а для машины должен еще емэйл на почту отослать.
Видимо неправильно сформулировал вопрос:
Для кого введены жесткие ограничения? Машина выполняет только заложеные человеком комманды. Следовательно и типы и приватные поля существуют для человека. Опишу на примере JS: простых приватных полей там нет, и многие изгибаются реализуя их на замыканиях пытаясь спрятать — вопрос: от кого? От себя? Ведь давным-давно условились что поля с префиксом "_" являются приватными, и это всем известно. Но нет, кто как может пишет мудреный код, теряя читабельность и свое время. Зачем нужна эта защита от дурака?
P. S: Возможно я задаю себе(и Вам) слишком глубокие вопросы уходящие корнями в психологию и философию, на которые невозможно ответить сразу.
Это делают скорее потому, что это интересная задача. У нормального разработчика это всё обычно проходит как только появляется потребность дебажить и тут выясняется, что исследовать спрятанные от себя же поля — геморрой.
Не могу понять как это связано с системой типов. Можно вернуть ожидаемый результат и отослать емэйл. От кривой реализации панацеи нет.
Ну вот вам система типов не позволяет вместо строк передавать числа и наоборот? Точно так же система типов может запретить отсылать емейлы, когда вы этого не хотите. Товарищ 0xd34df00d выше расписал как раз этот сценарий.
Компьютер штука глупая. Глупость туда — глупость оттуда.Говорила моя коллега с работы)
Увы, но эта самая протечка обусловлена не архитектурой приложения, а характеристиками СУБД и нефункциональными требованиями к ПО. Клиенту, может быть, и правда не важно появилась запись в БД или нет (при сохранении прочих инвариантов) — но вот просадку производительности так просто не заабстрагировать.
Подписал контракт — изволь исполнять. Хочешь сэкономить — подписывай иной контракт. Или вы предлагаете делать не то, на что подписались?
Я предлагаю включать в контракт действительно важную информацию, а не отмахиваться от неё на основании "ну, то же абстракция!"
В частности, функция GetItem не должна ничего писать в БД. Это и есть её контракт. Который, увы, иногда нарушается, потому что никто не следит.
Такой контракт ничего не говорит о возможности или невозможности писать в СУБД. Ок, вот вам простой пример. Вам нужно получить сессию, вы пишете что-нибудь типа SessionManager.get(). Если сессия автоматически создаётся заранее, то вам будет просто возвращён её объект. Если же SessionManager решили сделать ленивым, то метод get будет создавать сессию под капотом в момент первого обращения. В какой момент будет запись в бд — спрятано за абстракцией SessionManager. Это не ваше дело в какой момент ему ходить в свою же базу.
Во-первых, я бы метод с описываемой вами функциональностью назвал start, а не get.
Во-вторых, в чём смысл хранить в базе пустые сессии?
start предполагает начало какого-то процесса. Тут же сессия уже может уже быть, может ещё не быть — в контракте это никак не ограничено. Present Simple — она просто есть, как безвременная абстракция.
Почему же пустые? У неё есть время старта, id узла и прочая нужная информация. А ещё есть админка, позволяющая смотреть список активных сессий и килять неугодных.
А что будет после "киляния"? Автоматически начнётся новая? Так всё-таки, в чём смысл пустой сессии?
Так это вариант существующей сессии же, я говорю про другой случай.
Вам нужно получить сессию, вы пишете что-нибудь типа SessionManager.get()
Я пишу SessionManager.getOrCreate() (как это сделано в Spark, например). И заранее знаю, что он именно что её гарантированно выдаст — или уже существующую, или новую, — именно потому что и в названии функции это чётко сказано, и сигнатура не подразумевает неудачного исхода (хотя и допускает выброс исключения, да, это всё-таки JVM).
Если сессия безусловно создаётся мидлварой ещё на подлёте к вашему обработчику, то имя getOrCreate врёт, так как при её вызове собственно create не происходит никогда.
for (;;) {
cup = new Coffee();
if (card.Balance < cup.Price) break;
resultList.Add(cup);
card.Charge(cup.Price);
}Получается, что чистая функция должна вернуть не просто список изменений, который нужно применить к Card, а алгоритм, изменяющий Card определённым образом и строящий resultList? Но тогда мы входим в рекурсию — наш алгоритм возвращает алгоритм, который нужно интерпретировать.
Ну если бы мы были в хаскелле, то можно было бы красиво использовать ленивый бесконечный список и через фолд выразить эту семантику.
Ну а так да, хороший пример когда ST помогает в строгом языке написать алгоритм, который не выглядит как мешанина из коллбеков:
var currentCharge = Charge.Empty(card);
for (;;) {
var (cup, charge) = Cafe.BuyCoffee();
var newCharge = charge.Combine(currentCharge);
if (card.Balance < newCharge.Amount) break;
resultList.Add(cup);
currentCharge = newCharge;
}Можно использовать рекурсию:
Buy(card, coffies, charge){
var cup = new Coffee();
return card.Balance < charge.Amount + cup.Price
? (coffies, charge)
: Buy(card, coffies.Push(cup), charge.Combine(new Charge(card, cup.Price));
}То есть, по сути, вместо того, чтобы передавать во все функции мутабельный объект card, нужно передавать начальное состояние originalCard и отдельно все объекты-изменёния его полей (например, за изменение Balance пусть отвечает Charge, за изменение owner пусть отвечает некий Renamer и т.п.)
Вместо простой сигнатуры BuyCoffee(Card) -> (List), мы делаем BuyCoffee(Card, Charge) -> (Charge, List), которая показывает, что была исходная карта и набор списаний, а получен список покупок и расширенный набор списаний (который можно применить к исходной карте).
Тут пока только одно действие с картой. А если типов действий десяток, так и таскать между всеми функциями исходное состояние и все списки применённых действий?
Самое главное. Мы это делаем для упрощения работы программиста. Не скажу за других, но императивный код
if (card.Balance >= cup.Price) card.Balance -= cup.Price;для меня понятнее, чем введение новый сущностей (Charge) и операций с ними (Charge.Combine). И такие сущности надо вводить на каждую мелочь, чтобы сохранить чистоту функций?
Я так понимаю, currentCharge не должен создаваться в этой функции, а должен передаваться снаружи и изменённый отдаваться обратно.
Да нет, совершенно нормально создать его в функции. Это же просто начальный элемент. Как единица для факториала, вам не надо передавать её снаружи.
Поэтому дальнейшие рассуждения немного некорректны.
Было у вас BuyCoffee(Card, IPaymentProvider) -> (List)
Стало BuyCoffee(Card) -> (List, Charge).
Если действий десяток, то у вас на выбор: сделать ADT энум "один из вариантов действия с картой", сделать какой-нибудь аггрегатор с кастомной логикой который что-то подобное сделает или что-то еще. Звучит сложно, наверное, но на самом деле таковым не является.
Самое главное. Мы это делаем для упрощения работы программиста. Не скажу за других, но императивный код
if (card.Balance >= cup.Price) card.Balance -= cup.Price;
для меня понятнее, чем введение новый сущностей (Charge) и операций с ними (Charge.Combine).
Ну если вам проще, то можно мутировать локальное состояние через ST, я ж говорил :) Главное не нарушить прозрачность. А нарушение прозрачности это плохая штука, я выше вроде показывал какие проблемы оно вызывает. Да и рассуждения в терминах трансформаций данных со временем помогают лучше представлять, что в коде происходит. Не надо думать "так, сейчас пятая итерация, какое состояние у карты там? А какое значение было когда метод был вызван? Забыл..."
И такие сущности надо вводить на каждую мелочь, чтобы сохранить чистоту функций?
А вот тут вы и подбираетесь к монадам. Да, формально вам нужно такие функции писать для каждого типа. И именно для того чтобы не заниматься лишней писаниной, монады и изобрели. Ну примерно как придумали виртуальные функции, чтобы не писать if employee.Type == "Manager" { ... }.
Да нет, совершенно нормально создать его в функции. Это же просто начальный элемент. Как единица для факториала, вам не надо передавать её снаружиТак откуда мы узнаем, сколько денег с карты уже списано?
Если я вызову 10 раз ф-цию BuyCoffeesForAllMoney(Card), то она 10 раз и купит одно и то же, я же ожидаю от второго и последующих вызовов, что денег на карте больше нет и ничего купить нельзя.
Так откуда мы узнаем, сколько денег с карты уже списано?
Ну так нисколько, мы же реально не списываем.
Если же мы хотим всё же "поменять" значение то нам подойдет монада State, тогда мы сможем запомнить что куда списали до того как до этого момента дошли. Но это опять в монады углубляться. Просто монады это как интерфейсы и паттерны в ООП, любой нетривиальный вопрос — и вы в них попадаете.
Если я вызову 10 раз ф-цию BuyCoffeesForAllMoney(Card), то она 10 раз и купит одно и то же, я же ожидаю от второго и последующих вызовов, что денег на карте больше нет и ничего купить нельзя.
Вот именно то что вызов одной и той же функции может дать разный результат и есть плохой сценарий, от которого стоит избавляться. Функция просто должна возвращать значение, и ничего более. Для осуществления действий есть другие подходы, о которых в другой статье.
То, что она 10 раз вернет одно и то же — это совершенно ожидаемое поведение, и так и должно быть.
Вот именно то что вызов одной и той же функции может дать разный результат и есть плохой сценарий, от которого стоит избавляться. Функция просто должна возвращать значение, и ничего болееВот потому у Вирта есть функции и процедуры.
Вызывая последовательно процедуры BuyCola и BuyCoffeesForAllMoney я ожидаю, что сначала будет куплена кола, а на остаток денег — кофе. Это просто и естественно. Без новых сущностей, таких как Charge.
Если же «всё есть функция», надо думать по-другому.
Если же «всё есть функция», надо думать по-другому.
Да. надо думать по-другому. Это несет только плюсы. Старые представления стоит время от времени пересматривать. Чистые функции проще тестировать, проще композировать, и обычно проще писать.
Вирт и прочие коллеги, которые разрабатывали ЯП тех времён вероятно очень большую дыру в абстракции допустили. Ибо технически как преподают — никакой разницы между функциями и процедурами нет. Только первые возвращают значение. И в результате в головах у учеников нет понимания почему нужно использовать одно или другое. Что ещё хуже — передача параметров по ссылке, а не по значению. Для эффективности — это не плохо, но потом резко выясняется, что аргумент функции или процедуры мутабелен. Жесть. С/с++ этим же страдают в полный рост. Поглядите на какие-нибудь Win32API или стандартную библиотеку языка. Пойди без поллитра разберись что происходит. Поэтому более абстрактные языки новых поколений — это прекрасно. Твои ожидания от того, как будет выполняться код ПОЧТИ совпадают с реальностью...
Наверное, потому что языки того поколения — по сути были надмножеством ассемблера? Который как раз и имеет обе эти (на самом желе) одну абстракцию — подпрограмму (заметьте, как я изящно избежал использования слова функция)
А сейчас теория продвинулась. Вычислительные мощности выросли на порядки. И появились предпосылки для написания… Более математических программ
В контексте этой ветки — затем, что процедура возвращает на самом деле не Unit, а IO Unit.
А что если усложнить пример. Допустим, у нас есть две платёжных карты: основная и резервная. Если с основной транзакция не прошла, списываем с резервной. Причём, критерий обслуживания мы не знаем: например, с одной суммой транзакция может не пройти, а с другой может пройти (все чашки имеют разную цену).
Как вот такой алгоритм перевести в «чистый»?
for (;;) {
cup = new Coffee();
if (card1.TryPay(cup.Price)) {
resultList.Add(cup);
} else if (card2.TryPay(cup.Price)) {
resultList.Add(cup);
} else {
break;
}
}Ну тут уже придется расчехлять монады (в сишарпе монадический do-синтаксис спрятан за async/await поэтому использую его):
for (;;) {
cup = new Coffee();
if (await card1.TryPay(cup.Price)) {
resultList.Add(cup);
} else if (await card2.TryPay(cup.Price)) {
resultList.Add(cup);
} else {
break;
}
}нужно понимать что await тут в более широком смысле чем запуск асинхронной операции.
Тогда вызов нашей функции будет чистым — мы просто создаем описатель вычисления (в сишарпе это тип Task), который ничего не делает пока мы его не запустим и не получим результат.
Достаточно любую процедурную лапшу обвешать async/await, и получим чистую функцию, которую легко сопровождать и в которой минимум ошибок, ведь это теперь ФП!
Ну, какой-то смысл в этом есть. Любую лапшу действительно можно так переписать, это скорее плюс. Другой вопрос что лучше постараться вынести переиспользуемые куски. Но если не получается, в худшем случае вы остаетесь там, где начинали. То есть даже в худшем случае вы ничего не теряете.
Зато явность авейтов часто помогает недопустить ошибку которую я сделал. Если бы в том коде было вот такое:
var something = await function();
await DoStuff(this.Field, something);я бы знал, что переставлять эти строчки может быть опасно.
я бы знал, что переставлять эти строчки может быть опасно.А может и не опасно. Нет никакой гарантии, что в этом коде function меняет this.Field.
В императивном коде тоже было известно, что перестановка операторов может привести к изменению поведения. А может и не привести. Тут в любом случае надо смотреть реализацию.
Так тут фишка как с unsafe в расте. Если я вижу явный забор "опасно" я пойду проверять.
А в сишарпе мне никакого терпения не хватит при каждом инлайне каждой функции идти проверять все возможные последствия.
Добавляя await, получаем предупреждение, что теперь возможно у кода есть побочные эффекты )))
Скорее авейт говорит, что у кода обязательно есть побочные последствия. В зависимости от монады это может быть разный эффект. В State это будет изменение стейта, в IO асинхронный запрос куда-то, в Writer запись в лог, и так далее.
Дальше остется оценить, устраивает ли меня что эффект поменяется или нет. Например, если запись в лог будет чуть позже то мне наверное пофиг, а вот если раньше стейт менялся в другой момент, то наверное так делать нельзя.
Сейчас я слабо представляю, как написать State через await-ы, но интуитивно мне кажется неправильным писать в State через await-ы, а читать его напрямую обращением к изменившемуся полю, а не через другую async-функцию. То есть, ваш пример конкретно с this.Field и await-ами мне кажется несколько надуманным.
Способ перенести управление во вне — это скорее генераторы. А async/await — не более чем частный их случай.
1. Весь генератор должен yield-ить из одной функции, когда await-ы могут вызываться и из вложенных.
2. Генератор привязан строго к одному типу значений, когда типизация await-ов намного богаче.
3. Внешний код не может передавать данные внутрь генератора по мере выдачи им значений, чтобы влиять на работу генератора.
Весь генератор должен yield-ить из одной функции, когда await-ы могут вызываться и из вложенных.
Как минимум несколько раз я видел возможность написать что-то вроде yield* anotherGenerator() (пример из JavaScript).
Внешний код не может передавать данные внутрь генератора по мере выдачи им значений, чтобы влиять на работу генератора.
А если может (см. как минимум всё тот же JavaScript) — это уже не генератор, а корутина получается?
это уже не генератор, а корутина получается?Ну так комментатор выше утверждал, что генератор — более общий случай. Значит, должен уметь всё, что и корутины.
Я сейчас чисто терминологически пытаюсь понять: граница проходит именно по возможности сказать не просто next(), а next(passed_value)?
Весь генератор должен yield-ить из одной функции, когда await-ы могут вызываться и из вложенных.
Нет, не могут. Вы принимаете за возможность await-тов возможности Task-ов.
- yield и await — одно и то же. async function и generator function — тоже. Вся разниа в том, то async/await передаёт между функциями промисы, а генераторы могут передавать что угодно.
- Не привязан он ни к чему. Вы так же можете возвращать типизированный промис, а внешняя функция будет вас вызывать, когда он отрезолвится.
- Может.
3. МожетКак это выглядит синтаксически?
Это именно что использование встроенной в язык конструкции. Эта возможность есть в С++, Javascript и Python, но отсутствует в C# и в Kotlin
Если любую функцию next() называть генератором, то зачем вообще вводить новый термин?
Генератор — это сопрограмма (обычно безстековая), которая императивно пушит "наружу" последовательность значений при помощи yield-подобной конструкции.
Любую функцию next назвать генератором нельзя.
Внутри генератора используются этим самые yield, снаружи это просто объект с методом "держи значение, которое вернёт yield и сделай ещё немного работы". К коллекциям это отношения не имеет.
Коллекции — это про итераторы. Итераторы можно реализовать через генераторы, а можно и через обычные функции.
А внутри, допустим, «yield 5;».
Или там не «yield 5;», а что-то типа «var localRes = yield 5;»?
Как параметр res попадает внутрь генератора?
Именно так, let x = yield 5
Что как-то нелогично. Было бы удобно, например, написать генератор случайных чисел и синтаксисом next(N) получать очередное случайное число в интервале (0,N).
А что мешает?
function rnd() {
let next = NaN;
for(;;) {
let N = yield next;
// генерируем случайное число в интервале (0, N)
next = ...;
}
}Тут разве что больше проблема с первым элементом возникает, его придётся пропустить.
function myRandom(maxValue) {
let dummy = rnd(maxValue);
return rnd(0);
}Зачем 2 раза-то?
let dummy = rnd();
dummy.next();
function myRandom(maxValue) {
return dummy.next(maxValue).value;
}А создавать новый ГСЧ для получения каждого следующего числа ни в одном языке не рекомендуется.
Но как это работает?
Когда клиет вызывает
dummy.next(maxValue)фукция-генератор работает до следующего yield, т.е. до строки
let N = yield next;выражение в yield возвращает клиенту как результат next(maxValue), а параметр maxValue присваивает переменной N.
При этом, «генерируем случайное число в интервале (0, N)» находится ниже по коду.
И при первом вызове
dummy.next();функция выполняется до
let N = yield next;откуда будет взято значение N?
На инструкции yield выполнение сопрограммы останавливается. Пока не будет сделан вызов next — yield не вернет управления.
А next, в свою очередь, не вернет управления пока не выполнение сопрограммы не дойдет до yield.
return dummy.next(maxValue)возвращает значение не для переданного здесь maxValue, а для предыдущего?
Получается, что параметры next() сдвинуты ровно на 1 yield. Например, фукция
function * rnd() {
console.log("start");
let x1 = yield 0;
console.log("x1="+x1);
let x2 = yield x1*2;
console.log("x2="+x2);
let x3 = yield x2*3;
console.log("x3="+x3);
}z=rnd();
z.next(5); // параметр 5 не используется
console.log("start");
>> "start"
let x1 = yield 0;
>> z.next(5).value = 0
// хотя x1=yield 0; выполнен,
// значение x1 пока не задано
// вот это меня и смущало!
z.next(6); // параметр 6 передаётся в x1
console.log("x1="+x1);
>> "x1=6"
let x2 = yield x1*2;
>> z.next(6).value = 12
z.next(7); // параметр 7 передаётся в x2
console.log("x2="+x2);
>> "x2=12"
let x3 = yield x2*3;
>> z.next(7).value = 21
...
</souce>Пока не будет сделан вызов next — yield не вернет управления.
Неочевидно было, что вызов next(5), который вернул 6 из let x = yield 6;
это самое значение 5 не пишет в переменную x, а только параметр следующего next будет записан в x.
Как это может быть неочевидно? Сопрограмма "висит" на yield 6, и её разбудит только следующий вызов next. Он и определит значение x. Это единственное логичное поведение...
Хотя, этот дизайн можно понять: для клиента удобнее, чтобы параметр next повлиял на значение ф-ции next.
А так, получается, yield выполнен наполовину
Но ведь точка, где переключается контекст исполнения, должна быть именно что "выполнена наполовину" и никак иначе...
Хотя, конечно нет никакого instruction pointer-а: корутина компилируется в state-машину, где стейты соотносятся с инструкциями весьма условно, поэто наверное нет большой разницы в реализации, поделён yield между стейтами или нет.
Если я правильно понимаю, загвоздка в том, что let x = yield y; семантически представляет собой не одну, а две инструкции: собственно yield и присваивание. И "после yield" как раз и значит "между yield и присваиванием".
Вычисление оператора и запись в переменную — разные инструкции.
let x = (yield 5) + (yield 6)Сложно придумать, каким должен быть сценарий обмена данными между генератором и клиентом, чтобы подобные конструкции выглядели уместно.
Ну, например, если yield отправляет некоторый запрос, а в next(...) мы засовываем ответ на него (аналога async/await).
можно было бы сделать сопоставление один-к-одному next и yield. Именно это и было ожидаемо.
Они 1 к 1 и сопоставляются, кроме первого .next(), который можно интерпретировать как .start()
Вот так и попадает. next помещает переданное значение в стек и вызывает генератор, который в зависимости от счётчика у себя внутри делает goto на следующую после yield инструкцию.
Они идут вместе, и один их механизмов всегда можно выразить через другой, а потому некорректно говорить кто чьим частным случаем является.
В C++ Coroutines TS, к примеру, именно co_await является основным механизмом.
Сейчас я слабо представляю, как написать State через await-ы, но интуитивно мне кажется неправильным писать в State через await-ы, а читать его напрямую обращением к изменившемуся полю, а не через другую async-функцию. То есть, ваш пример конкретно с this.Field и await-ами мне кажется несколько надуманным.
Попробовал реализовать стейт через аваейты. К сожалению, из-за того как GetAwaiter оказался спроектирован, он прибит гвоздями конкретно к асинхронности.
Слава Богу, у LINQ такой проблемы нет, это полноценный do-синтаксис, так что на нем стейт монаду спокойно реализовать можно:
State<int, Unit> s =
from state in State.Get<int>()
let newState = state + 547
from _ in State.Set(newState)
select Unit.Instance;
Console.WriteLine(s.Run(5));Полный код можно найти по ссылке: https://wandbox.org/permlink/Thcf0CPQparKVQiG
Да, первоначально выглядит немного чужеродно, "как же так, ведь from .. in это для итераторов!", но на самом деле это не правда. from x in y это полный аналог хаскеллевского x <- y.
Правда, в отличие от полноценных монад это ад-хок решение, которое работает для известных во время компиляции типов. Написать функцию, которая работает таким образом с любой монадой не выйдет. Если только на динамиках каких-нибудь.
Допустим, я хочу написать «чистую» функцию с аргументом int a, которая увеличит state на 1, если a > 0, на 2, если a = 0, и на 3, если a < 0.
Ну вот так например:
State<int, Unit> Foo(State<int, Unit> state) =>
from a in State.Get<int>()
let valueToSet = a > 0 ? 1 : a == 0 ? 2 : 3
from _ in State.Set(valueToSet)
select Unit.Instance;Запускаем:
var initialState = State<int, Unit>.Return(Unit.Instance);
Console.WriteLine(Foo(initialState).Run(5));
Console.WriteLine(Foo(initialState).Run(0));
Console.WriteLine(Foo(initialState).Run(-5));Получаем
(ConsoleApp28.Unit, 1)
(ConsoleApp28.Unit, 2)
(ConsoleApp28.Unit, 3)Неправильно распарсил. Тогда так.
State<int, Unit> Foo(int a) =>
State.Set(a > 0 ? 1 : a == 0 ? 2 : 3);Можно было бы передавать старый стейт, но он все равно затирается, поэтому не нужен.
Нужна сигнатура
static State<int, Unit> Foo(State<int, Unit> state, int a) =>Простите, что-то я туплю. Вот так конечно же:
static State<int, Unit> Foo(int a, State<int, Unit> state) =>
from stateValue in State.Get<int>()
let increment = a > 0 ? 1 : a == 0 ? 2 : 3
from _ in State.Set(stateValue + increment)
select Unit.Instance;var initialState = State<int, Unit>.Return(Unit.Instance);
Console.WriteLine(Foo(5, initialState).Run(10));
Console.WriteLine(Foo(0, initialState).Run(20));
Console.WriteLine(Foo(-5, initialState).Run(30));получаем:
(ConsoleApp28.Unit, 11)
(ConsoleApp28.Unit, 22)
(ConsoleApp28.Unit, 33)static State<int, Unit> Foo(int a, State<int, Unit> state) =>
from stateValue in State.Get<int>()
let increment = a > 0 ? 1 : a == 0 ? 2 : 3
from _ in State.Set(stateValue + increment)
select Unit.Instance;
static void Main(string[] args)
{
var initial = State<int, Unit>.Return(Unit.Instance);
var next = Foo(0, initial);
var next2 = Foo(-1, next);
Console.WriteLine(next2.Run(100));
}
Потому что я снова тупанул и стейт не читаю, он всегда новый создается (если обратите внимание, переменная state не использовалась). Вот так должно быть:
static State<int, Unit> Foo(int a, State<int, Unit> state) =>
from __ in state
from stateValue in State.Get<int>()
let increment = a > 0 ? 1 : a == 0 ? 2 : 3
from _ in State.Set(stateValue + increment)
select Unit.Instance;Я еще начинающий ФПшник, тем более в сишарпе где язык сопротивляется :)
P.S. Когда уже стабилизируют деприкейт _ как имени переменной… Мешает очень.
А вот так можно два стейта разных читать и формировать новый:
static State<string, Unit> ConcatStates(State<string, Unit> a, State<string, Unit> b) =>
from __ in a
from aValue in State.Get<string>()
from _ in b
from bValue in State.Get<string>()
from ___ in State.Set<string>(aValue + bValue)
select Unit.Instance;
static void Main(string[] args)
{
var a = State.Set("Hello ");
var b = State.Set("World!");
Console.WriteLine(ConcatStates(a, b).Run(""));
}В общем, мощная штука)) И как видите, работает абсолютно так же, как итераторы или async/await.
Правда, сперва непривычно и дико, ведь LINQ по традиции используется только с итераторами. Потом привыкаешь.
static bool IsZero(State<int, Unit> state)Если бы так было можно, задача покупки кофе «на все деньги» могла быть решена через такой state (покупаем, пока не 0 на карточке).
Да, так нельзя, потому что это нарушает правило, что значение не может покинуть пределы монады. С такой функцией можно было бы нарушить ссылочную прозрачность. Функция должа выглядеть
static State<int, bool> IsZero(State<int, Unit> state)К стате, в хаскелле такая нечистая функция есть, правда, не для стейта, а для IO. Называется она unsafePerformIO, и как следует из названия, лучше ей не пользоваться. Против неё есть целая прагма {-# LANGUAGE Safe #-} которая запрещает её использование.
Значения не должны покидать контекста монады, в котором созданы. Это так же плохо, как выходить из асинхронного контекста функции через task.Result (который тоже является монадой, и именно поэтому так делать не надо). Чревато дедлоками и всеми остальными плохими вещами.
Поэтому покидать контексты монад — плохо. Для каждой монады последствия такого выхода свои, но всегда — плохие.
Если кто-то будет это читать, вот тут можно посмотреть итоговый вариант кода после всех исправлений:
https://gist.github.com/Pzixel/05d6fc18f389149e64995b148147345e
Что вы тут развели? Всё проще же, самый первый код был правильным, только с лишним параметром:
State<int, Unit> Foo() =>
from a in State.Get<int>()
let valueToSet = a > 0 ? 1 : a == 0 ? 2 : 3
from _ in State.Set(valueToSet)
select Unit.Instance;//сс qw1
Вы неправильно распарсили, как и я в первый раз) Вам нужен аргумент a чтобы понять насколько инкрементировать текущий стейт. А потом вам нужен сам стейт чтобы узнать его текущее значение.
Так что там всё правильно написано.
Ну тогда так:
State<int, Unit> Foo(int a) =>
from x in State.Get<int>()
let valueToAdd = a > 0 ? 1 : a == 0 ? 2 : 3
from _ in State.Set(x + valueToAdd)
select Unit.Instance;В любом случае, параметр state принимать не надо ни при каких условиях. Монада как раз для того и сделана, чтобы не нужно было принимать этот параметр.
Да, вы правы. Тогда использование становится тривиальным:
var next = Foo(0);
var next2 = Foo(-1);
Console.WriteLine(next.Bind(_ => next2).Run(100));Правда, в таком случае непонятно как склеивать 2 стейта, там такого эмбиента не получится ведь.
А для двух стейтов надо использовать либо трансформер монад, либо общий стейт и линзы.
Но в C# ни то, ни другое нормально работать не будет из-за направления вывода типов.
Console.WriteLine(
next.Bind(_ => next2.Bind(__ => next3)).Run(100));А если 100?
Ну для небольшого количества стейтов можно переписать в linq опять же :)
var final = from x in next
from y in next2
select Unit.Instance;
Console.WriteLine(final.Run(100));Ну а для 100 нужно будет их собирать в список и делать траверс или sequence. Примитивный вариант
public static State<S, A> Sequence<S, A>(this IEnumerable<State<S, A>> states) =>
states.Aggregate((prev, next) => prev.Bind(_ => next));Используем:
var states = Enumerable.Range(-5, 10).Select(Foo);
Console.WriteLine(states.Sequence().Run(100)); // 121 static Func<int, int> Foo2(int a) =>
a > 0
? x => x + 1
: a == 0
? x => x + 2
: (Func<int, int>)(x => x + 3);А потом вручную создать композицию этих «стейтов», и вызвать полученную композицию с начальным значением. Но это же не будет State в терминах монад? А в чём разница?
var next = Foo2(0);
var next2 = Foo2(-1);
var next3 = Foo2(1);
Console.WriteLine(next3(next2(next(100))));Вы верно уловили суть, State<S, T> — это и есть обёрнутая Func<S, T> (точнее, Func<S, (T result, S state)>).
Смысл этой монады — во-первых, в том что это простейшая из монад, удобная для изучения (проще нее разве что Maybe/Either — но те вообще ничего интересного не делают). А во-вторых, монада IO<T> — это, в некотором роде, State<RealWorld, T> (если забыть про невыразимость RealWorld) и у нее во многом схожие свойства.
С тем же успехом я могу написать
Верно, в ФП любую монаду можно описать как чистую функцию, принимающая аргументами другие функции и возвращающие еще одни функции. В этом ведь и весь смысл, а то наши рассуждения про чистоту развалились бы. Правда, выглядит оно как стейт, и работать (и думать) о нем можно как о стейте. В чём и состоит ценность.
А еще вы поняли, что такое монада (ну, одна из них). Не так уж сложно как говорят, правда?)
Совершенно не интуитивно и не похоже на императивное состояние. К тому же, даёт как неоправданную нагрузку на GC, так и на CPU сначала при генерации функторов, затем с их вложенным вычислением.
Вы же знаете, что такие заявления без бенчмарков делать не надо.
А как показывают бенчмарки, тот же хаскель быстрее и Java, и C#. Ну да, помедленнее плюсов, но я и не предлагаю его использовать на тех же задачах. А вот на задачах обычных сервисов и хождений в БД одни плюсы. Разве нет?
P.S. Когда уже стабилизируют деприкейт _ как имени переменной… Мешает очень.
Делаешь на монаде экстеншн-метод .And() (аналог >>) и пишешь так:
from stateValue in state.And(State.Get())
Тоже сам сорт оф костыль, конечно, но в итоге лучше выглядит чем черточки или переменные с натужно выдуманными именами.
По-моему проблема в том что должно быть this.function(). А что в си шарпе this не явный?
Или где то есть глобальная ссылка на this?
В данном случае function был коллбеком которйы попадал в функцию как параметр. И не во всех случаях передавался коллбек, который что-то менял, поэтому и на тестах и на ревью это не всплыло. А только на регрессе всех сценариев.
Что до this, то это ключевое слово в сишарпе необязательно, и this.Field и просто Field равнозначны.
Тогда вызов нашей функции будет чистым — мы просто создаем описатель вычисления (в сишарпе это тип Task), который ничего не делает пока мы его не запустим и не получим результат.
Любая функция ничего не делает, пока мы её не запустим и не получим результат.
Ну вот я запустил LazyPrint, на экране ничего не появилось:
void Main()
{
LazyPrint();
Print();
}
Task LazyPrint() => new Task(() => Console.WriteLine("I'm lazy print"));
void Print() => Console.WriteLine("I'm strict print");Не будем повторяться: https://habr.com/ru/post/479238/#comment_20980982
мы просто создаем описатель вычисления (в сишарпе это тип Task), который ничего не делает пока мы его не запустим и не получим результат
Вот с такими заявлениями надо быть аккуратнее. Task в C#, напомню, ленивым не является (если говорить про тот, который создаётся через async)
Ну тут я немного слукавил, признаю. Таски являются холодными если создаются через new Task, и не являются таковыми если создаются через асинк/авейт и Task.Run.
Честно говоря, мне кажется что это ошибка в дизайне языка. В том же F# кстати это было исправлено, там асинки честно ждут пинка от рантайма.
В том же F# кстати это было исправлено, там асинки честно ждут пинка от рантайма.
Фшарповые Асинки появились на пару лет раньше тасков. Так что это скорее авторы сишарпа не смогли списать домашку и запороли дизайн Тасков
Да всё проще же. Шарповые таски сделаны в императивной парадигме, потому что их так проще воспринимать.
Вон в прошлой статье при попытке изобразить что-то на ленивых тасках Питона один комментатор не смог в рекурсию, а второй запутался при портировании кода 1 в 1. Хотя, казалось бы, что тут сложного...
Сам по себе IO ничего не делает, если мы напишем print "Hello world" в хаскелле ничего не произойдет.
То есть человек ошибся, а компилятор вместо того, чтобы сообщить об ошибке, молча это скушал? Я бы не восхищался таким поведением.
- полагаю, на это есть ворнинг. В расте ведь есть MustUse атрибут
- Можно не писать 10 сообщений в корне?
- Опять вы что-то там предполагаете. У вас астроголов в роду не было?
- Можно не писать. а можно и писать. У вас в сигнатуре статьи не написано, что нельзя писать 10 сообщений в корне.
- как и предполагалось, ворнинг на это есть: https://repl.it/@Pzixel/Haskell-playground
- очень жаль, что в правилах этого нет. И "не у меня", это правила площадки, и я к ним отношения не имею.
хаскель программа это алгоритм записанный на листочке, а рантайм — это робот, который этот алгоритм выполняет
Любая программа — это алгоритм, записанный на листочке, а процессор — это робот, который этот алгоритм выполняет.
Вопрос в том, в какой момент происходит выполнение того, что написано — в тот же, когда выполнение дошло до некоторой строчки или потом при интерпретации.
Точно так же работают итераторы в сишарпе, например. Вы строите вычисление, но оно не срабатывает пока вы не начнете его собственно исполнять.
var query = Enumerable.Range(1, 10).Select(_ => throw new Exception());
var result = query.ToArray();Смысл именно в том, что вы получите эксепшн не в первой строчке, а во второй. Потому что сама запись "throw new Exception" ничего не делает. Это инструкция для дальнейшей интерпетации (через ToArray(), например). Поэтому создание query это чистая функция. Если я напишу:
var query = Enumerable.Range(1, 10).Select(_ => throw new Exception());То никаких исключений, ожидаемо, не произойдет.
Вопрос в том, в какой момент происходит выполнение того, что написано — в тот же, когда выполнение дошло до некоторой строчки или потом при интерпретации.
В императивных языках это называется кодогенерация.
Смысл именно в том, что вы получите эксепшн не в первой строчке, а во второй.
То есть программа остановится не в месте возникновения ошибки, а где-то в случайном месте программы, где решили привести коллекцию к массиву? Счастливой отладки, да.
В императивных языках это называется кодогенерация.
Каким образом кодогенерация к этому относится?
То есть программа остановится не в месте возникновения ошибки, а где-то в случайном месте программы, где решили привести коллекцию к массиву? Счастливой отладки, да.
Так работают ленивые вычисления, вне зависимости от языка. И это единственный способ сделать взаимодействие с внешним миром вроде БД или консоли чистым.
На практике проблем с этим нет, по крайней мере я не знаю сишарп разработчиков которым было бы больно от того что итераторы ленивые. Обычно это наоборот удобно.
На практике проблем с этим нет, по крайней мере я не знаю сишарп разработчиковКогда начинали писать с Entity Framework, коллеги бывало недоумевали: почему мой запрос выдаёт непонятные исключения при выполнении ToList(). Внутри каких-то expressions использовались выражения, который EF не мог превратить в SQL, а stack trace был очень далеко от того места, где ошибочный expression был добавлен в дерево запроса.
То есть программа остановится не в месте возникновения ошибки, а где-то в случайном месте программы, где решили привести коллекцию к массиву? Счастливой отладки, да.Именно по этому в ФП языках не кидают исключений, а возвращают рантайм ошибку как результат вычислений, а для ошибок программиста есть паника, у которой будет адекватный стектрейс…
С другой стороны, псевдокод на C#, эквивалент которого вполне можно встретить в императивном коде:
class A
{
public void MethodA()
{
MethodB();
}
private void MethodB()
{
throw new Exception();
}
}
class B
{
public void MethodA()
{
MethodB(new A());
}
private void MethodB(A a)
{
try {
a.MethodA();
}
catch(Exception e) {
Logger.Error(e);
throw e;
}
}
}
Счастливой отладки
Тут хорошей идеей было бы использование InnerException. Вместо throw e:
throw new MethodBException(e);И тогда в catch ничего логировать не надо, т.к. исключение брошено дальше, и должно быть залогированно там, где перехватывается.
Второй хорошей идеей было бы в методах типа
Logger.Error(e);Но я скорее предположу, что Ваша претензия к типу Result, но и тут проблем меньше.
Во-первых, в Rust четко разделены паники и ошибки как результат вычисления. Паники — это ошибки программиста, их почти никогда не ловят (хотя такая возможность есть, это крайний случай) и у них четкий стектрейс и дебажить их никаких проблем. Ошибки как результат вычисления — это штатная ситуация (сеть не доступна, файл не открылся), ее не нужно дебажить, ее нужно обрабатывать, ну или пробрасывать дальше, программисту чаще всего до лампочки, какой сискол там использовался под капотом, если его программа не смогла открыть файл из-за того, что юзер выдернул флешку.
Во-вторых, что бы пробросить ошибку, тип ошибки должен совпадать, а если моя функция возвращает Result<(), MyError>, а вызываемая Result<(), OtherError>, то чтоб пробросить его мне придется как то преобразовать OtherError к MyError, я могу сделать это на месте с помощью .map_err() или обобщенно, с помощью From/Into типажей, но сделать я это обязан, иначе моя программа просто не скомпилируется.
И это все резко отличает Rust/Ocaml/Haskell от языков с эксепшенами, где я мало того, что не вижу из сигнатуры, что там могут быть ошибки, так еще мне в одну кучу сыпят то, что я забыл написать if(x != null)
Каких, например?
Провалились скорее потому, что никому эта строгость не сдалась.
Это всё можно было бы реализовать через дженерики.
Имхо компилятор знает все типы исключений которые выбрасывает функция и при желании мог бы предоставлять эту информацию IDE
Как сделать следующее?Месье знает толк в извращениях, или вот что с людьми делает изучение систем типов :-o
Если мне пришел None — мне глубоко фиолетовоРовно до тех пор, пока в этом месте None не должно было прийти и нужно выяснить, почему тут None.
Ошибки как результат вычисления — это штатная ситуация (сеть не доступна, файл не открылся), ее не нужно дебажить, ее нужно обрабатывать, ну или пробрасывать дальше, программисту чаще всего до лампочки, какой сискол там использовался под капотом, если его программа не смогла открыть файл из-за того, что юзер выдернул флешкуНо программа не должна падать от того, что юзер выдернул флешку?
Во-вторых, что бы пробросить ошибку, тип ошибки должен совпадать, а если моя функция возвращает Result<(), MyError>, а вызываемая Result<(), OtherError>, то чтоб пробросить его мне придется как то преобразовать OtherError к MyError, я могу сделать это на месте с помощью .map_err() или обобщенно, с помощью From/Into типажей, но сделать я это обязан, иначе моя программа просто не скомпилируетсяМожет быть, может быть. С checked exceptions это не взлетело, потому что просто лень предусматривать все возможные варианты конверсий ошибок. Если где-то из глубин вылезет FileNotFoundException или HostNameNotResolved, конечно «правильным» действием для «правильного» языка будет закрыть программу и отправить дамп к программисту разбираться.
В реальности гораздо гибче показать юзеру FileNotFound (C:\Users\...\config.xml) не отличая его от NullReferenceException и других ошибок, и сказать, что вот это конкретное действие не выполнилось, и часто юзеру будет очевидна причина.
Если None там не должно придти, то это надо выразить в типах.Так у нас декомпозиция задач, и программер, который читает из конфига настройку, может просто вернуть None, если настройки в конфиге нет, а программер, пишущий код уровнем выше, может не заморачиваясь вернуть None в ответ на None. Замечу, что мы рассматриваем в этой ветке не абстрактно-идеальный код, где на каждом уровне написано всё верно, а «компилятор не выдал ошибку, а значит и так сойдёт». Кидание конкретного исключения, которое без изменений придёт на самый верх, тут не самая плохая идея.
Ну так и тут, вы можете на самом верхнем уровне просто сконвертировать конкретное значение ошибки в строку и показать его пользователю.То есть, нафиг эта строгость и типизация, пусть будет generic exception с текстом в виде строки.
У эксепшена тем не менее будет стектрейс, позволяющий понять откуда он взялся. А у блуждающего по программе None — нет.
Давайте не вспоминать протухшие языки, а то они так и не помрут.
В том и суть, что "можете", а не "должны", а ещё лучше "оно как-то само".
Давайте не вспоминать протухшие языки, а то они так и не помрут.
Ну, нужно же на чем-то всякие CLR'ы и JRE писать.
Существует полно современных компилируемых языков. D, Rust, Nim.
Вы вот зря иронизируете. Или вы протухание определеяете по популярности?
По устарелости дизайна. По тому как современные достижения компьютерной науки вписываются в дизайн языка. По количеству WTF.
Извините, не понял Вас. По-Вашему, С++ — протухший? То-то на нем до сих пор Яндекса и Касперский пишут. А ещё выходят новые стандарты...
Хотя согласен… С++ пора закапывать
Непонятно, почему вы рассматриваете ленивых программистов, везде кидающих None, но не рассматриваете ленивых программистов, кидающих бессмысленные экзепшоны.Потому что ленивым программистам не надо кидать бессмысленные exceptions, вместо этого осмысленные exceptions будут кинуты из слоя ниже, ленивым программистам нужно лишь их не ловить.
github.com/hyperrealm/libconfig/blob/master/lib/libconfigcpp.c%2B%2B#L282
Справедливости ради, стектрейс ошибок тоже бывает полезным, и кор тима над добавлением этой функциональности работает.
Забавно. Приверженцы ИП так любят говорить любителям ФП "счастливой отладки", но как-то так получилось, что за 8 месяцев работы со скалой и хаскелем мне ни разу не пришлось запускать отладчик.
То есть программа остановится не в месте возникновения ошибки, а где-то в случайном месте программы, где решили привести коллекцию к массиву?Это не «случайное место» — это место, где из ленивой последовательности требуется результат. И в стектрейсе будет явно указано, что исключение выкинуто на первой строчке из анонимной функции, но произойдет это после выполнения второй и функция `ToArray` также будет в стектрейсе где-то ниже. Все логично и ожидаемо.
del
Отличный вариант! Правда он не всегда может сработать. Во-первых потому что иногда оно может по типам не сойтись (с этим я столкнулся когда работал с акка стримами), а во-вторых у вас могут другие соображения. Например, производительность.
Но, наверное мы не просто так ту строчку в функции написали, и логи в кибане все же хотели бы увидеть, поэтому сочтем такую точку зрения маловероятной)
Если функция исполнилась — хотели бы. Если функция не исполнилась — не хотели бы. В данном случае логируется сам факт исполнения функции.
Хотя люди обычно признают удобства ФП фич, ведь намного приятнее писать:
int Factorial(int n) { Log.Info($"Computing factorial of {n}"); return Enumerable.Range(1, n).Aggregate((x, y) => x * y); }
чем ужасные императивные программы вроде
int Factorial(int n) { int result = 1; for (int i = 2; i <= n; i++) { result *= i; } return result; }
Нет, не приятнее и выглядит ужасно.
Ну тут еще и синтаксис сишарпа не очень. Возьмем пример с ренжами из C# 8.0:
int Factorial(int n) => (1..n).Fold((x, y) => x * y);Неужели это читается менее понятно чем вариант с циклами?
Тут буквально написано "возьми числа от 1 до n и перемножь их".
int Factorial(int n)
{
return Enumerable.Range(1, n).Aggregate((x, y) => x * y);
}
int Factorial(int n)
{
int result = 1;
for (int i = 2; i <= n; i++)
{
result *= i;
}
return result;
}
int Factorial(int n) => (1..n).Fold((x, y) => x * y);
Вот запулить опрос что более понятно. По мне так первый вариант наиболее лаконичен, но я почти не пишу на шарпе.=)
В этом весь смысл. Когда вы видите var x = foos.Fold(...) вы можете дальше не смотреть, вы знаете, что в результате получите одно значение определенного типа.
А когда вы видите for (...) то вы не знаете ничего. Надо проверить начальное значение, условие выхода, что происходит с аккумулятором (там часто умножение, битовые сдвиги или еще что-нибудь такое происходит). Потом еще тело посмотреть, что цикл делает. Может он значение возвращает, а может что-то нехорошее делает.
Поэтому когда вы вызываете более конкретную функцию, а не более общую, вы сужаете множество возможных действий, и упрощаете чтение кода.
Я как раз к тому, что эти абстракции хороши, и ими надо пользоваться. Не даром же они есть в стандартной библиотеке практически всех современных языков.
Пример из заголовка статьи скорее противопоставлял то, что флюент синтаксис с модными функциональными именами методов не делает ваш код автоматически функциональным. И с другой стороны, использование низкоуровневых циклов без абстракций не делает ваш код грязным. Выбор функции был лишь с точки зрения большего контраста.
А когда вы видите for (...) то вы не знаете ничего. Надо проверить начальное значение, условие выхода, что происходит с аккумулятором (там часто умножение, битовые сдвиги или еще что-нибудь такое происходит). Потом еще тело посмотреть, что цикл делает. Может он значение возвращает, а может что-то нехорошее делает.Вот это всё я наоборот считаю плюсом. В смысле что оно всё сразу в одном месте. У меня всё это происходит на автомате для императивщины.
Могу ответить такой аналогией: как вы отнесетесь к человеку, который все циклы всегда пишет for(;;)? Вы вот пользуетесь for/while/do_while/..., а он всегда пишет только for(;;)? Как по мне, это не очень хорошо.
ну или например, как вы думаете, что понятнее:
int[] b = new int[a.Length];
for (int i = 0; i < a.Length; i++) {
int value = a[i];
b[i] = a[i] * a[i];
}
return b;или
return a.Map(x => x*x).ToArray();Если вам ближе вариант №1, то я просто рекомендую получить опыт написания во втором стиле. Это вопрос привычки
Перепешите на свёртках списков код чуть сложнее, чем "привет мир", без потери наглядности:
bool isEqual( int[] left , int[] right ) {
if( left.length != right.length ) return false;
foreach( int i ; 0 .. left.length ) {
if( left[i] != right[i] ) return false;
}
return true;
}А в чем тут должна возникнуть проблема?
bool isEqual( int[] left , int[] right ) {
if( left.length != right.length ) return false;
return left.Zip(right, (left, right) => new {left, right})
.Foldr(true, (acc, item) => acc && item.left == item.right);
}Наглядность как по мне только выросла.
Это не эквивалентный код. Нужно заменить Foldr на что-то вроде FoldrUntil.
В ленивом языке (например, в хаскелле) это будет эквивалентный код.
В неленивом придется извращаться как тут: https://docs.rs/itertools/0.6.0/itertools/trait.Itertools.html#method.fold_while
С другой стороны, мне пришло тут в голову, что вот так можно написать с сохранением раннего выхода и читаемости
bool isEqual( int[] left , int[] right ) =>
left.length == right.length &&
left.Zip(right, (left, right) => new {left, right})
.All(item => item.left == item.right);Ну или с таплами
bool isEqual( int[] left , int[] right ) =>
left.length == right.length &&
left.Zip(right)
.All(x => x.Item1 == x.Item2);Не уверен что так лучше. Но на мой взгляд почище и проще, чем вариант на циклах.
Еще один плюс, знаете как будет выглядеть функция которая считает это всё дело параллельно? А вот так:
bool isEqual(int[] left, int[] right) =>
left.Length == right.Length &&
left.Zip(right)
.AsParallel()
.All(x => x.Item1 == x.Item2);Достаточно дописать одну строчку.
С циклами так не работает, к сожалению.
В ленивом языке (например, в хаскелле) это будет эквивалентный код.
Тут дело не в ленивости, а в понимании, что дальнейшее итерирование не поменяет результата. Вы уверены, что компилятор хаскеля достаточно умный, чтобы добавить соответствующую проверку?
Да, уверен. Например, делаем правую свертку на бесконечном списке (то есть идем справа от бесконечности), но компилятор хаскеля как-то догадывается посчитать правильный ответ:
foldr (\x xs -> if x > 10 then [] else x:xs) [] [1..]
[1,2,3,4,5,6,7,8,9,10]
Да, на главной странице https://www.haskell.org/ встроен рабочий интерпретатор
У вас тут есть явно терминирующее значение []. С логическими значениями всё не так очевидно.
Как? 0_о
Если развернуть последовательность foldr то вы получите последовательность:
foldr (:) [] [1..]
1 : foldr (:) [] [2..]
1 : 2 : foldr (:) [] [3..]
...Когда компилятор дойдет до 10 он увидет, что правое значение никак не используется (условие if x > 10 в лямбде), значит дальше вычислять не надо, и успешно завершит функцию.
Чуть измененный пример:
foldr (\ x y -> if (mod x 10 == 0) then [-1] else x:y) [] [1,2..]На первой встреченной десятке в выражении для foldr:
foldr f r0 A = A1 `f` (A2 `f` (... An-2 `f` (An-1 `f` (An `f` r0)) ...))правый операнд f просто заменяется на значение [-1], и на этом вычисление оказываются полностью построенным как задано в описании. Остается только редуцировать его до результирующего значения (с помощью такой же процедуры последовательных простых подстановок).
Мне кажется, это объяснение подходит для того что уже это знает, но они и так знают :)
А кто не знает — ничего не понял.
Это ленивость работает. С булевыми значениями она, как будто бы, не поможет — в отличие от списков.

В лени нет никакой магии, её поведение вполне себе детерменировано и предсказуемо, так что и надеяться на ум компилятора не обязательно.
В ленивом языке (например, в хаскелле) это будет эквивалентный код.Это как? Haskell знает, что если один из множителей равен 0, то можно останавливать свёртку, т.к. дальше умножать бессмысленно — произведение всё равно будет 0? Если да, то это в некоторых случаях очень плохо — лишнее сравнение внутри цикла может убить производительность.
Вы ведь понимаете, что это всё вопрос дефолтов. В обычных языках ленивость можно исскуственно включать (те же итераторы в сишарпе так работают), а в хаскелле по-дефолту всё ленивое, но при желании где надо это можно отключить.
Так что вы правы, иногда лень и лишние проверки только вредят, поэтому есть механизмы их выключения. Но часть позволяют писать вот такие изящные решения.
В вашем примере с
.Foldr(true, (acc, item) => acc && item.left == item.right);имеет ли право компилятор залезть в переданную в Foldr лямбду и делать какие-либо предположения/оптимизации на основе её содержимого.
Нет, не нужно (но можно).
Каким образом? Умный компилятор не будет ставить лишнее сравнение.
Тут как раз вопрос в том, почему он оптимизирует && (меняет местами операнды). По сути же на "acc && item.left == item.right" он должен виснуть, а на "item.left == item.right && acc" — нет, т.к. foldr f init xs встает как раз на место acc.
Вопрос в том, что означает a == b. В каком-нибудь хаскеле это инструкция создать Trunk с таким действием, но рантайм не будет его выполнять если он видит что результат не используется. А в си просто посчитает и вернет результат.
У вас мало того, что наглядность просела, так ещё и производительность — итерируетесь по всему списку, хотя достаточно было бы остановиться на первом же различии.
В общем-то это не задача для решения через комбинаторы, но вот:
isEqual left right =
length left == length right
&& (all id $ zipWith (==) left right)для списков это решение эвалюирует весь список, чтобы посчитать длины.
Простой рекурсией это решается лучше:
isEqual (x:xs) (y:ys) = x == y && isEqual xs ys
isEqual [] [] = True
isEqual _ _ = FalseНу и вариант для вектора, который полностью эквивалентен императивной лапше с циклами и ранним выходом.
isEqual a b = V.length a == V.length b
&& all id
$ zipWith (==) (V.toList a) (V.toList b)private static bool AreEqual(int[] left, int[] right) =>
left.Length == right.Length && left.Zip(right).All(p=>p.First == p.Second);Забыли сравнить длины.
Что у вас будет в случае массивов разной длины?
Подумал, можно ещё и так сделать, хотя и не на свёртке:
private static bool AreEqualToo(int[] left, int[] right)
=> !left.Except(right).Any() && !right.Except(left).Any();
Надеюсь, вопросы производительности мы вынесли зв скобки в этом обсуждении.
Но это ж разные проверки! Первая сравнивала два списка, а тут вы сравниваете два множества.
Зря надеетесь. Ни производительность не вынесли, ни потребление памяти.
Вы тут создаете аж две хэшмапы просто чтобы проверить что там есть элементы. Это очень нехорошее решение по многим параметрам. Да и читается имхо хуже чем просто проверка Any(x => x.left == x.right)
Вариант на Rust:
fn is_equal(left: &[i32], right: &[i32]) -> bool {
left.len() == right.len() &&
left.iter().zip(right.iter())
.all(|(l, r)| l == r)
}all() is short-circuiting; in other words, it will stop processing as soon as it finds a false, given that no matter what else happens, the result will also be false.
int value = a[i];Это тут зачем?
Мне ближе вариант №1 из-за того, что у меня циклы настолько тривиальными остаются крайне редко. И то, что было
for (i = 0; i < end; i++) частенько превращается во что-нибудь вроде for (i = start; i < end; i+=step) в процессе разработки.Извините, но вот это функциональное изящество выглядит прикольно только в тривиальных случаях, в которых по большому счёту без разницы.
Это тут зачем?
Чтобы не вычислять два раза индекс a[i]. Можно конечно понадеяться что компилятор соптимизирует, но может и нет.
Извините, но вот это функциональное изящество выглядит прикольно только в тривиальных случаях, в которых по большому счёту без разницы.
Не соглашусь, но дальше спорить смысла не вижу.
b[i] = a[i] * a[i]; должно быть b[i] = value * value;? Или там какая-то внутренняя магия компилятора со ссылками?Не соглашусьПосмотрите на собственный пример чуть выше, который длиннее реализации с foreach раза в полтора и ничуть не более понятен.
Верно, я забыл value использовать. Кстати, это можно косвенно считать аргументом в пользу итераторов. По крайней мере для невнимательных людей вроде меня.
Посмотрите на собственный пример чуть выше, который длиннее реализации с foreach раза в полтора и ничуть не более понятен.
Ну в данном случае соглашусь (впрочем, пример специально был придуман таким образом).
Хотя я не уверен, какой вариант я бы использовал в своем коде. В таком простом варианте — наверное цикл. В чуть более сложном лучше бы взять итераторы.
А тут смотря что под ООП понимать. Наследование реализации я лично не одобряю. Инкапсуляция это общий принцип программирования, не знаю почему именно с ООП его ассоциируют, без него никуда. Полиморфизм тоже нужен, потому что списки разных объектов нам ведь хочется иметь? И обобщенные функции писать.
А что лично вы вкладываете в этот термин? Остальные атрибуты ФП — это какие? Как я говорил, писать всё на комбинаторах необязательно, просто это удобно. Да, после циклов выглядит немного чужеродно, но тут вопрос привычки. Пописать так год, потом на циклы смотреть не захочется, уверяю вас :)
Хотя бывают сценарии, когда они лучше, безусловно.
Инкапсуляция это общий принцип программирования, не знаю почему именно с ООП его ассоциируют, без него никуда.
Потому что согласно википедии инкапсуляция это упаковка методов и полей в одном объекте. И получается, если у тебя есть объект, в котором есть и методы и публичные поля, то инкапсуляцией ты уже воспользовался.
А тут смотря что под ООП понимать.Приклеивание процедур к struct-ам и написание всего кода так. Нафигачивание слоёв абстракций сверху для решения проблем, вызванных самим же подходом.
А что лично вы вкладываете в этот термин? Остальные атрибуты ФП — это какие?Иммутабельность, комбинаторы, замыкания, рекурсия вместо циклов, каррирование, из того, о чём обычно вещают.
Да, после циклов выглядит немного чужеродно, но тут вопрос привычки. Пописать так год, потом на циклы смотреть не захочется, уверяю вас :)Немного порефлексировал, и понял, что мне так не нравится в этой затее. А то, что комбинаторы — частное решение, в то время, как циклы — общее. Без _значительного_ профита частное решение я просто не буду использовать, когда есть более общее. Насчёт удобства — кому как.
Приклеивание процедур к struct-ам и написание всего кода так. Нафигачивание слоёв абстракций сверху для решения проблем, вызванных самим же подходом.
Ну если ООП определять как "набор костылей и оверинжинеринг" то оно действительно не ок. Но мне кажется, люди обычно что-то другое подразумевают. А без общего понятийного аппарата договориться трудно.
Немного порефлексировал, и понял, что мне так не нравится в этой затее. А то, что комбинаторы — частное решение, в то время, как циклы — общее. Без значительного профита частное решение я просто не буду использовать, когда есть более общее. Насчёт удобства — кому как.
Так наоборот же. Например если вы хотите использовать цикл со счетчиком, вы возьмете "частный" for, хотя он является частным случаем while. Так же можно логику продолжить дальше. Чем более "конкретный" метод используется, тем меньше нужно смотреть на тело цикла чтобы понять какой результат получится. Ну и писанины меньше, часть логики спрятана в методе. Этакий юникс вей где лучше иметь небольшие функции, делающие своё дело, чем один гигантский MakeEverythingGood, который и жнец, и на дуде игрец (for).
А без общего понятийного аппарата договориться трудно.Ну как в ООП завезут общий понятийный аппарат, тогда можно о нём будет говорить. Извините за резкость, но надоело, что технология, которой много лет, до сих пор требует сверки понятий перед тем, как о ней поговорить. Приклеивание процедур к struct-ам — самое однозначно трактуемое определение ООП из известных мне.
Этакий юникс вей где лучше иметь небольшие функции, делающие своё дело, чем один гигантский MakeEverythingGood, который и жнец, и на дуде игрец (for)Мне больше нравится подход: «немного базовых элементов и комбинаторный взрыв».
Приклеивание процедур к struct-ам — самое однозначно трактуемое определение ООП из известных мне.
В расте есть приклеивание методов к структам, а наследования нет. Он ООП?
Мне больше нравится подход: «немного базовых элементов и комбинаторный взрыв».
Ну вот комбинаторы это как раз про это. Их ведь немного: Fold(самый базовый)/map/filter/any/all/zip/unzip/groupby/orderby. По сути всё. Запомнить их очень нетрудно, как мне кажется. Да и что они делают понятно из названия.
В расте есть приклеивание методов к структам, а наследования нет. Он ООП?Значит на расте ООП возможно.
Запомнить их очень нетрудно, как мне кажется.Их, и, чтобы достигнуть понимания происходящего на одном уровне с императивщиной в цикле, все их реализации на всех языках, которые используешь.
Да нет, зачем мне реализация? Хотя не вижу ничего сложного в том, чтобы реализовать на любом языке. Ну вот All например
bool All<T>(this IEnumerable<T> source, Predicate<T> predicate) {
foreach (var v in source) {
if (!predicate(v)) return false;
}
return true;
}Не вижу проблем написать это на любом языке.
При этом и посылка неверная. Я сходу не напишу GroupBy эффективно на любом языке. Пользоваться им это мне не мешает.
Да нет, зачем мне реализация?Затем, чтобы понимать, что конкретно происходит.
Вы абсолютно точно уверены, что все без исключения комбинаторы выдадут одинаковый результат во всех популярных языках на всех кейсах? Я — нет.
Да, для стандартных комбинаторов и вменяемых языков я в этом уверен.
Вы абсолютно точно уверены, что все без исключения комбинаторы выдадут одинаковый результат во всех популярных языках на всех кейсах? Я — нет.
Развивайте уверенность, что тут скажешь :)
Ну хотите — знайте. Перейдите к исходникам стд (в сишарпе по одной кнопке можно сделать), посмотрите на реализацию, и убедитесь, что они ничего страшного не делает.
Лично я реализации из стандартной библиотеке доверю больше, чем "инхаус решениям". А вы?
Если я пользуюсь чем-то, я хочу знать об этих вещах, чтобы не плодить баги. Надеяться на то, что инструмент поведёт себя так, как я ожидаю, меня отучил foreach в PHP очень давно.
Я не могу обосновать для себя такие усилия для фич, которые не привносят ничего нового, но являются потенциальным источником мелкого бага.
Лично я реализации из стандартной библиотеке доверю больше, чем «инхаус решениям». А вы?Я больше доверяю тому, внутреннее устройство чего я понимаю. И мне глубоко до лампочки «инхаус» это или нет.
Так наоборот жеЭто зависит от модели вычислений. Если у нас машина Тьюринга, то изменения состояний (они же branch, или уровнем чуть выше — if/for/while) — первичны. Если брать за основу λ-исчисление, то комбинаторы первичны. Просто не надо думать о программах, как о λ-выражениях ))) Думайте о них, как об инструкциях для традиционного процессора.
Думайте о них, как об инструкциях для традиционного процессора.
Самое время вставить тут ссылку на статью "Си это не низкоуровневый язык" :)
Думать надо в терминах, в которых легко думать. Во что там оно компилируется — дело десятое. И как показывает практика, это наоборот упрощает дело, включая оптимизации, потому что когда реализация не прибита к модели вычислений можно по щелчку пальцев, например, распараллелить всё это дело. А на циклах написанный код придется весь потрошить и переписывать.
Не заметно, чтобы на лямбдах что-то такое пытались. Хотя подходы эквивалентны. Значит, МТ удобнее в смысле исследования вычислений.
Одновременно с этим большая часть передовых подходов в software engineering приходит со стороны лямбда-счисления.
Я бы не стал опираться на то, что с МТ некоторые теоремы доказывать проще.
Серьёзно. Any/All/Filter это всё высказывания на уровне теории множеств. "Все","Любой","Такие, что" и так далее. Все люди, с которыми я общался, когда им непонятно начинали на бумажке рисовать объекты, стрелочками обозначать связи, обозначать кто кому кем является, и т.п. И ни разу не видел людей которые начинают писать "шаг один — записать такое-то значение в такую-то ячейку".
Хотя один раз я так делал, когда пытался понять, как работает конкретный алгоритм, и я по сути на бумажке его дебажил. Если бы он был написан в терминах трансформации данных, скорее всего делать так мне бы не пришлось.
Самое время вставить тут ссылку на статью «Си это не низкоуровневый язык» :)Так никто не говорит, что модель процессора из 1980-х действительно соответствует реальному процессору. Но на ней удобно думать, и программисты так и делают.
се люди, с которыми я общался, когда им непонятно начинали на бумажке рисовать объекты, стрелочками обозначать связи, обозначать кто кому кем является, и т.п. И ни разу не видел людей которые начинают писать «шаг один — записать такое-то значение в такую-то ячейку»Только объяснение любого нетривиального алгоритма, вроде RB-дерева, или quicksort/mergesort элементарно в нотации ячеек памяти и превращается в аццкий ад, когда функциональщики пытаются эти же алгоритмы на своём эльфийском писать )))
Так никто не говорит, что модель процессора из 1980-х действительно соответствует реальному процессору. Но на ней удобно думать, и программисты так и делают.
Позвольте не поверить. Мне лично неудобно думать. И я не знаю людей, которым правда это удобно. Есть люди, которые говорили что им удобно, но попытка удержать хотя бы 10 мутабельных переменных в цикле сразу расставляла всё по своим местам.
Только объяснение любого нетривиального алгоритма, вроде RB-дерева, или quicksort/mergesort элементарно в нотации ячеек памяти и превращается в аццкий ад, когда функциональщики пытаются эти же алгоритмы на своём эльфийском писать )))
Мержсорт отлично на ФП переносится. Квиксорт, впрочем, тоже.
Это не отменяет того, что некоторые алгоритмы удобнее в виде пошаговых инструкций. Но имхо это скорее исключение, чем правило.
Вот как раз mergesort в функциональном подходе пишется проще всего (если не пытаться написать его inplace-вариант, конечно же).
И персистентное RB-дерево тоже в функциональном варианте выглядит довольно просто.
В целом же, претензия очень странная. Разумеется, любой алгоритм, изобретенный в нотации ячеек памяти, хорошо описывается именно в нотации ячеек памяти. Но у функциональщиков есть свои алгоритмы, которые на "ячейки памяти" так просто не налезают...
Так может во втором варианте еще и Pow(x, 2) использовать — так еще лучше задачу иллюстрирует :)
Ну а я в последнее время предпочитаю сильно оптимальный код, который редко бывает функциональным. Во втором случае лишние аллокации еще могут быть.
Так может во втором варианте еще и Pow(x, 2) использовать — так еще лучше задачу иллюстрирует :)
Стараюсь не использовать эту функцию, потому что она работает с double-аргументами. А выходить за пределы int-арифметики очень не люблю, чтобы потом не получить в одном килобайте 1023.937528 байт.
Ну а я в последнее время предпочитаю сильно оптимальный код, который редко бывает функциональным. Во втором случае лишние аллокации еще могут быть.
Ну тут от языка зависит. В том же расте итераторы эффективнее ручных циклов, потому что он генерирует такой же код, как вы бы руками написали, но при этом не делает проверок выхода за границы (потому что статически уже всё проверил) и векторизует получше.
Понятно, что на нагруженных местах так делать не стоит. Но там я бы скорее смотрел в сторону более производительных инструментов, того же хаскелля или раста.
Для второго варианта можно, например, предположить, что для массива a вызывается метод, который превращает этот массив в map (вероятно, что-то на основе деревьев а не хеш-таблиц) таким образом, что для каждого элемента исходного массива вызывается лямбда, в которую этот элемент передаётся аргументом, а результат записывается в создающуюся map. Затем получившийся map опять преобразуется в массив. Вполне возможно что в чём-то я ошибаюсь, но более-менее знаю только плюсы. Я к тому, что первый вариант очевиден в общем-то кому угодно, для второго — для понимания надо знать особенности конкретного языка и его стандартной библиотеки.
Ну map это функция которая занимается отображением, к хэшмапе отношения никакого не имеет. В C++ практически такая же функция называется transform. Вот так через неё выражается map:
template<typename Src, typename Dst, template<class, typename ...> typename Container>
Container<Dst> map(Container<Src>& container, Dst(*f)(Src)) {
Container<Dst> result;
result.reserve(container.size());
std::transform(container.begin(), container.end(), std::back_inserter(result), f);
return result;
}Используется вот так:
vector<int> a = {1, 2, 3};
auto f = [](int x) -> int { return x*x; };
vector<double> b = fmap(a, +f);Работает так же, как и код C# выше, за исключением того, что он требует аллокации вектора куда складывать результаты, а в C# у вас ленивый итератор.
Разница между map как функцией и Map как структурой данных такая же, как между программным стеком и структурой данных Stack. Можно путаться, но это скорее новичковая ошибка, и один раз узнав разницу уже не перепутаете.
Смущает только строчка int value = a[i];
Это я хотел в переменную засунуть чтобы два раза индекс не брать (мало ли, в сишарпе компилятор не такой умный как плюсовый, может и не соптимизировать), да вот опечатался. С итераторами, к слову, опечататься негде :)
Метод, который превращал бы массив в Map, назывался бы ToMap. А одиночное слово "Map" явно имеет какой-то другой смысл...
(1..n)
Хе-хе. Границы ренжей в сишарпе 8 имеют разную инклюзивность.
Неужели это читается менее понятно чем вариант с циклами?
Вообще совершенно не читается, вариант с циклом намного понятнее. В данном варианте надо знать детали реализации функции Fold. Почему чисел n а лямда умножает два? В каком порядке они умноваются? (в данном случае конечно неважно, но в других случаях может) Все ли числа передаются в лямду? По одному ли разу они туда передаются?
Куча вопросов
Различные комбинаторы вроде свёрток, фильтров, отображений обычно заучиваются раз и навсегда, после этого уже не вызывая трудностей в восприятии. Цикл же приходится перечитывать каждый раз как первый.
UPD.: Кроме того, названия этих комбинаторов, как правило, не меняются от языка к языку, так что выучив этот DSL на одном языке ты скорее всего поймёшь его и на другом.
Давайте проверим, выполняется ли наше правило для первой функции? Оказывается, что нет, потому что если мы заменим где-нибудь Factorial(5) на 120 то у нас поменяется поведение программы — в логи перестанет писаться информация которая раньше записывалась (хотя если мы подойдем с позиции "да и хрен ними, с логами" и не будем считать это желаемым поведением, то программу можно будет считать чистой.
Чистая функция не может писать в логи. Единственное место где вы можете узнать как отработала функция это ее результат. Если результать одинаков, то вы никак не узнаете как и что там произошло.
Концептуально, функции не исполняются, а только превращают аргументы в результат:
public static int Add1(int x)
{
switch (x)
{
case 0: return 1;
case 1: return 2;
...
}
}
Никакого поведения тут нет.В целом — не надо вводить людей в заблуждение, указывая на некоторые случаи, когда неизменное состояние внешних переменных может быть полезно. И тем более — ни в коем случае нельзя приписывать это «достижение» исключительно ФП. Последнее может утверждать только человек, крайне поверхностно знакомый с альтернативами (либо вообще о них не знающий).
Программирование сложнее примитивного деления на «мне нравится ФП» и «мне не нравится ФП». Сторонники ФП по необразованности, к сожалению, часто ставят себя выше остальных, и всё лишь потому, что они обнаруживают в ФП лишь некоторые возможности, которые давно есть в других языках. Ну и в результате выставляют себя глупцами, да. А как ещё назвать людей с самомнением, да к тому же не желающих изучать альтернативы?
Ну и до кучи — возможность изменять внешнее состояние полезна. И если язык позволяет эту возможность использовать — это хороший язык. А если программист при использовании этой возможности не умеет избегать ошибок — это плохой программист. Сторонники ФП нашли выход из такой ситуации — запретили менять внешнее состояние. Просто потому, что считают всех плохими программистами. А как иначе объяснить запрет? Ведь если мы исходим из предположения о грамотном использовании инструмента, то и запрещать ничего не нужно, ведь грамотный пользователь и сам знает, где очередные грабли лежат.
Поэтому речь может идти лишь о наличии альтернативных подходов к разработке. Вот просто в мире есть альтернативы, и всё. Хочешь — пользуйся, не хочешь — не пользуйся. А утверждать, что якобы одна из альтернатив чего-то там делает за программиста — ну бред же. Ошибок можно наворотить бесконечное количество в любом языке. А указывать лишь на один класс ошибок (из миллионов) и при этом гордо задирать нос, мол вот мой любимый подход (ФП) какой прекрасный, это признак очень ограниченного интеллекта. То есть — не надо так себя вести. Даже неявно, когда, как например в данной статье, автор просто забыл про все альтернативы и опять увлекательно нам рассказал, что он недавно узнал, как некоторые языки позволяют отловить один единственный класс ошибок. А все остальные ошибки кто ловить будет?
Сторонники ФП по необразованности, к сожалению, часто ставят себя выше остальных, и всё лишь потому, что они обнаруживают в ФП лишь некоторые возможности, которые давно есть в других языках.
Чушь полная. Большинство фич в мейнстримовые языки приходят из ФП. Начиная от генериков, которые хрен знает когда появились в жаве, заканчивая ADT, которые кое-как добираются до мейнстрима, встречают дикий восторг императивных программистов, хотя в ФЯ они появились ещё в 80-е.
А как ещё назвать людей с самомнением, да к тому же не желающих изучать альтернативы?
Люди в ФП приходят обычно не в начале карьеры, а уже после изучения альтернатив.
Ну и до кучи — возможность изменять внешнее состояние полезна. И если язык позволяет эту возможность использовать — это хороший язык. А если программист при использовании этой возможности не умеет избегать ошибок — это плохой программист. Сторонники ФП нашли выход из такой ситуации — запретили менять внешнее состояние.
Чушь, никто ничего не запрещал. А вообще человеку свойственно допускать ошибки и не надо ляля по поводу того, что это все баги и уязвимости в IT порождены плохими программистами. Человек может устать, может заболеть, может просто ошибиться по невнимательности.
А указывать лишь на один класс ошибок (из миллионов) и при этом гордо задирать нос, мол вот мой любимый подход (ФП) какой прекрасный, это признак очень ограниченного интеллекта.
ФП хорошо не тем, что решает какой-то класс ошибок, а даёт разумные ограничения, которые позволяют проводить local reasoning и тратить меньше времени на понимание кода. Но людям, которые на это всё дело смотрят сугубо со стороны, конечно же такого не понять. В итоге как-то так получается, что все, кто умеет в ФП — сторонники ФП, все кто не умеет — его противники, а людей которые умеют в ФП и при этом ему оппонируют, почему-то дефицит. Это при том, что большинство сторонников ФП, если надо, могут и на C что-то низкоуровневое и на джаве какую-нибудь опердень написать (но скорее всего не станут).
А вся эта идеологическая шелуха про «ФП позволяет писать надёжно» и тому подобное, есть следствие глубокого непонимания сторонниками ФП всего остального мира, связанного с созданием программ.
Подождите, если вы говорите что все понятия ФП были задолго до ФП придуманы. Ну, если вам так проще, называйте это "общепринятые хорошие практики независимости модулй", если вам кажется, что ФП украли лавры и присвоило себе чужие заслуги.
Если вы не согласны, что написание независимых модулей, состояние которых не влияет друг на друга, то можете подробнее рассказать, как это получается? У меня сходу не получается такого представить. Меньше взаимосвязей — больше надежность. Low coupling high cohesion как они есть.
В целом — не надо вводить людей в заблуждение, указывая на некоторые случаи, когда неизменное состояние внешних переменных может быть полезно. И тем более — ни в коем случае нельзя приписывать это «достижение» исключительно ФП. Последнее может утверждать только человек, крайне поверхностно знакомый с альтернативами (либо вообще о них не знающий).
Называйте как хотите. ФП так называется не для того, чтобы присвоить чьи-то заслуги (как я уже сказал), а чтобы был общий понятийный аппарат. Вот вы сказали "абстрактная фабрика", и все сразу всё поняли. Сказали "ФП", и все поняли, что речь о программе написанной в чистых функциях.
Ну и до кучи — возможность изменять внешнее состояние полезна. И если язык позволяет эту возможность использовать — это хороший язык. А если программист при использовании этой возможности не умеет избегать ошибок — это плохой программист. Сторонники ФП нашли выход из такой ситуации — запретили менять внешнее состояние. Просто потому, что считают всех плохими программистами. А как иначе объяснить запрет? Ведь если мы исходим из предположения о грамотном использовании инструмента, то и запрещать ничего не нужно, ведь грамотный пользователь и сам знает, где очередные грабли лежат.
Ну так вы же можете менять внешнее состояние, только не напрямую. А эта индирекция позволяет вам иметь все плюсы чистоты, и оставаться при этом приложением которое может что-то полезное сделать.
А если программист при использовании этой возможности не умеет избегать ошибок — это плохой программист.
Как говорил один мой знакомый: "Я у программистов на низкоуровневых языках несколько раз спрашивал зачем им в офисах перила, двери в лифтах и т.п. Мешают оптимизации перемещений-же, а настолько элементарные ошибки они не делают. Не ответили.".
Когда люди совершают ошибки с инструментом, хороший путь — починить инструмент. Плохой — ругать людей, и говорить, что они плохие и неправильные.
Поэтому речь может идти лишь о наличии альтернативных подходов к разработке. Вот просто в мире есть альтернативы, и всё. Хочешь — пользуйся, не хочешь — не пользуйся. А утверждать, что якобы одна из альтернатив чего-то там делает за программиста — ну бред же. Ошибок можно наворотить бесконечное количество в любом языке. А указывать лишь на один класс ошибок (из миллионов) и при этом гордо задирать нос, мол вот мой любимый подход (ФП) какой прекрасный, это признак очень ограниченного интеллекта.
Есть такая штука, как паретто-оптимальность. Если какой-то инструмент строго лучше в каком-то аспекте (помогает решать какой-то класс проблем), и при этом не хуже в остальных аспектах (просто не хуже, не обязательно лучше), то он уже может считаться лучшей альтернативой.
Даже неявно, когда, как например в данной статье, автор просто забыл про все альтернативы и опять увлекательно нам рассказал, что он недавно узнал, как некоторые языки позволяют отловить один единственный класс ошибок. А все остальные ошибки кто ловить будет?
Можно примеры, какие альтернативы я забыл и какие другие ошибки могут произойти, с которыми ФП ничего сделать не может, а какой-то другой подход может. Кстати, какой? Как я в конце статьи подвел, ФП не противоречит никаким другим парадигмам. Можно с ООП совмещать. Можно с процедурным сишным (придется процедуры в IO завернуть, но всё же). ФП это не про хаскелль, а про то, что функции не делают "странного", если неформально описать о чем фп.
идеологическая шелуха
следствие глубокого непонимания сторонниками ФП всего остального мира
человек, крайне поверхностно знакомый с альтернативами (либо вообще о них не знающий)
Сторонники ФП по необразованности
выставляют себя глупцами
не желающих изучать альтернативы
признак очень ограниченного интеллекта
автор просто забыл про все альтернативы
Что-то мне подсказывает что вы несколько предвзяты.
Если вы не согласны, что написание независимых модулей, состояние которых не влияет друг на друга, то можете подробнее рассказать, как это получается?
У меня к вам просьба — прочитайте процитированный выше ваш текст и найдите в нём смысл. Я не нашёл.
ФП так называется не для того, чтобы присвоить чьи-то заслуги (как я уже сказал), а чтобы был общий понятийный аппарат.
Общий понятийный аппарат формируется не случайным образом, а задаётся авторами аппарата. Так вот авторы исходили из применимости к программированию абстрактного понятия «математическая функция». Вы же выше написали, что якобы функциональное программирование, это про чистые функции, не меняющие состояние вне самих функций. Но нет, я ещё раз подчеркну — это не так, не про внешнее состояние речь, а про попытку применить математические абстракции в программировании.
Да, от математической абстракции можно прийти к чистым функциям ФП, но это лишь логическое следствие, не являющееся изначальной основой подхода. Поэтому я и написал, что вы вводите людей в заблуждение.
Ну так вы же можете менять внешнее состояние, только не напрямую. А эта индирекция позволяет вам иметь все плюсы чистоты, и оставаться при этом приложением которое может что-то полезное сделать.
Я писал про запрет, а вы мне про «на самом деле, если долго и нудно копать, то запрет можно обойти». Я в курсе, что затрата приличного количества пота иногда помогает сделать что-то полезное, но про изначальный запрет-то зачем забывать? Причина пота — запрет. Он есть. И если он есть, то уже не важно, в наличии ли какие-то решения «через задний проход» или они отсутствуют, ведь главное — запрет есть.
Я у программистов на низкоуровневых языках несколько раз спрашивал зачем им в офисах перила, двери в лифтах и т.п.
И вашему знакомому наверняка уже отвечали — перила есть не везде, а лифты — и подавно. Потому что экономически невыгодно везде ставить перила и лифты. И да, иногда невыгодно потому, что они реально мешают. Ну и точно такая же ситуация с уровнями языков. Правда здесь вы попутали уровни с дилеммой «ФП или не ФП», то есть опять придали ФП несуществующую в реальности роль якобы «высокого уровня», ну да я к такому уже привык, поскольку в разговорах со сторонниками ФП всегда встречаю что-то подобное, когда вместо ответа на конкретные факты мне начинают рассказывать какие-то сказки, как вот например про уровни и т.д.
Когда люди совершают ошибки с инструментом, хороший путь — починить инструмент. Плохой — ругать людей, и говорить, что они плохие и неправильные.
Вы как наши правители — ну вот надо им с нас денег содрать, вот они и доказывают, что «это хороший путь». И плевать им на все возражения. Просто потому, что реальная причина не «хороший путь», а банально денег хотят.
Инструмент (язык программирования в частности) нужно не чинить, а совершенствовать. И если у вас совершенствование ассоциируется с запретами, то вы неправы. Запрет — это примитивнейший способ устранения проблемы. Он почти всегда работает неэффективно. А правильный способ устранения проблемы — сделать совершенное решение. То есть такое, в котором не запретами добиваются нужного результата, а при при помощи учёт множества важных деталей. Поэтому не становитесь в позу нашего правительства, не запрещайте всё на свете, это по вам же потом ударит.
Можно примеры, какие альтернативы я забыл и какие другие ошибки могут произойти, с которыми ФП ничего сделать не может, а какой-то другой подход может
Ну возьмите хотя бы так любимые вами рекурсии. В императиве их обычно реализуют в виде циклов, где есть начало и конец (стандартная конструкция for), а в функциональных языках с их ленивостью предсказание результата рекурсивных вызовов, да ещё с бесконечными списками, внезапно, становится головной болью.
Вообще претензий к ФП, если серьёзно взяться, можно наковырять немало, так что здесь вы просто закрываете глаза на то, что в общем-то обязаны и так знать, являясь сторонником ФП. Собственно все отличия ФП от императива даются не бесплатно, а потому все они имеют минусы, но вы вот мне (отнюдь не стороннику ФП) задаёте вопрос — а какие минусы имеет мой любимый подход? Так он же ваш любимый, а не мой! Но я, тем не менее, вам отвечаю. Только вот у меня возникает вопрос об объективности вашего подхода. То есть вы не видите минусов и видите лишь одни плюсы. Прямо так выше и написали. Но объективно ли это?
Что-то мне подсказывает что вы несколько предвзяты
Ну я вам уже отвечал выше — постоянно сталкиваюсь со сторонниками ФП, которые упорно талдычат про сплошные плюсы их любимого подхода, но никогда ни один из них не соглашался, если я им говорил о минусах. Всегда мне либо рассказывали сказки про «ну есть же возможность обойти», либо вообще уводили в какие-то не относящиеся к вопросу дебри. Вот поэтому я и стал слегка предвзятым.
А в каком разделе математики есть изменяемое состояние?
A function f is a mathematical entity with the fol-
lowing properties:
F–1 f has a domain and a codomain, each of which must be a set.
F–2 For every element x of the domain, f has a value at x, which is an
element of the codomain and is denoted f(x).
F–3 The domain, the codomain, and the value f(x) for each x in the domain
are all determined completely by the function.
F–4 Conversely, the data consisting of the domain, the codomain, and the
value f(x) for each element x of the domain completely determine the
function f.
The domain and codomain are often called the source and target of f,
respectively.
От F-3 и F-4 до упрощенного термина «чистая функция» в контексте программирования — 1 шаг. Поэтому о какой-то притянутости чистоты/неизменности состояния говорить не стоит — это заложили не основоположники ФП по своей прихоти, а естественным образом вытекает из той области абстрактной математики, на основе которой ФП и основано.
Или хотя бы не показываете, почему он еще не достаточно функциональный.
Честно говоря, не вижу смысла в F#. Ну то есть это тот же C# только с АДТ и странным синтаксисом. При этом под который не работает куча привычных инструментов. Одни только АДТ того не стоят (особенно с релизом паттерн матчинга в C# 7.3), а других плюсов то и нет.
Любые настоящие ФП фичи вроде ХКТ коммьюнити встречает в штыки. Ну а как в ФП языке без ХКТ. Никак. Ведь неизменяемость значений ведет к тому, что вам очень много всего нужно писать. Если у вас язык не позволяет это инкапсулировать (а для этого и нужны типы высших порядков), то вы очень быстро устанете.
Инструмент должен помогать, а не требовать написания бесконечного бойлерплейта.
А что такое ХКТ — я по быстренькому не нашел?
Higher kinded types. Вот пропозал в сишарп: https://github.com/dotnet/csharplang/issues/339
Higher-Kinded Types
и странным синтаксисом.
Но ведь это обычный ML...
Но если вы уже настроились на ML то лучше взять хаскель, разве нет?
Но если вы уже настроились на ML то лучше взять хаскель, разве нет?
Конечно нет, ведь фшарп это в первую очередь дотнет, нугеты, вижуал студия, ажура и отличный рантайм. То что называется экосистема. Хаскель курит в сторонке
Фшарп затем на дотнете и задумали чтобы присосаться к готовому набору пакетов, а не делать свои с нуля (привет оКамлу, да и хаскелю)
Драйвера ДБ, СДК, UI, асп нет тот же. Их незачем переписывать.
Если для Вас это не аргумент, то вперёд писать прод на Блодвене.
Для фшарпа идиоматично ООП. Это не функциональный язык. Те кто ищет от фшарпа хаскеля, его не найдут. Вполне идиоматично юзать весь набор сишарп кода. Это не только мое мнение, а ещё и автора языка Дона Сайма. Ознакомиться с этим мнением можно в его книге Expert F#.
Большинство усилий направляется на совместимость с сишарпом, а не на ФП фичи именно поэтому.
Ну, я как-то года четыре назад решил написать на питоне нечто, лазающее в MS SQL. С удивлением обнаружил, что один из имеющихся драйверов тупо обрезает все колонки базы типа varchar до 100 символов. Не то чтобы это было типично, но все-таки в мире Java и .Net такого вы скорее всего не увидите вообще. Это как-бы не очень конкретная фишка, но тем не менее такое имеет место.
Хаскель умеет в hdfs ходить?
я вполне могу себе представить Spark приложение, которое вообще ничего (ну, почти) не знает про HDFS, но при этом перелопачивает терабайты данных в нем.
Я раза три прочитал, но не понял что вы имеете в виду. Как у нас получится читать и обрабатывать файлы в файловой системе так, чтобы не знать о файловой системе?
Spark инкапсулирует в себя работу с hdfs. Программисту самому не надо вручную брать некие файлы и читать их через конвенциональный интерфейс работы с hdfs. Более того — Спарк как-то должен учитывать локальность (расположение) данных и он всю магию прячет в себя. Хотя иногда это все ломается, например, есть сделать "безопасный" кластер хадупа, в котором нельзя просто взять и прочитать произвольные данные.
Ну так в этом случае программист вообще ничего не знает про hdfs, а само приложение все прекрасно знает об hdfs.
Ну, не совсем. Вы же, например, когда работаете с БД — будь то постгрес, мускуль, оракл — не думаете же о том, как лежат файлы БД на диске? Даже драйвер БД об этом не знает. Это дело лишь самого сервера БД.
Каким образом ваш тезис опровергает мой?
Думаю что да. Поэтому и спрашиваю. Как вы так напишете спарк приложение, которое ничего не знает о файловой системе?
Теряюсь в догадках — это был ответ на мой вопрос: «И где там HDFS, если вы не создаете таблиц?» :)
val cat= spark.sharedState.externalCatalog
cat.listDatabases.foreach{println}
Почему вы считаете, что приведенное выше — не спарк приложение? Что вы хотите от приложения, чтобы для вас оно было полноценным?
На базовом уровне понимания — незачем, но когда появляются интересные нефункциональные требования, то приходится задумываться.
Простой пример когда спарк джоба нам наделала 100500 файлов, в которых данные меньше размера блока и у нас диск плохо утилизируется или потребитель этих данных плохо на маленьких файлах работает. Тогда мы в спарк джобе скажем "сделай еще один этап редьюса, чтобы файлики собрать в блоки покрупнее".
У вас что ли ни разу не было, что хайв не может работать с тем, что наделала спарк-джоба?
Так я не говорил, что вам это никогда не потребуется. Я лишь сказал, что могу представить приложение, не работающее с файловой системой.
>У вас что ли ни разу не было, что хайв не может работать с тем, что наделала спарк-джоба?
Ну, обычно это все-таки по той причине, что спарк не идеально совместим с Hive. И они по-разному понимают например бакетирование или партиционирование.
Про рантайм гхц могу лишь сказать что в бенчмарках он является одним из лучших среди маргиналов. Неплохо, но отличный он только если учесть усилия по оптимизации. Итоговая скорость так себе.
Ну так а зачем вам F#? Это тот же C#, только с возвможностью discriminated unions создавать. В чем смысл использовать его? Просто писать на ML синтаксисе? Мне кажется это скорее минус, чем плюс.
Продуктивность выше.
Меньше кода, жосче компилятор, больше абстракций. Сильно больше фич, больше возможностей для опытного программиста и при этом есть доступ к дотнету.
Там же не только ДУ (а это как бы супер), ещё комп экспрешны, цитирование, операторы, инлайн функции, SRTP и многое, многое другое.
Ну может быть, надо глянуть.
Когда последний раз я смотрел — там был "странный" сишарп. Доклад на FPure про F# меня лично не убедил, но мб докладчик не смог обосновать нормально.
И это не потому, что я боюсь ML или пугаюсь новых языков. Инлайн фунции, операторы в сишарпе давно есть. Под цитированием макросы имеются ввиду? Вот это было бы неплохо. И что такое SRTP непонятно, а то гугл выдает только Secure Real-time Transport Protocol.
Инлайна в сишарпе нет. Есть атрибут обещания джита.
Операторы только стандартные, сделать тот же '>>=' нельзя.
Извините что вторым ответом, с телефона сложно.
Цитирование это преобразование куска кода в AST с последующей работой с ним.
SRTP — statically resolved type parameters. возможность сделать хоть хкт, хоть структурную типизацию, хоть любого вида констрейны на тип. Тайп классы описываются в SRTP, да.
Цитирование это преобразование куска кода в AST с последующей работой с ним.
Ну, это очень похоже на квазицитирование в макросах, так что думаю я угадал.
SRTP — statically resolved type parameters. возможность сделать хоть хкт, хоть структурную типизацию, хоть любого вида констрейны на тип. Тайп классы описываются в SRTP, да.
А можно пример пожалуйста? А то по ссылке только накопипащенные fmap для разных типов.
Если можно, то хотелось бы увидеть, что вот так объявляется тайпкласс функтора, вот так пара реализаций (для списка и опшна, например), и вот так можно написать функцию которая будет работать с любым функтором. Сразу стало бы понятно, какие возможности у F#.
Лично мое мнение, что это все неидиоматично для фшарпа и выглядит так себе. Но тем не менее...
Вот полный набор хкт енкодинга
https://eiriktsarpalis.wordpress.com/2019/07/02/applying-the-tagless-final-pattern-in-f-generic-programs/
А вот пример инлайн сртп функции, невыразимой в сишарпе
// associate HKT encoding to underlying type using SRTPs let inline private assoc<'F, 'a, 'Fa when 'F : (static member Assign : App<'F, 'a> * 'Fa -> unit)> = ()
Ну в целом ничего, хотя в продакшн-коде я наверное использовать такое не стал HKT.pack/HKT.unpack портят всю малину. Если бы можно было от них избавиться то было бы даже юзабельно, полагаю.
Что до необходимости ХКТ, лично я считаю, что без возможность объявлять/комбинировать монады, создавать трансдьюсеры и прочее на ФП писать очень копипастно и неудобно. Хотя я, конечно, могу ошибаться.
А вот rank-2 уже нельзя. В том же хаскеле очень трудно найти библиотеку, которая могла бы без них обойтись. Ту же Cont монаду без этого никак не построить.
Единственное, что я не понял, как в ФП предлагается организовывать логирование?
Во все методы протаскивать некую лямбду
int Foo(Action<string, string> logging){
logging("info", "just info");
return 1;
}
или возвращать кортеж, чтобы рантайм пытался это интерпретировать?
(int, Log) Foo(){
return (1, new InfoLog("just info"));
}
На мой взгляд, это не очень удобно делать. Например, раньше у нас метод просто возвращал число, а теперь мы хотим добавить лог в отладочных целях. Теперь мне нужно переделать всю иерархию вызовов, чтобы она учитывала кортеж или делегат?
Если это так, то есть другой вопрос: Не будет ли расти количество аргументов в связи с этим до того момента, пока это невозможно будет воспринимать (Например, (int, string, bool, Log, TraceInfo) Foo(bool, Action, Action...) {...} )?
logAndRet1 :: HasLogger m => m Int
logAndRet1 = do
logInfo "just info"
pure 1HasLogger m здесь обозначает, что у нас монада m наделена возможностью логгирования, при этом интерпретатор логгирования определён где-то выше по колл стэку.
К сожалению, все нетривиальные вещи как я уже сказал приводят либо к куче копи-пасты (передаче доп. параметров и пропихивания их везде), либо монадам. И то и то выходит за рамки статьи. Могу только сказать, что способы есть, и мы не выйдем за рамки чистых функций. Товарищ nexmean выше в принципе показал, как это может выглядеть. И нет, это не то же самое, что просто логгировать в строгом языке, это скорее сахар для того, чтобы вместе с результатом функции вернуть логи которые надо записать.
скорее сахар для того, чтобы вместе с результатом функции вернуть логи которые надо записать
А как с оптимизацией дела обстоят? Ведь надо компилятору обратно все это раскрутить и поставить инструкцию write там где надо а не тащить это все вверх по стеку.
С оптимизацией дела обстоят неплохо. В среднем — в пару раз медленнее Rust-плюсового кода. И на порядок быстрее джавы. Я уже приводил цифры, как у нас было 4 версии приложения Java->Scala->Haskell->Rust. С каждой итерацией время выполнения падало в разы. Памяти правда скушал прилично, но всё еще меньше джавы или скалы.
Upd. Нашел картинку:
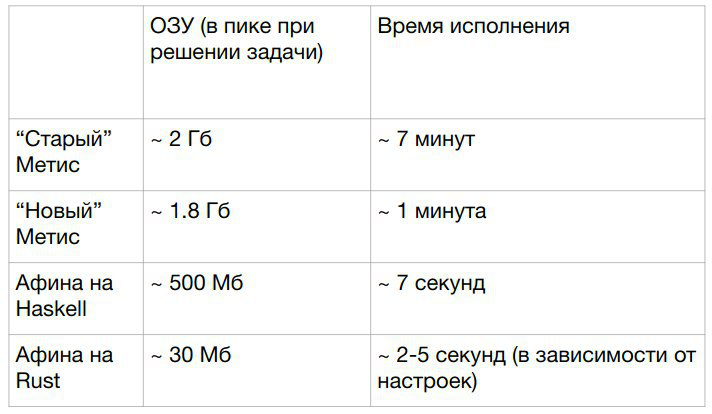
Ну а в том же компиляторе хаскелля есть встроенные правила фьюзинга, например если вы на списке делаете map filter collect то промежуточные коллекции создаваться не будут, только одна результирующая.
В общем, писать производительный код можно и нужно. Вот отличный пример от товарища 0xd34df00d
Да нет я не спрашиваю про среднюю температуру по больнице. Я спрашиваю как компилятор разворачивает монадный код. Но да ладно может вы еще напишете во второй части.
Ну, на FPure весной был доклад, там человек наоборот писал монаду для того, чтобы весь код во время компиляции оптимизировался. Там даже не зирокост получилось, а скорее оптимизация через монаду.
Так что тут зависит от конкретных реализаций. Точно так же, как например производительность "Json сериализатора" какого-нибудь зависит от конкретной имплементации.
Покажите аналогичный код на плюсах-то.
Например в rust есть предложение как можно оптимизировать случаи когда функция прозрачна к Result. Я до конца не понимаю как именно предлагается чтобы оно работало, но в этом плане хаскель еще более туманен, а подобные конструкции там кажется повсюду.
В случае в джавой-скалой потребление одно и то же.
В случае хаскелля он просто кушает поменьше + гц на нашей нагрузке интереснее работал.
В случае раста там вообще не принято особо аллоцировать. Любая аллокация в куче — это явные Box::new, которых в программах писать неудобно, поэтому их мало. Сама архитектура раста предполагает максимально переиспользование стека — поэтому перемещение значение, экзистенциальные типы и вот это всё, всё направлено на то, чтобы выделений в куче не было.
Поэтому его потребление практически константное на любых нагрузках. Программа на расте просто практически не аллоцирует память в куче.
А что у вас за объекты, которые аллоцируются? Их сколько в штуках, гигабайтах, и какой у них жизненный цикл, грубо говоря?
То есть, если я правильно понимаю, можно было бы код на условной скале попробовать привести к тому же эффекту, если убрать аллокации, и распределить память под объекты либо статически, либо как-то еще чуть хитрее?
Нельзя, потому что во-первых в JVM нет value-типов.
Во-вторых даже в языках в которых они есть куча аллокаций делают сам рантайм. Ну вот пришла к вам строка по HTTP — это аллокация в памяти. Ваш JSON-сериализатор начал её разбирать — нааллоцировал тоже кучу всего. В итоге вы еще не начали даже обрабатывать запрос который поступил, а у вас уже куча аллокаций на ровном месте. Сюда же замыкания (во всех языках они аллоцируются в куче, раст обычно аллоцирует их на стеке), генераторы, и т.п. Даже строки раст умеет аллоцировать на стеке, и десериализовывать JSON на константной памяти.
Так, с миру по нитке, голому рубаха.
Ну, это не мешает в целом работать с какими-нибудь off-heap данными. Ну то есть, я понимаю, что это будет возможно уже и не java, а хз что, я скорее тут про гипотетическую возможность так сделать.
Ну гипотетически возможно всё.
Нас интересовала практическая сторона вопроса, потому что мы разрабатывали не ради развлечения, а потому что наш сервис на джаве перестал справляться с нагрузкой и выжирал всю память.
Раст был самым простым способом. Не уверен, что мы могли бы написать что-то схожее по производительности на другой платформе. Потому что на расте мы написали максимально наивный дуболомный код, и он заработал со скоростью хаскелля на константной памяти. И дальше уже небольшими доработками еще в два раза сократили это время.
Знатоков JVM/CLR чтобы там тонко их настраивать и писать инлайн-вставки на низкоуровневых языках (потому что в некоторых местах приложения мы опускались вплоть до подсчёта кэш миссов в конкретных циклах), у нас не было, да и не уверен что получилось бы написать быстрее или лучше.
В случае с микроконтроллерами другая проблема — очень многие ФП абстракции завязаны на возможность боксить значения. А это значит, что хорошо это работает в языках с ГЦ. Ну а какой ГЦ на микроконтроллерах вы и сами понимаете.
Может стоит тогда быть хотя-бы оптимальным с опциональной ленью, а не как идрис?
Да нет, возьмем тот же раст. Там списки не являются функторами потому что у мапа сигнатура
fn map<B>(self, f: impl Fn(A) -> B) -> Map<Self<B>> { ... }В то время как результатом по идее должно было быть Self<B>. Если бы мы спрятали факт наличия типа Map за боксом у нас бы всё заработало.
Потому что компилятор потом всё это дело оптимизирует. Зиро-кост итераторы, всё такое:
Именно для того чтобы обойти боксинги и разбирать эффективно стейт машину.
Потому что вернуть ленивую обёртку выгоднее.
Ну может быть после мапа вы еще какой-то адаптер хотите дальше использовать, и всякий раз аллоцировать список после вызова адаптера — слишком накладно. Да и не понятно, коллекцию какого именно типа вы хотите получить на выходе, а может и просто некоторое единичное значение.
Поэтому после цепочки адаптеров нужно вызвать один из методов, который поглотит сконструированный итератор, выполнит его и сформирует результат. Например метод collect:
let a: Vec<_> = (1..10).into_iter().filter(|x| *x % 2 == 0).map(|x| x.to_string()).collect();Ну может быть после мапа вы еще какой-то адаптер хотите дальше использовать, и всякий раз аллоцировать список после вызова адаптера — слишком накладно.
Нужно понимать, что ленивый список в хаскелле это одновременно и вектор, и итератор в терминах раста. Естественно он не аллоцирует после каждого вызова комбинатора. Собственно это очевидно, ведь есть бесконечные списки вроде [1..], которые должны кушать бесконечное количество памяти (но они этого не делают).
Да и не понятно, коллекцию какого именно типа вы хотите получить на выходе, а может и просто некоторое единичное значение
Для получение единичного значения и в хаскелле и в расте используют фолд.
Речь шла о другом, а именно о несохранении монадических правил в целях оптимизации цепочки итераторов.
Так ведь? С одной стороны да. А с другой именно вторая программа в отличие от первой является функциональной.
Как это? Там есть *= которая не является ссылочно-прозрачной. Функционально чистой была бы программа, которая только бы вызывала эту функцию, но не состояла из ее определения. Например, если бы это была чистая программа эксплуатирующая грязный рантайм с чистым интерфейсом.
Это всё еще ссылочно прозрачная программа. Несмотря на изменение локального стейта.
В качестве ориентира можно посмотреть на язык D, где есть ключевое слово pure. Если мне не изменяет память, в примере его использования они как раз и используют факториал (или фибоначчи) с изменяемым локальным стейтом. Как я говорил, для ФП программы иметь локальный мутируемый стейт это нормально. Редко когда нужно, но — нормально.
что такое "локальный мутируемый стейт"? До какой степени локальный?
*= совершенно аналогичен функции
void MultuiplyBy(ref int accumulator, int multiplier)
{
accumulator *= multiplier
}
acumulator не является локальным состоянием для функции MultuiplyBy но может являться локальным для какого-то скопа сверху.
Мы не можем мемоизировать, авторматически пареллелить и т.д — т.е. не соблюдаются свойства которыми мы сможем воспользоваться для чисто функциональной программы.
Нам не важно пишем ли мы чистые функции или нет, важно пользуемся ли мы только ими или нет.
С моей точки зрения функция, которую вы написали, является чистой, а программа — нет.
Это ограничения уже самого сишарпа. По-хорошему оно должно работать с STRef и ничего не модифицировать.
Но сишарп так не умеет, поэтому приходится заворачивать вызов нечистых функций в одну чистую. Так же, как раст позволяет писать safe метод, вызывая внутри unsafe функции. Это немного идет вразрез с формальным определением, но на практике в данном случае не особо мешает.
Итого у нас есть чистая функция с нечистым телом. Ни одного вызова чистой функции в программе нет. Считается ли вся программа чистой в данном случае?
на практике в данном случае не особо мешает
В данном случае оно не мешает постольку поскольку тело маленькое. Так же как и чистота функции никому не помогает, поскольку ее вызовов нет. Но формально программу нельзя назвать чистой, поскольку она определена не только через чистые функции.
Итого у нас есть чистая функция с нечистым телом. Ни одного вызова чистой функции в программе нет. Считается ли вся программа чистой в данном случае?
С точки зрения D — является. С точки зрения практических свойств программы — тоже, ведь функция ссылочно прозрачная, а значит что она делает внутри нам всё равно.
В данном случае оно не мешает постольку поскольку тело маленькое. Так же как и чистота функции никому не помогает, поскольку ее вызовов нет. Но формально программу нельзя назвать чистой, поскольку она определена не только через чистые функции.
В данном случае наша программа состоит из единственной функции, которая является чистой. Что внутри тела, неважно, до тех пор, пока она ссылочно прозрачна.
С точки зрения D — является
Там определение чистой функции а не чистой программы.
У нас есть ваше определение
Функциональная программа — программа, состоящая из чистых функций.
По которому не понятно, что значит "состоящей из" и вот например из википедии
In computer science, purely functional programming usually designates a programming paradigm—a style of building the structure and elements of computer programs—that treats all computation as the evaluation of mathematical functions. Purely functional programming may also be defined by forbidding changing-state and mutable data.
Purely functional programming consists in ensuring that functions, inside the functional paradigm, will only depend on their arguments, regardless of any global or local state.
Если под "состоящей из" понимать что там должны быть только определения чистых функций, то непонятно, как им пользоваться. Программа может состоять из одной гигантской чистой функции реализация которой написана императивно и с ее логикой нельзя будет обращаться как композицией чистых функций — распараллеливать автоматически и так далее.
Что внутри тела, неважно, до тех пор, пока она ссылочно прозрачна.
Неважно для того, кто вызывает эту функцию, или для программиста который пишет/меняет ее тело?
Там определение чистой функции а не чистой программы.
Ну так в нашем случае программа состоит из этой единственной функции. значит все (одна) функции — чистые.
Если под "состоящей из" понимать что там должны быть только определения чистых функций, то непонятно, как им пользоваться. Программа может состоять из одной гигантской чистой функции реализация которой написана императивно и с ее логикой нельзя будет обращаться как композицией чистых функций — распараллеливать автоматически и так далее.
С нашим факториалом можно обращаться — распараллеливать рассчеты разных факториалов и вот это все. Распараллелить внутри из-за того как она написана — да, не получится.
Это была иллюстрация, что так можно делать. Но я нигде не говорю, что так делать нужно :)
Неважно для того, кто вызывает эту функцию, или для программиста который пишет/меняет ее тело?
Для того — кто вызывает. Внутри — важно, потому что мы работаем в контексте ST монады (пусть и неявно для мейнстрим-языков, которые не позволяют вынести этот факт на уровень типов), а значит у нас есть некоторые ограничения.
С нашим факториалом можно обращаться — распараллеливать рассчеты разных факториалов и вот это все.
Это иллюстрация того, что можно сделать с чистой функцией. А что можно сделать с чистой программой, что нельзя сделать с нечистой?
Есть ли у вас какой-то термин для программы, которая состоит только из вызовов чистых функций?
Там про то, почему функция чистая, а не почему программа чисто функциональна. С первым пунктом у меня та же точка зрения, а со вторым нет.
Если принять ее за черный ящик
В программе нет никого, кто использует функцию (т.е. принимает за черный ящик), а, наоборот, есть определение и реализация. Реализация определена не только через чистые функции, => программа не является чисто функциональной, хотя функция является.
Возможно, какая-то другая программа, которая бы вызывала эту функцию была бы чисто функциональной.
На самом деле из этой сигнатуры
fn foo<T>(a: &[T], b: T) -> T { ...какое-то тело... }Можно даже сделать более интересный вывод: эта функция всегда возвращает b просто потому что
- сама функция возращает значение типа T (не ссылку);
- ничего не известно про тип T (в том числе и о том, что его можно копировать/клонировать) + как указано в статье, сконструировать его нельзя по той же прчине;
- только аргумент b передается по значению.
То есть функция не сможет вернуть что-либо, содержащееся в a (так как передан по немутабельной ссылке), и не сможет сконструировать сама значение типа T. Остается b.
Отлично :) Вы нашли пасхалку!
На самом деле ваше замечание совершенно верно. Функция всегда может вернуть только b из-за того как работают правила владения в расте.
"Честная" функция которая может вернуть любое значение должна была бы выглядеть так:
fn foo<'s, T>(a: &'s [T], b: &'s T) -> &'s T { ...какое-то тело... }Которую я заменил на более простую, но не до конца корректную сигнатуру. Надеюсь читателя простят мне такую вольность, мне показалось что это усложнит текст статьи без какой-то особой ценности.
Еще про сигнатуры и возвращаемые значения:
Справедливости ради, стоит сказать, что в C# если автор функции с опытом, то он не будет просто возвращать default(T). Он либо затребует new констрейнт на T, либо попросит через параметр/иньекцию фабрику для T, либо будет возвращать некий Result(ну или nullable reference type, когда C# 8 станет попопулярнее). Жаль конечно, что нельзя это заэнфорсить, но в большинстве случаев это так.
По поводу метода, что берёт на вход строку, а возвращает T, сразу же в голове вот это всплыло — JsonConvert.DeserializeObject(string value);
https://www.newtonsoft.com/json/help/html/M_Newtonsoft_Json_JsonConvert_DeserializeObject__1.htm
По поводу метода, что берёт на вход строку, а возвращает T, сразу же в голове вот это всплыло — JsonConvert.DeserializeObject(string value);В Rust опять же это было бы видно из сигнатуры, так как T в этом случае должен реализовывать Deserialize
Десериализатор все же должен иметь возможность создавать объект указанного типа. Но когда у вас просто T, то создать его экземпляр невозможно: нет ни методов, ни информации о его внутренностях.
До сих пор мучают следующие вопросы, не могли бы помочь разобраться:
1. Как должен выглядеть следующий код в функциональной парадигме:
public class Car
{
public Car(string name, int power)
{
Name = name;
Power = power;
}
public string Name { get; }
public int Power { get; private set;}
void Add(Turbo turbo)
{
Power += torbo.Power;
}
}
public class Turbo
{
public Turbo(int power)
{
Power = power;
}
public int Power { get;}
}
Метод Add должен возвращать новый объект Car?
Car Add(Turbo turbo)
{
return new Car(this.Name, this.Power + turbo.Power);
}
Если да, то есть вероятность, что программист возьмет старый объект класса, забыл про новый из результата выполнения метода:
var car = new Car("name", 100);
var turbo = new Turbo(50);
car.Add(turbo);
return car;
Аналогичный пример с корзиной, в которую добавляют новые позиции. Корзина должна каждый раз пересоздаваться с новым списком?
Вопрос номер два:
Означает ли использование ФП частичный отказ от использования паттерна Состояние (State)?
в условном хаскеле будет примерно так:
car = mkCar "name" 100
turbo = mkTurbo 50
add car turbo
слово return тут не нужно, результатом вычисления будет равен результатом вычисления последней строки, забыть не получится
- Чтобы реализовать шаблоны State и Strategy не нужно ничего, кроме чистых функций
Иммутабельность не про это, а про то, что объект X всегда остаётся неизменным с момента создания. И если, например, X был передан в поток A, то он никак не изменится, что бы не происходило в потоке B.
С корзиной да, всё так же. Единственное, что, конечно, есть разумные оптимизации компилятора. Например, нет смысла повторно выделять память, чтобы хранить копию тех же самых данных — можно просто сослаться на данные старого объекта, если они те же. Иммутабельность позволяет делать это без опасений. Ну, и разумеется сборщик мусора.
Отвечая на второй вопрос. Если брать классические паттерны из «банды четырёх», то в мире ФП они все немного теряют в своей ценности и перестают быть каким-то артефактом правильной разработки, которые необходимо знать от и до. Какие-то реализуются элементарно просто за счёт полиморфизма/функций высшего порядка/частичного применения. Какие-то целиком укладываются в возможности монад. Какие-то просто теряют смысл в парадигме ФП. При этом более высокоуровневые паттерны («архитектурные», типа MVC и т.д.) остаются вполне актуальными.
напомню, что мы ничего не знаем про переданные объекты, поэтому паниковать только в некоторых случаях функция не может
Ну а например, функция, которая возвращает средний элемент и паникует, если массив имеет четную длину. Ну или любая другая, для которой подходят только определенные длины массива.
В принципе верно. Но, хотя и маловероятно, вполне возможно. Т.к. нам частично известен тип одного из аргументов (это массив), мы и можем делать всякую дичь (хотя скорее всего не делаем).
Это оптимистичный взгляд на вещи :) один из минимум двух возможных…
Это реалистичный взгляд)
Я исхожу из того, что программисты неглупые люди. Ленивые, забывчивые, часто опечатывающиеся, но не глупые.
А такую функцию можно написать только специально, из вредности, из разряда
#define TRUE FALSE // счастливой отладкиЭто возможно, но я предпочту более вероятную гипотезу. И даже в худшем случае ничего страшного не произойдет и я останусь с тем с чем был изначально.
Ну не, не обязательно. Можно просто из непонимания. Либо постановки задачи, либо имеющегося решения, либо чего-то еще. Ну то есть, неглупые — но ограниченно неглупые, не всегда способные учесть все побочные эффекты.
Например, вы передадите свой массив еще куда-то, в другой кусок кода, а автор того куска вообще ни сном ни духом не думал про такое использование своего куска. Или наоборот (как обычно и бывает, кстати) — взять работающий кусок кода, и перенести его в другое окружение. От чего ФП как раз отлично спасает. Впрочем, об этом уже тут несколько раз написали.
Намучившись с удержанием в голове каркаса приложения в ООП стиле, понял что дальше так не может продолжаться. В итоге за вечер набросал вариант «без классов» — есть состояние с описанием действий и рантайм который их исполняет. Так как не был знаком с ФП и чистыми функциями, то закрадывалось подозрение что делаю что-то не так. Зато теперь все стало на свои места. Спасибо за доступное изложение и примеры!
Хотя люди обычно признают удобства ФП фич, ведь намного приятнее писать..
Уже в первом примере идет какая-то вкусовщина. С таким подходом можно что угодно оправдать: «Хотя люди любят пиво, но ведь намного приятнее выпить водки..»
ФП это не набор соглашений, требований и ограничений. ФП не накладывает никаких требований на неизменяемость, чистоту и прочее.
ФП это набор согласованных правил.
Просто это правила отличаются от императивных (а не от ООП). ООП это вообще игра на другом поле. ФП можно сравнивать с императивной парадигмой, но не с ООП.
Что касается приведённого примера, то в ней, например, result *= i; является операцией, которая в ФП отсутствует.
Можно как угодно себя уговаривать, что это программа в стиле ФП, но она такой не станет. Нельзя в середине уравнения сократить на 0 и получить верный результат. Даже если он очень похож на верный.
Что касается приведённого примера, то в ней, например, result *= i; является операцией, которая в ФП отсутствует.
Но ведь это неправда. Надеюсь, вы не заподозрите, что хаскель разрешает нечистый код? Но вот программа на нем, которая мутирует локальную переменную result на каждой итерации цикла.
factorialST :: Int -> Int
factorialST n = runST $ do
result <- newSTRef 1 // инициализируем начальное значение 1
forM_ [2..n] $ \x -> do // для каждого значения 2..n
modifySTRef result (*x) // мутируем наш result, домножая его на x
readSTRef result // читаем результат из ячейки памяти resultВот ссылка на плейграунд, если мне не доверяете: https://repl.it/@Pzixel/PeruFantasticCosmos
Ну и если остались какие-то сомнения:
What is the difference betweenforMandforM_in haskell? TheforM_function is more efficient because it does not save the results of the operations. That is all. (This only makes sense when working with monads because a pure function of typea -> ()is not particularly useful.)
То есть forM_ это простой цикл, он не сохраняет никаких результатов.
Так тут же монада. Тут нет локальной переменной. Всё это классически разворачивается передачу следующего значения в следующую функцию. Монада (монады) предлагают правила разворачивания.
И да, хаскель конечно разрешает "нечистый код" с помощью unsafe.
Всё это от того, что в ФП отсутствует понятие потока выполнения, а есть только правила преобразования которые undecidable. Поэтому надо в ФП прийти "снаружи" и навести порядок железной рукой. Что и делают все эти наши компиляторы.
Ну result выглядит и ведет себя именно как локальная переменная. В которую мы пишем, и которую затем читаем. А если что-то выглядит как утка и плавает как утка… Ну вы поняли.
Понятно, что в конце концов оно там развернется, а потом опять свернется (потому что интерпретируем мы на вполне себе императивном ЦПУ), но это всё уже не важно. Код практически 1 в 1 повторяет то что написанно на сишарпе. То что тут есть явная ст монада, а в сишарпе нужно за этим руками следить — ну тут уж извините, не завезли туда такого.
Да нет же. Хоть оно и выглядит как утка, но не крякает, как утка. Хотя бы потому, что хаскельный кусок кода я могу "взять с собой" по программе, а императивный нет.
В том смысле, что modifySTRef result (*x) это обычное применение функции, которое в нотации do выглядит, как утка. Но его не обязательно так применять.
Ввиду отсутствия потока выполнения, хаскельный чётко определяет вход-выход функции и зависимости. У императивного подхода такой "свободы" нет — для того, чтобы понять результат print(i++, ++i++) в императивном языке нужно заглянуть в спецификацию и молится, чтобы там не было написано undefined behaviour, а в функциональном в код монады, а там никакого undefined.
ps: Конечно, прямого i++ в функциональных нет, это просто яркий пример кода модифицирующего переменную. При желании пример заменяется на modifySTRef.
Что вы понимаете под "взять с собой"?
Присвоить переменной это действие и вызывать по необходимости.
Ну так и для result *= i так тоже можно сделать, просто кода будет больше.
В общем случае нет. Ну или много будет плясок и мы придумаем монады и замыкания.
Вот как есть result *= i нельзя присвоить переменной и звать по необходимости.
Та же ява требует переменные effectivelly final для засовывания в замыкание.
А после того, как мы вооружимся ФП и таки сделаем правильное замыкание в императивном языке нужно будет придумать правила их композиции. Стрелки, монады, вот это всё.
А те же C# и Kotlin этого от переменных не требуют
Я не большой специалист в котлин и c#, интересно посмотреть, что они делают с переменными на стеке. В принципе, scheme тоже этого не требует, я больших сюрпризов здесь не ожидаю.
Мой основной поинт в том, что modifySTRef не модифицирует переменную в замыкании.
Если мы поместим result = i в замыкание и позовём это замыкание три раза, то получим result=resulti*3.
Если мы позовём modifySTRef три раза, то всё зависит от нашей композиции. Обычая do нотация тоже построит цепочку вызовов, а другая монада легко может свести всё к одному вычислению. Вопрос в управляемой композиции.
Поэтому монады в целом и do-нотация в частности это не про нечистый код в хаскеле, это про композицию.
Подозреваю они на стеке такие переменные и не хранят. Либо делают как в D — в момент выхода замыкания из скоупа, переносят стек фрейм в кучу.
Я не большой специалист в котлин и c#, интересно посмотреть, что они делают с переменными на стеке.
Ничего особенного — копируют их в учу. Поэтому и возможны любопытные эффекты:
var lambdas = new List<Action>();
for (int i = 0; i < 5; i++)
{
lambdas.Add (() => Console.Write(i));
}
foreach (var lambda in lambdas)
{
lambda();
}Выведет 55555.
Поэтому монады в целом и do-нотация в частности это не про нечистый код в хаскеле, это про композицию.
Я скорее про то, что оно пишется и ощущается как нечистый императивный код. То, что оно задешугарится в безопасные бинды — это как раз желаемое поведение, иначе мы бы нарушили гарантии.
Но в том же D рантайм не такой умный, поэтому там есть компилятор, который следит что вы мутируете только локальные переменные. И они получаются вполне себе чистыми. Вот ссылка на документацию.
Важный и совсем неочевидный вопрос: возвращаемый функцией finder делегат использует значение x, а где находится x после того, как finder вернет управление? На самом деле, в этом вопросе слышится серьезное опасение за происходящее (ведь D использует для вызова функций обычный стек вызовов): инициатор вызова вызывает функцию finder, x отправляется на вершину стека вызовов, функция finder возвращает результат, стек восстанавливает свое состояние до вызова finder… а значит, возвращенный функцией finder делегат использует для доступа адрес в стеке, по которому уже нет нужного значения! «Продолжительность жизни» локального окружения (в нашем случае окружение состоит только из x, но оно может быть сколь угодно большим) — это классическая проблема реализации замыканий, и каждый язык, поддерживающий замыкания, должен ее как-то решать. В языке D применяется следующий подход. В общем случае все вызовы используют обычный стек. А обнаружив замыкание, компилятор автоматически копирует используемый контекст в кучу и устанавливает связь между делегатом и областью памяти в куче, позволяя ему использовать расположенные в ней данные. Выделенная в куче память подлежит сбору мусора. Недостаток такого подхода в том, что каждый вызов finder порождает новое требование выделить память. Тем не менее замыкания очень выразительны и позволяют применить многие интересные парадигмы программирования, поэтому в большинстве случаев затраты более чем оправданны.
Ничего особенного — копируют их в учу. Поэтому и возможны любопытные эффекты:
Ага, ну вот примерно я об этом и говорю.
Примерно такой же алгоритм в схеме ведёт себя более предсказуемо (ну, или привычно, смотря кто читает код :)
(define ilist (let loop ((i 0) (i-clos '()))
(if (= i 4)
i-clos
(loop (+ i 1) (append i-clos (list (lambda () (display i))))))))
(for-each (lambda (clos)
(clos))
ilist)выведет 01234
Я скорее про то, что оно пишется и ощущается как нечистый императивный код. То, что оно задешугарится в безопасные бинды — это как раз желаемое поведение, иначе мы бы нарушили гарантии.
Может оно так и выглядит, но устроено совсем по другому, несёт другие гарантии и вообще, это ДРУГОЕ. Просто ФП это другое программирование, это не императивное с ограничениями, а другое.
Если пытаться на него смотреть с императивной колокольни, то всё будет казаться кривым, недоделанным и ограниченным. Лучше, мне кажется, понять, что лежит в его соно
То, что оно задешугарится в безопасные бинды — это как раз желаемое поведение, иначе мы бы нарушили гарантии.
Так оно дешугарится ровно в те же бинды, в которые может дешугариться код на c# с ровно теми же самыми гарантиями безопасности. С формально-математической точки зрения код в ио невозможно отличить от обычного императивного кода в обычном императивном ЯП.
Мне вполне удается писать вполне себе ФП код на JS/TS, и я может и не против пересесть на PureScript, вот только я с ним не расширю свою команду…
Конечно, ФП это не серебряная пуля, у него есть свои ограниченияРанее написал про интересное ограничение ФП классической задачи — Решето Эратосфена (РЭ):
В обсуждении статьи по функциональному программированию (ФП) задал вопрос: как в этой парадигме написать РЭ. Обладая более чем скудными знаниями по ФП, не берусь судить об ответах, но другие участники обсуждения забраковали некоторые из предложенных сходу решений, указав, что вместо теоретической сложностиМ.б. тут спецы в ФП снимут это ограничение и предложат быстрое решение РЭ в ФП? Заранее спасибо!
[...]
предложенная реализация будет обладать [худшей] вычислительной сложностью
[...]
и что с такой сложностью не дождаться, когда, например, просеются 10 миллионов чисел.
Ссылочная прозрачность — свойство, при котором замена выражения на вычисленный результат этого выражения не изменяет желаемых свойств программы
Очень познавательно!
С точки зрения самой сути ФП — да, это всё. Отсутствие эффектов это единственное требование, которое нужно соблюдать, чтобы программа была функциональной.
Ноуп. Отсутствие эффектов не является ни достаточным, ни, что самое интересное, необходимым свойством ФП. Ф-и в стейт-монаде (ну и ИО как следствие) семантически грязные, но их использование ФП не "ломает".
ФП от императивщины отличается средствами (де)композиции. Например, когда ты в do-нотации что-то пишешь — это чистая императивщина, со всеми вытекающими (ссылочная прозрачность есть, но при этом код ведет себя в плане ризонинга ровно так, как если бы ее не было).
В результате из-за побочного эффекта код трудно тестировать.
Этот код трудно тестировать потому, что его корректность тривиальна. Там тестировать нечего, т.к. любой тест этого кода будет тестом компилятора.
Тогда наша функция будет иметь вид:
И она точно так же тривиальна и ее нельзя протестировать. К счастью, мы можем заменить прямые вызовы конструкторов Charge/Cofee на соответствующие фабрики (ну никто же в здравом уме не будет создавать счет не через абстрактную фабрику, правда ведь? ;)) и замокать их. И написать тест с моками.
А вот если это тест, то он просто может проверить возвращенный объект Charge на все интересующие его свойства.
И теперь у нас будет другая задача — проверить, что некий другой элемент системы, когда получает объект, созданный конкретной фабрикой платежей, корректно их обрабатывает. Ситуацию с нулем чашек, в частности.
И она точно так же тривиальна и ее нельзя протестировать. К счастью, мы можем заменить прямые вызовы конструкторов Charge/Cofee на соответствующие фабрики
А в чём трудность в её тестировании и в чём смысл создавать Value Object через фабрику?
Ноуп. Отсутствие эффектов не является ни достаточным, ни, что самое интересное, необходимым свойством ФП. Ф-и в стейт-монаде (ну и ИО как следствие) семантически грязные, но их использование ФП не "ломает".
В ФП нет эффектов, а "ду монада" это просто сахар для пачки биндов. А то что a.bind(b) и b.bind(a) не всегда эквивалентны вроде должно быть очевидно.
Этот код трудно тестировать потому, что его корректность тривиальна. Там тестировать нечего, т.к. любой тест этого кода будет тестом компилятора.
Проверить что покупка 10 чашек кофе возвращает суммарный чек в 10 раз больше чем покупка одной чашечки — это проверка компилятора?
И она точно так же тривиальна и ее нельзя протестировать. К счастью, мы можем заменить прямые вызовы конструкторов Charge/Cofee на соответствующие фабрики (ну никто же в здравом уме не будет создавать счет не через абстрактную фабрику, правда ведь? ;)) и замокать их. И написать тест с моками.
Ага, если написать фабрику через фабричный вызов еще одной фабрики, то все проблемы сами собой решаться. Нет, я не буду использовать фабрику пока мне это не надо. Со случаями, когда её лучше использовать, можно ознакомиться у gof'а или фаулера.
И теперь у нас будет другая задача — проверить, что некий другой элемент системы, когда получает объект, созданный конкретной фабрикой платежей, корректно их обрабатывает. Ситуацию с нулем чашек, в частности.
Да, но у нас в системе скорее всего есть сотни мест, которые выставляют чеки на те или иные действия, а реально списывает их один "списывальщик". Упростить эти сотни мест — вполне ценная вещь.
В конце два класса нечитаемой каки с лямбдами, которые если сломаются, то починить может только автор, которые делают хрен знает что и ради чего и блин слезы-слезы-слезы. Тут же надо было просто вернуть кофе и списать сто рублей, зачем вся эта гора кода?
Отрубать руки по локоть и не подпускать к компу таких.
Отрубать руки по локоть и не подпускать к компу таких
Программирование уже давно перестало быть чем-то специфическим. Как раз благодаря смелым и нестандартным решениям мы имеем полную свободу в кодинге. Ограничения только в голове. Если мы не согласны с чем-то это просто субьективное мнение. Зачем же так радикально?
А так мне сказали: сейчас я научу вас забивать гвоздь в доску, для это нужно семь датасаентистов, протонный ускоритель, пластинка из чистого урана, эталон килограмма из палаты мер и весов и полтора месяца времени. А я могу сделать это только молотком секунд за 30. Придумай и приведи пример, где это может быть полезно!
Нужно приводить наглядный пример, где твой метод от чего-то спасает, делает что-то наглядней и проще, а не наоборот: из трех строчек безбажного кода, получает две страницы забагованного.
Тут же наоборот: было хорошо -> стало плохо. Придумайте сами, где юзать хрень, у меня не получилось
Если вы не видите где можно применить подход, описаный автором, значит вам это не требуется. Мы же не пьем таблетки от простуды когда здоровы. Но есть заболевшие люди, которые в них нуждаются, а вы, оставаясь в полном здравии, сетуете на горькоту этих таблеток.
Я надеюсь что понятно изложил суть ваших необоснованых замечаний.
Ну вы точнее описывайте)) Сюжет статьи такой: «У меня был кашель, я поел заячьего помета, теперь у меня понос. Юзайте.» И тут вы: Эгей! Статья ништяк, потому что я давно хотел пролечить свой запор.
У автора тоже нет простуды, но горьких таблеток он наелся.
Ну вот вам "идеальный код" для второго случая:
public (Coffee[], Charge) BuyCoffees(int count, CreditCard card)
{
Coffee[] coffees = new Coffee[count];
Charge totalCharge = Charge.Empty(card);
for (int i = 0; i < coffees.Length; i++) {
var (cup, charge) = BuyCoffee();
coffees[i] = cup;
totalCharge = totalCharge.Combine(charge);
}
return (coffees, totalCharge)
}Так вам стало понятнее, что происходит?
А к комбинаторам лучше привыкать, потому что когда в прошлом году мне пришлось с нормальных ЯП переключиться на солидити (нужно было проектик под эфириум сделать), где кроме циклов нифига нет, я и ошибку где i вместо j использовал сделал, и ошибки на единицу, и выход за границы массива, или где я фигурную скобку закрыл не там, и в результате инкрементировал счётчик всегда (а нужно было по условию), ну и всё остальное. Хотя, казалось бы, не дурак, и какой-то опыт в разработке имею. А оно вон как.
Может быть потому что в императивном мире тоже могут сначала налить кофе, а только лишь потом убедиться в том, что клиент неплатежеспособен? :-)
Ну очень просто ведь: налили кофе, выставили за него счет. Посмотрели, хватает ли средств на списание. Если хватает, списали деньги и отдали кофе, иначе выкинули кофе и клиенту его не отдали.
Всё, что вы перечислили, делается снаружи этого кода.
Вот мы вызвали код, у нас есть Coffee[] и Charge. Теперь можно:
- заблокировать ту сумму, что записана в Charge
- налить кофе, которое записано в Coffee[]
- подтвердить транзакцию.
При этом, вынесение этих операций из BuyCoffee наружу позволило переиспользовать этот код для покупки нескольких чашек кофе в одной транзакции (та самая архитектурная выгода, которую не увидел dididididi).
Про чистые вычисления тоже можно потом песнь затянуть с распаралеливанием на 10К процессоров, графических сопроцессоров и прочих ASIC.
Смысл в этом есть, называется "бизнес-логика".
А вы говорите чистые функции :)
Открыл один из репозиториев моей текущей работы, посмотрел в бизнес-логику, не нашел там хаков и костылей.
Наверное, стоит бороться со стереотипом, что работающий код — это исключительно дырявое полотное из заплаток, слепленное на ходу непойми кем?
Вот как раз по-этому весьма важно как язык и среда (они теперь неотделимы!) заставляет писать просто, поддерживает рефакторинг и насколько он гибок к изменениям. За это C# и люблю. Это нифига не гарантия, что он не устареет со временем, но по крайней мере пока, все кругло.
А откуда вы узнаете, сколько денег за счёт надо выставить не разливая чашек? Ведь если вы вспомните, то цена чашки определяется через cup.Price. Вам нужно иметь уже налитую чашку кофе чтобы посчитать, сколько она стоит.
Возможно нам это не нравится и мы хотим, чтобы чашки можно наливать уже после того, как мы проверили, что денег хватает, но это немного другой дизайн и выходит за рамки статьи.
Коллега, видимо, будет плодить сущности. Типа FutureCupOfCoffee, которая представляет намерение о покупке чашки кофе. CupOfCofee — сама чашка кофе. Charge — класс объекта списания денег. И в результате простая, казалось бы задача, приводит к эволюционному взрыву и появлению целой вселенной классов )
Касательно дизайна: да, есть два сценария. Сначала платим — потом получаем кофе (кафешки с барной стойкой, автозаправки и пр.) И обратный сценарий — сначала заказываем кофе в Н чашек, пьем и только потом оплачиваем (как в ресторанах с официантом). И обязательно — оставить возможность переключения логики с первой на вторую. У нас же эджайл и гибкая внешняя среда )))
Я про такой дизайн и подумал, как, наверное, и любой человек читающий эту ветку. Правда я представлял это как CoffeeOrder или CoffeeTicket.
Никакой комбинаторики особо взрывающейся тут нет, просто как я уже сказал, это немного другой дизайн. У него есть свои плюсы, но и свои минусы. Просто я решил не обсуждать его, потому что и так дофига написали уже)
… или негарантированном порядке вычислений
и тут, внезапно, на сцене появляется ее величество ассоциативность.
Попробуйте сделать пример чистой функции по расчету НДФЛ по одному сотруднику (на входе id сотрудника и дата на которую нужно сделать расчет, на выходе сумма).
Каждый инструмент нужен в своем месте, где то удобней функциями особенно в математике, где то в ООП, где то процедурное программирование. Главное не впадать в крайности и уметь выбрать самый правильный инструмент, ну или хотя бы наиболее подходящий в данном конкретном случае.
Попробуйте сделать пример чистой функции по расчету НДФЛ по одному сотруднику (на входе id сотрудника и дата на которую нужно сделать расчет, на выходе сумма).
Давайте. Кто напишет? Интересный бизнес-пример. При этом сигнатура ф-ции будет вполне ясная (или нет — если учесть, что могут быть невалидные входные параметры — типа несуществующий сотрудник или сотрудник в ту дату не работал или еще не был принят на работу/уже уволен).
Тут гадание о работе функции по сигнатуре и на простом примере уже несколько постов о том как там в ней внутри все должно быть устроено, а Вася возьмет и сделает внутри этой функции по другому, а не так как вы по сигнатуре гадаете и все равно придется в нее лезть и изучать как она там работает и пока что мне кажется что в обычном коде разобраться легче (может быть привык х.з.).
Так не получится же.
Я же и говорю, про силу языков. Если у вас сигнатура функции T -> T, то у вас есть три варианта как её написать:
- вернуть переданный аргумент
fn foo<T>(x: T) -> T { x } - войти в вечный цикл
fn foo<T>(x: T) -> T { foo (x) } - завершить работу с паникой:
fn foo<T>(x: T) -> T { panic!("I won't work!") }
На этом перечень того что вы можете сделать не совершив UB нет. В ФП языке вы НЕ можете
- создать объект T локально
- считать его из внешнего источника
- сгенерировать его на ходу
- ...
Гадание на сигнатуре хорошо работает, если вам язык не позволяет творить дичи (как C#). Ну а если ваш язык этого не гарантирует, то вы такой методикой воспользоваться не можете, тут уж ничего не поделать. Хотя как и в плюсах, можно воспользоваться правилами хорошего тона. Работает, правда, не так надежно, как компилятор, так что лучше выбрать инструмент поудобнее.
Попробуйте сделать пример чистой функции по расчету НДФЛ по одному сотруднику (на входе id сотрудника и дата на которую нужно сделать расчет, на выходе сумма).
А какие тут сложности должны возникнуть? Вон, компиляторы на хаскеллях пишут, я не думаю, что они проще чем расчёт НДФЛ. Правда, ваш код надо будет завернуть в Reader монаду или еще какую, потому что айди сотрудника явно недостаточно, нужно в базу сходить и вот это всё, в остальном не вижу никаких проблем.
public class Cafe
{
public (Coffee, Charge) BuyCoffee(CreditCard card)
{
var cup = new Coffee()
return (cup, new Charge(card, cup.Price))
}
}
Это, конечно, изящный подход. Как быть с проверками? Допустим, перед тем, как выдавать кофе, нужно проверить его наличие. Можно выдавать запрос на «грязное действие» плюс функцию, которой передать результат «грязного запроса». Далее обработка будет происходить
по цепочке, пока результатом не будут одни «грязные запросы», которые может выполнять ядро.
Другой вариант — ядром реализовать «грязные действия» типа BuyCoffeeIfInStock… но как-то слишком много грязи выходит…
Я подумывал это дело применить, но пока не стал, слишком сложно получается, простая логика размазывается по многим функциям. Проще сделать mock к слою, который хранит состояние, и проверять изменения в состоянии после вызова функции.
Есть идеи, как это изящно сделать на чистых функциях?
Надо ли говорить, что инспектировать внутреннее состояние объектов — это нехорошо? И да, можно конечно использовать какой-нибудь фреймворк который сделает за нас большую часть работы, но не всю, да и тащить целый фреймворк просто чтобы протестировать что мы можем купить чашечку кофе выглядит оверкиллом.
Чашка кофе продается обычно в рамках чего-то большего, и вот для этого большего вполне себе оправдано «притащить фреймворк».
Вы просто не умете готовить этих кошек.
Кмк ошибка в том, что декомпозиция задачи осуществляется в импеоативной парадигме, а решение в функциональной, отсюда конфликт.
Это, конечно, изящный подход. Как быть с проверками? Допустим, перед тем, как выдавать кофе, нужно проверить его наличие. Можно выдавать запрос на «грязное действие» плюс функцию, которой передать результат «грязного запроса». Далее обработка будет происходить
по цепочке, пока результатом не будут одни «грязные запросы», которые может выполнять ядро.
Ну, в ФП принято вместо зависимостей отдавать результат вычисления этих зависимостей. Поэтому вы скорее всего сделаете еще один параметр bool shouldReturnCoffee. Правда, в таком простом случае проще вызывающему коду не вызывать эту функцию)
На дотнексте 2018 был хороший доклад от Марка Симана на тему как работает DI в функциональных языках. Очень рекомендую почитать: https://blog.ploeh.dk/2017/01/27/from-dependency-injection-to-dependency-rejection/
Есть идеи, как это изящно сделать на чистых функциях?
Монады :) Причем я серьезно, "монада" это как "паттерн" в ООП — решение всех частовстречаемых проблем. Например, есть монада которая позволяет таскать неявный контекст кроме явно переданных параметров, получается как конструктор в ООП (в который мы передали параметры чтобы в каждый метод отдельно их не совать), есть монада Writer которая кроме возврата результата позволяет делать какие-то еще действия, например, писать в лог. Но в отличие от нашего пример с Log.Info это всё контролируется вызывающим кодом и он может с этим что-то сделать (например, выкинуть накопленные логи). В императивном коде вы так сделать не сможете.
Чашка кофе продается обычно в рамках чего-то большего, и вот для этого большего вполне себе оправдано «притащить фреймворк».
Я сторонник делать абстракции по-необходимости. Если нас попросили написать консольную тулзу которая просто выдаёт чашечки кофе — то не надо ничего тащить. Когда мы стали единорогом, продались за миллиард и начали резко расти по фичам, тогда другое дело :)
А с другой именно вторая программа в отличие от первой является функциональной.
Только вот эти программы не эквивалентны (потому что первая пишет логи, а вторая нет). Если из первой убрать вызов Log (или наоборот, добавить во вторую), то они обе станут (не)функциональными.
Они нарочно нефункциональные, чтобы продемонстрировать что если у вас красивый флюент интерфейс с лямбдами и бесточечными функциями это не всегда значит что у вас хорошее ФП решение, а с другой стороны что в ФП вполне можно писать низкоуровневые вещи и мутировать локальные переменные, оставаясь при этом в рамках парадигмы.
Да, первое знакомство и базовые вещи на уровне содержимого книжки «Learn You a Haskell for Great Good» оставляет исключительно положительные впечатления.
Но потом ты пишешь первую неучебную программу и ловишь segfault от сжирания всей памяти, пытаясь обработать какой-нибудь файлик в 500 Мб. Понимаешь всю цену «ленивости» языка, и что хоть Haskell по умолчанию ленивый, но программы рекомендуется писать по умолчанию строгими. Читаешь про BangPattern'ы, deepseq, разницу между Lazy и Strict (а потом value-strict и spine-strict) версиями структур данных, про unboxed типы — во многих книгах этого просто нет.
Затем смотришь на то, как применяют Haskell для реальных больших приложений, а не просто «типа скриптов» — например, в веб-фреймворках. Открываешь описание работы Servant'а и понимаешь, что все те описания монад, трансформеров и прочих typeclass'ов в книжках было лишь самой вершиной айсберга и тебе не рассказали про 101 pragm'у языка, каждая из которых добавляет новые возможности языка, поверх которых строится функционал каждого второго реального приложения на Haskell. И эти прагмы неожиданно сложные — даже не в плане того, как они реализованы, а в плане того, что они тебе дают. Например, попробовать сразу после LYHS разобраться в содержимом статьи wiki.haskell.org/GHC.Generics — гиблое дело.
И тут становится очевидной главная, имхо, проблема Haskell'а — очень большой gap между книжками и реальным production-использованием. И это на фоне действительно большей сложности языка по сравнению с другими мейнстримными. Если взять сферический rails, то после 1-2 книжек ты сможешь без особых сложностей освоить RoR на отличном уровне и быстро разбираться в новых возможностях, пролистывая доку/исходник. А с Haskell это не так. Радует только то, что эта сложность абсолютно логична и объяснима, чего иногда нет в других языках. В Haskell действительно очень многие вещи делаются абсолютно иначе, чем в привычных императивных языках и здесь совсем другая, более фундаментальная и вместе с тем очень утилитарная роль типов.
Однако, что точно является фактом, это то что haskell навсегда меняет стиль программирование в Java например
Условно — замените у себя «файлик 500Мб» на 10Tb, и у вас будут проблемы в любой парадигме при любом подходе, если вы его изучили на уровне Learn You a Haskell for Great Good, и там остановились.
Хотелось бы узнать побольше про разделение «чистого кода» и «грязного рантайма»: как они связываются, как выглядят описания DB или HTTP -запросов, что в такой архитектуре происходит с DI.
Материала, как мне кажется, на ещё одну статью, был бы очень рад прочитать
Спасибо, я старался!
По поводу DI я чуть выше дал ссылку на прекрасную статью, там это хорошо расписано.
В первом примере есть вывод в лог (условный print из последнего примера), и мы считаем, что программа написана не в стиле ФП, потому что если заменить Factorial(5) на 120, у нас перестанет выводиться в лог сообщение.
Собственно вопрос в — а чем бы отличалось поведение программы, если вместо вывода в лог была бы функция с print (как в haskell из последнего примера) и грязный интерпретатор?
Мне кажется замени мы в этом случае вызов функции факториала на ее значение, мы все еще потеряли бы вывод в лог/консоль сообщения.
Добрый день, отличный вопрос.
В случае с хаскеллем дело в том, что программа с сигнатурой Int -> Int не может ничего распечатать. Даже если мы попробуем это написать:
factorial :: Int -> Int
factorial n = do
let _ = print "Some log here"
foldl (*) 1 [1..n]
main = print $ factorial 5То запись в лог просто "не произойдет". Потому что, как я показывал выше, мы создали описатель действия выведения в лог, но интерпретатор его никак не может получить.
Чтобы интерпретатор до него добрался, нам надо его как-то вернуть. Но любой способ его вернуть не меняя сигнатуру функции приведет в ошибке компиляции. Поэтому нам ничего не остается, кроме как поменять сигнатуру функции, ну и немного подправить main потому что функция factorial стала монадической, поэтому её нельзя просто так вызывать. Получаем:
factorial :: Int -> IO Int
factorial n = do
_ <- print "Some log here"
pure $ foldl (*) 1 [1..n]
main = do
result <- factorial 5
print resultРаботает это как асинхронность в популярных языках (которая впрочем, по сутя является частным случаем как раз IO монады) — если вы переписали синхронную функцию в асинхронную то у вас этот async "заражает" весь коллстек до самого верха. Так и тут
На сишарпе эквивалент будет примерно такой:
class Program
{
static int Factorial(int n)
{
var _ = new Task(() => Console.WriteLine("Some log here"))
// в языке нет (), поэтому приходится обходиться так
.ContinueWith(_ => default(object));
return Enumerable.Range(1, n).Aggregate((x, y) => x * y);
}
static async Task Main(string[] args)
{
Console.WriteLine(Factorial(5));
}
}и для второго варианта:
class Program
{
static async Task<int> Factorial(int n) // Task<T> это то же что IO T
{
var _ = await Task.Run(() => Console.WriteLine("Some log here"))
.ContinueWith(_ => default(object));
return Enumerable.Range(1, n).Aggregate((x, y) => x * y);
}
static async Task Main(string[] args)
{
var result = await Factorial(5); // вместо <- в сишарпе используется await
Console.WriteLine(result);
}
}1. Выходит, что пометка возвращаемого результата как IO, это синт. сахар, который скажет интерпретатору найти все IO операции в функции и выполнить их?
2. Правда тут еще возникает вопрос о порядке выполнения, т.к. при IO это может быть важно, но об этом насколько я понял заботится do.
3. В итоге если бы мы все же хотели заменить вызов функции ее результатом, то поскольку теперь тип возвращаемого значения не int, а IO int, мы, без нарушения этого контракта, не смогли бы просто заменить его на 120, но были бы вынуждены как и интерпретатор понять, какой именно IO эффект порождается функцией и добавить его как результат работы к значению 120? (в этом объяснении есть ощущение что я что-то упускаю или очень упрощаю, но по-другому свести все вместе как-то не получалось :))
Выходит, что пометка возвращаемого результата как IO, это синт. сахар, который скажет интерпретатору найти все IO операции в функции и выполнить их?
Нет, это работает в другую сторону. Любую IO-операцию можно скомбинировать с чем-то, и получить другую IO-операцию. А можно забыть. Если операция "дошла" до возврата из main — она выполнится. Забытые операции выполняться не будут.
Правда тут еще возникает вопрос о порядке выполнения, т.к. при IO это может быть важно, но об этом насколько я понял заботится do.
do — всего лишь синтаксический сахар для комбинирования операций. Они выполняются в том порядке, в котором комбинировались.
А третьего вашего вопроса я не понял.
- Пометка возвращаемого результата как IO это не сахар, а просто пометка. У каждой монады есть пара методов, которые интерпретатор выполняет когда до них доходит. В случае IO это какое-то ИО собственно, в случае стейт монады это сохранение стейта, в случае List-монады это применение действия в каждому элементу списка и т.п.
- нужно понимать, что как
async/awaitразворачивается в цепочкуContinueWith, так и вdo и <-всё разворачивается в такую же цепочкуbind, который по смыслу то же самое делают, только называется иначе. Ну иa.ContinueWith(b)это не то же самое чтоb.ContinueWith(a), поэтому в do-записе порядок важен. В каком запишете в таком цепочка и будет выполнена. Именно тут (и только тут) порядок может влиять на результат, поэтому только в do-блоках нужно быть аккуратнее при перестановке местами строчек. Но т.к. вам язык помогает их найти (вы явно видите блок) — то проблем с этим нет. - Мы спокойно можем поменять результат функции) Она же по сути возвращает структуру
IO(Print("Some log here"), 120). Можем подставить её тело в мейн:
main = do
result <- IO(Print("Some log here"), 120)
print resultповедение останется прежним. Функция занимается только созданием описателя, поэтому мы этот описатель можем руками инплейс создать. Ну и наоборот, можем описатель поменять на такую функцию, вызвать её, и все останется как было. Наши законы — соблюдены.
Какой именно эффект — это не компиляторная магия, она описанна в реализации самого типа IO. Интерпретатор просто запускает на выполнение методы, а там написано, куда какие байты записывать.
Разве у IO есть конструктор?
Ну в хаскелле он захачен на уровне компилятора, видимо (как-то ведь сам рантайм создает объекты этого типа?), но в тех же котах это обычный тип: https://typelevel.org/cats-effect/datatypes/io.html#pure-values--iopure--iounit
Но учитывая что конструкторы это просто функции создающие значения, то мы сами такую можем сделать:
makeIO action result = do
_ <- action
pure $ result
main = makeIO (print "Some logs here") 120 >>= print"В тех же котах" одновременно присутствует как монада IO, так и обычный императивный код, унаследованный ещё от Java, отсюда и возможность такого конструктора.
Но я не могу назвать это достоинством.
А я в свою очередь не могу назвать достоинством наличие "магических" типов, которые может создавать только рантайм.
Впрочем, хаскеллю 30 лет, думаю это можно списать на возраст. Все же за это время появилось лучшее понимание, что и как делать. Будем надеяться, что дотти и идрис2 будут расти и популяризироваться.
Эдак можно начать жаловаться на "магический" оператор сложения целых чисел, который может быть реализован только компилятором, но не вами.
Так я и жалуюсь. Это очень плохо. И хорошо, что в том же расте это просто трейт который честно реализован для типов.
Но это же бесконечная рекурсия, которая без "магии" со стороны компилятора никогда не разрешится:
fn add(self, other: $t) -> $t { self + other } Напомню, оператор + вызывает функцию add
А как он реализован уже не важно. Главное что я могу для своих типов реализовать такой же плюс, и он будет работать не хуже того что определен для стандартных типов.
Хотя если поинт был в том, что любая теория стартует с аксиом которые не доказываются, а постулируются, то тут возражений нет, без аксиом ничего полезного не сделать.
А потом внезапно выясняется, что мы находимся в корпсети. И мы не можем установить корневой сертификат, чтобы выйти в интернет. И хорошо, когда библиотека принимает рациональный параметр — в виде отдельного пути для хранилища с сертами. А если нет?
В случае фп — все просто. В случае классического ООП — ты реально запаришься фоткать стандартный класс для tls, а потом прокалывать везде его своего кастомного наследника. Абстракция течет просто нещадно.
нас была функция купитьКофе(), которая инкапсулировала в себе платеж
Мы говорим про классический ООП? Функция купитьКофе() где будет? В инстансе покупателя, кофейни или где ещё? Вообще в этом отношении smalltalk'а на вас нет. Функции — зло, обмен сообщения — добро. Странно, что не все ещё стали писать в этом стиле. Зато все красиво разделено и масшатбируемо.
Автор предлагает вынести кишки наружу, то есть мы получим функционально-чистый подход, но при этом существенно ослабим инкапсуляцию!«Кишки наружу» звучит как Inversion of Control, а это рекомендуемый подход и в императивном коде. Инкапсуляция касается лишь области ответственности кода, который в ООП должен работать лишь со своими данными, поддерживая инварианты логики.
Когда у вас приложение из 1000 таблиц, 200 форм и миллиона строк кода — любая протечка инкапсуляции уменьшает желание переиспользовать этот кусок кода.При таких масштабах теряется контроль над сложностью и чистота с иммутабельностью занимают одно из первых мест по борьбе с ней.
Оба моих комментария не касаются ФП вообще, замечу.
В итоге такую систему хрен протестируешь.Низкое качество отдельных или большинства продуктов не налагает на нас никаких обязательств повторять тот же путь.
Для этого нужно полностью «спрятать» всю логику таблиц от разработчика и начинать работать в другой парадигме. Например, как я писал в статье. Но учитывая, что статью заминусовали, то идея — «так себе» :)
И, как правильно указано в статье, ООП и ФП — это все таки разные вещи, напрямую не связанные друг с другом.
Функции, например, в LINQ (и в том же lsFusion) именно «компилируются» в SQL запросы и по сути выполняются на сервере. Поэтому падение производительности — минимально. И я бы не сказал, что LINQ не взлетел. Им достаточно активно пользуются, не переходя во многих случаях к написанию SQL-запросов в лоб.
Не раз работал на проектах, где ручное собирание SQL запросов и хранимки были запрещены. Вся логика должна была быть в коде, и оптимизации тоже должны были производиться над LINQ-цепочкой.
Иногда очень хотелось забить и просто написать SQL, а не думать, какой бы LINQ сгенерировать чтобы нахачить оптимизатор чтобы он выполнил код так, как мне надо, но в целом рассматриваю это скорее плюс.
А в 90% запросов SQL просто тупо не нужен, EF генерирует тот же код что руками бы был написан.
Ссылочная прозрачность — это ссылочная прозрачность, — серьезно ответил программист, вставая, — функции, объекты — все едино, пропорции условны, а границы размыты. Я не святой, писал программы не только на ассемблере. Но если мне приходится выбирать между java и c# — я предпочитаю не выбирать вовсе.
int Factorial(int n)
{
int result = 1;
for (int i = 2; i <= n; i++)
{
result *= i; // ???
}
return result;
}Вы дали определение вида "состоит из чистых функций", так? Ну так у вас вон оператор '*=' как раз не является чистым (при одних и тех же входных данных — переменной i, результат может быть каким угодно) => вся функция не является чистой. И чем глубже вы в это залезаете, тем ближе вы к определению "не меняет состояние".
С фига ли функция не является чистой, если она детерминирована и у нее нет побочных эффектов?
f :: a->State s b не чистая,
Но runState (f x) s0 — чистая.
Такой вот фокус.
С чего бы она не чистая? А runState на вход что принимает? Случаем не State? Который в программе нельзя создать, раз по-вашему функции создания стейта запрещены.
State s — монада, внутри которой есть доступ к состоянию
и, с этой позиции, вычисление a->(State s) b не является чистой функцией от a.
Но, после разворачивания, вычисление становится чистой функцией от (a,s).
Побочный эффект это не только IO.
Любая монада — это просто обёртка для более удобной работы с неизменяемым состоянием. Всегда можно расписать без её использования.
В более примитивных языках у нас нет возможности инкапсулировать изменяемое состояние, поэтому там допускается ограниченно изменяемое состояние. Посмотрите на ключевое слово pure в языке D, оно именно так и работает.
Вы написали
f :: a -> State s b не чистая
НО любая функция, которая просто возвращает объект — чистая. функция F просто возвращает структуру с двумя генерик параметрами. Каким образом она не чистая?
А функция g :: a -> Either s b чистая? В чем между ними разница?
Ха ха ха, ловкость рук и никакого мошенничества, что бы первый пример стал функциональным из него нужно выкинуть Log.Info($"Computing factorial of {n}"), а что бы второй перестал быть таковым, в него нужно добавить эту замечательную инструкцию.
Верно. Это иллюстрация того факта, что не навороченные флюент интерфейсы делают программу функциональной, а несколько иные свойства.
Нет, наличие этой конструкции на функциональности никак не сказывается. И тот и другой пример могут быть функциональным или не быть функциональным в зависимости от того, как мы их интерпретируем. Программа не может быть (или не быть) функциональной. Функциональной бывает интерпретация программы.
Программа не может быть (или не быть) функциональной.
Согласно определению автора, данному в начале статьи, еще как может.
Функциональная программа — программа, состоящая из чистых функций.
Все ваши философские вопросы в корень пожалуйста.
Согласно определению автора, данному в начале статьи, еще как может.
В том и дело, что не может. По крайней мере — не может содержательно. Вот я написал программу на хаскеле, которая выводит в консоль некоторый текст. Вопрос — это программа функциональная или нет?
Если ответ "да" — то тогда полезных функциональных программ просто не существует — так как любая полезная программа совершает некий полезный побочный эффект.
Если ответ "нет" — то не существует нефункциональных программ, т.к. любой побочный эффект на любом ЯП является, семантически, эффектом внутри автозалифченного ИО.
Т.о., само понятие оказывается бессодержательным — т.к. либо абсолютно все полезные программы функциональны, либо нет, с-но, отделять друг от друга нечего.
С моей точки зрения чистая функциональная программа это то, что состоит из вызовов чистых функций, а не их определений.
Это определение относится не к тому, что делает программа, а из чего она собрана — т.е. это некоторый способ соединения частей программы.
Это полезно, например, для того, чтобы понимать какие преобразования мы можем делать с программой без нарушения ее работы.
Побочный эффект, это, что-то не являющееся возвращаемым результатом функции, трансформировать функцию с побочным эффектом в чистую функцию просто, достаточно передать состояние вселенной в качестве аргумента, и вернуть в качестве результата (правда, для этого нужен особый тип с особыми ограничениями)
С моей точки зрения чистая функциональная программа это то, что состоит из вызовов чистых функций, а не их определений.
Так а какая разница? Нет содержательного способа отличить чистую функцию от грязной, об этом речь.
Это полезно, например, для того, чтобы понимать какие преобразования мы можем делать с программой без нарушения ее работы.
Но мы не можем.
Побочный эффект, это, что-то не являющееся возвращаемым результатом функции
Ну вот в хаскеле ф-я, возвращающая ИО, является чистой или нет? Если является — то грязных функций не существует, т.к. любую грязную ф-ю в любом языке можно рассматривать как функцию, возвращающую ИО.
Побочный эффект, это, что-то не являющееся возвращаемым результатом функции, трансформировать функцию с побочным эффектом в чистую функцию
Что вы подразумеваете под "чистой ф-ей" в данном случае?
любую грязную ф-ю в любом языке можно рассматривать как функцию, возвращающую ИО.
И только в этом случае она будет чистой, потому что побочный эффект будет заключён в возвращаемом значении (этом самом IO). Если она не рассматривается на уровне языка как возвращающая IO — то является грязной, потому что в возвращаемом значении нет никакой информации о совершённом вводе-выводе.
Если она не рассматривается на уровне языка как возвращающая IO
Так любую функцию можно на уровне языка рассматривать, как возвращающую ИО.
Но не во всяком языке это делается, я об этом.
В смысле не во всяком? Во всяком. В том и соль. Хоть на брейнфаке делается это все без каких-либо проблем.
Во всяком типизированном языке это может быть сделано, но не во всяком реально делается. Функция printf возвращает int, а не IO<int>. Что касается брейнфака — говорить о чистоте функций в нетипизированном языке, имхо, вообще довольно странно, т.к. интерпретация возвращаемого значения целиком лежит на программисте, "на уровне языка" они все одинаковы.
Во всяком типизированном языке это может быть сделано, но не во всяком реально делается.
Не понимаю, в чем разница между делается и реально сделано? Да и в нетипизированном тоже можно.
т.к. интерпретация возвращаемого значения целиком лежит на программисте
Так она всегда лежит на программисте. Это же интерпретация. Она существует только в голове того, кто читает код, больше нигде. Ну, на бумажке еще можно записать.
Так она всегда лежит на программисте. Это же интерпретация. Она существует только в голове того, кто читает код, больше нигде.
Хаскеллисты, у которых компилятор гарантирует, что неправильно использовать полученное IO можно только специально, смотрят на эти слова с недоумением. Вот это — "реально сделано".
Хаскеллисты, у которых компилятор гарантирует, что неправильно использовать полученное IO можно только специально, смотрят на эти слова с недоумением.
Так я в любом языке могу ф-и считать лифтанутыми в ИО. Какая разница?
Вот это — "реально сделано".
Что именно реально сделано? Я не могу понять. Есть хаскель и какой-то другой язык. В них обоих есть ф-я prinln, которая, по факту, выводит текст на консоль. И в обоих случаях я могу считать (а могу и не считать), что эта ф-я чистая и на самом деле не выводит ничего на консоль, а возвращает некоторое вычисление.
В какой момент появляется отличие? Где тут водораздел?
Многие вообще не совсем понимают, зачем эти ио или уникальные типы. Смысл то не в том чтобы сделать ф-ю чистой, эти ф-и остаются грязными, в том смысле, что де факто вполне очевидно исполняют эффекты. Смысл в том, чтобы было удобно смотреть на них как на чистые. При этом удобство не является необходимым условием, да и вообще категория субъективная — кому-то удобно, а кому-то не очень.
Т.е. чистая у вас println или нет — это не свойство языка. Это свойство вашей ментальной модели, в рамках которой вы работаете в данный момент (она меняется постоянно, по факту, в зависимости от задачи). Поменялась ментальная модель — поменялась чистота println. По-этому сама println, в отрыве от ее текущей интерпретации конкретным программистом, не может быть чистой или нет.
эти ф-и остаются грязными, в том смысле, что де факто вполне очевидно исполняют эффектыНо ведь в Haskell print не исполняет эффекты, не более чем
def pure_print(s: str) -> Callable[[], None]:
return lambda _: print(s)
По тому определению чистой функции, что я вижу в google, этот pure_print — чистый: возвращается одна и та же функция (нечистая, но это не запрещено), состояние снаружи не меняется.
В какой момент появляется отличие?Наверно, в тот момент, когда вызов одной сам по себе имеет сторонние эффекты, а вызов другой — нет. Если мы определяем понятие чистоты в программировании, то стоит вкладывать в него конкретный смысл, либо определять нет смысла, когда все функции и чистые, и нечистые.
Но ведь в Haskell print не исполняет эффекты
Как раз исполняет. Если эту ф-ю вызвать, то она выводит текст на консоль — по факту выводит. Не важно, какой вы напишите для нее тип или еще что.
По тому определению чистой функции, что я вижу в google, этот pure_print — чистый
По этой логике printf в сишке тоже будет чистая, т.к. никто не мешает ее считать сахаром над (s: str) -> Callable[[], None]. Т.о. грязных ф-й не существует в природе, а если их не существует в природе — зачем вообще тогда разделение на грязные чистые?
Наверно, в тот момент, когда вызов одной сам по себе имеет сторонние эффекты, а вызов другой — нет.
Так в обоих случаях эффекты есть.
либо определять нет смысла, когда все функции и чистые, и нечистые.
Ну об этом я и говорю. Нельзя определить такое понятие как "чистая функция", т.к. согласно ему либо все ф-и будут чистые, либо все — нет.
Определить можно только чистую интерпретацию.
Допустим вы воспринимаете программу на C как синтаксический сахар для программы на haskell, где все функции подняты в IO.
Однако, такая программа частично будет состоять из функций, которые подняты в IO, но никак этот факт не используют.
Т.е. все функции поделятся на два типа, которые декларируют использование IO и его на самом деле используют и те, которые декларируют использование IO но его не используют.
Как только вы мысленно уберете IO из типа этих функций у вас будут ошибки мысленной компиляции.
Т.е. восприятие программы как чисто функциональной подтолкнет к разделению частей, которые общаются со внешним миром и тех которые не общаются и позволит использовать вам и инструментам некоторые механизмы
для рассуждения о них.
Ну, очевидно ответ "когда монада интерпретируется, если интерпретация нарушает ссылочную прозрачность". То есть выполнение ИО.
С моей точки зрения она всегда чистая (я не очень силен
монадах). Просто когда вы ее выполняете внутри монады завернут RealWorld (состояние мира) и оно всегда разное, а способов его генерировать запоминать и не возвращать не бывает.
Функция чистая не тогда когда у нее нет эффектов, а когда нет побочных эффектов — т.е. чего-то не являющимся возвращаемым значением. Если представить состояние всего мира как аргумент и
возвращаемое значение (типа такая особенная гигантская стейт монада) то это чистая функция — она не делает ничего что не является трансформацией аргумента в результат, т.е. нет побочных эффектов.
Это только если вы придумаете свой язык с синтаксисом, допустим C#, и будете приписывать ко всем функциям IO (назовем его, допустим IO#). В реальном языке C# никакого IO, его нет в документации библиотеках и reflection. Язык — это договоренность относительно того, что, что означает.
Как только вы придумаете такой язык, он будет бессмысленным, так как там будет две категории функций — те, к которым осмысленно приписано IO типа Console.WriteLine и те, к которым бессмысленно приписано IO типа String.Concat и нет никакого способа не приписывать IO к функциям и от этого приписывания нет никакой выгоды.
Т.е. вы можете мысленно транслировать C# на очень похожий бессмысленный язык IO# но
это будет другой язык, так как то, что считать параметром а что считать возвращаемым значением уже определено в спецификации C#
это будет бессмысленный язык так как на нем не будет возможности не приписывать IO к функциям.
Т.е. вы можете мысленно транслировать C# на очень похожий бессмысленный язык IO#
В том и дело, что транслировать ничего не надо. Вам не надо переписывать код на обычном C# и не надо менять поведение этого кода, чтобы сделать автолифтинг в ИО.
Это будет обычный код на обычном C#. Тот же самый код на точно том же самом языке.
Как мне сделать функцию без автолифтинга? Как мне по сигнатуре отличить функцию которая считает факториал от другой, которая считает факториал и пишет "ололо" в консоль?
А какая разница? При чем тут вообще сигнатуры? Мы же про эффекты. Ф-я либо имеет сайд-эффекты, либо их не имеет (если это объективное свойство) — это никак не может зависеть от ее сигнатуры, сигнатура вообще по терму автоматически выводится при разрешимом тайпчеке. Т.е., если терм дан — уже ясно должно быть, чистый он или нет.
Давай для простоты считать, что мы рассматриваем ЯП с динамической типизацией, чтобы тебя не смущали несущественные для обсуждения детали, раз с деталями слишком сложно.
Ну пусть это будет, допустим, питон, для определенности. Мы можем написать для питона денотационную семантику, и все ф-и в питоне в этой семантике станут обычными математическими ф-ми. Т.е. будут, например, возвращать вычисление, выводящее что-то на консоль, а не выводить на консоль сами. При этом питон останется тем же питоном.
А какая разница? При чем тут вообще сигнатуры? Мы же про эффекты. Ф-я либо имеет сайд-эффекты, либо их не имеет (если это объективное свойство) — это никак не может зависеть от ее сигнатуры, сигнатура вообще по терму автоматически выводится при разрешимом тайпчеке. Т.е., если терм дан — уже ясно должно быть, чистый он или нет.
При всём. Меня интересует ссылочная прозрачность значений в программе. То есть иметь возможность заменить вызов функции на результат.
Если у меня все функции ИО то я эффективно ничего с ними не могу сделать безопасно. Вместо вызова функции foo = 1000 строк нечитаемого кода; pure 42 я хотел бы просто подставить 42, но в общем случае не могу этого сделать. Поэтому весь смысл всего этого обмазывания IO именно в том, чтобы знать, в каком случае функцию можно заменить только на результат в последней строчке.
Давай для простоты считать, что мы рассматриваем ЯП с динамической типизацией, чтобы тебя не смущали несущественные для обсуждения детали, раз с деталями слишком сложно.
А в динамике все эти расстуждения особо не нужны. Смысл ФП в том, чтобы статически можно было доказывать некоторые инварианты, свойственный программе. Чтобы можно было рефакторить, не нарушая означенные инварианты. В динамике очевидно этого сделать не получится.
Если бы в питоне все нечистые функции были бы асинхронными промисами, из которых можно было бы собрать один большой промис и вернуть из мейна, тогда другое дело, но так никто не делает.
Ты не поверишь, но меня интересует не восторжение математической красотой полученного решения, а практическая сторона вопроса. Надежность, поддерживаемость, отказоустойчивость — вот это всё.
То, что можно придумать такую денотационную семантику для сишки/питона, что она 1:1 будет соответствовать хаскеллю — да не вопрос, верю. Только так никто не пишет. А рассуждения про то что это теоретически возможно мне не интересны. Я вижу факт — есть в библиотеке printf, я его вызываю, игнорирую результат, а текст на экране все равно появляется. И то что можно написать printf2 который вернет ИО который надо проинтерпретировать мне не интересно, потому что никто такой принтф не написал, библиотеки вокруг этого не построены, следовательно этого не существует.
Если у меня все функции ИО то я эффективно ничего с ними не могу сделать безопасно. Вместо вызова функции foo = 1000 строк нечитаемого кода; pure 42 я хотел бы просто подставить 42, но в общем случае не могу этого сделать.
Ну так ты верно заметил — ты не можешь этого сделать уже просто в том случае, если у тебя есть ИО. Так считаем print в хаскеле грязной, значит, раз ее на результат нельзя заменить?
А в динамике все эти расстуждения особо не нужны.
Какая разница, нужны или нет? Мы обсуждаем конкретное свойство ф-и — чистоту. Ты говоришь что это свойство можно объективно как-то по самому терму определить. Вот берем некую ф-ю в динамической языке и определяем — она чистая или нет? Как это сделать?
а практическая сторона вопроса.
Практическая сторона какого вопроса? У нас вопрос конкретный — можно ли дать какое-то практически полезное определение для понятия "чистая функция" (ака "функциональная программа"). Пока что выходит — что нет, нельзя. Потому что нет никакого практического смысла отличать "чистую print" от "грязной Console.WriteLn". Так как ведут себя эти ф-и совершенно одинаково — что с точки зрения практической (выводят текст), что с точки зрения формально-теоретической (можно дать им обеим как "функциональную" так и "нефункциональную" семантику).
Только так никто не пишет.
При чем тут "пишет"? Без разницы как кто пишет — мы берем тот же самый код. Код не надо писать как-то "по особому".
ФП — это не про то, как код пишется. ФП — это про то, как код читается. Вот этого ты понять не можешь. Нельзя написать что-то функциональной парадигме. Но можно что-то в ней прочитать.
Я вижу факт — есть в библиотеке printf, я его вызываю, игнорирую результат, а текст на экране все равно появляется.
Я в хаскеле вижу тот же самый результат.
И то что можно написать printf2 который вернет ИО который надо проинтерпретировать
Не надо писать никакого нового printf, еще раз. ИО возвращает самый обычный printf. Не надо никаких специальных библиотек, не надо ничего куда-то там строить. Просто берешь и пишешь обычный printf и он возвращает ИО. Точно такое же, как print в хаскеле.
Ну так ты верно заметил — ты не можешь этого сделать уже просто в том случае, если у тебя есть ИО. Так считаем print в хаскеле грязной, значит, раз ее на результат нельзя заменить?
Можно заменить на результат. Я уже приводил демаркационный пример, если let _ = makeSomeIo ничего не производит, то ИО чистое, иначе — нет.
Какая разница, нужны или нет? Мы обсуждаем конкретное свойство ф-и — чистоту. Ты говоришь что это свойство можно объективно как-то по самому терму определить. Вот берем некую ф-ю в динамической языке и определяем — она чистая или нет? Как это сделать?
Ссылочная прозрачность. Если бы питон возвращал IO () то я мог бы отменить это действие, не использовав биндинг. Но я не могу.
Потому что нет никакого практического смысла отличать "чистую print" от "грязной Console.WriteLn".
Третий раз говорю, что отличать можно. Как мне сначала вызвать Console.WriteLn, а потом отменить факт того, что я его вызывал? Вот вариант на хаскелле:
let _ = print "Hello world"
pure ()При чем тут "пишет"? Без разницы как кто пишет
Мне — важно.
Я в хаскеле вижу тот же самый результат.
Ну так посмотри олучше.
Не надо писать никакого нового printf, еще раз. ИО возвращает самый обычный printf.
Тогда как мне отменить результат вывода текста на экран?
Ну давайте чуть усложним:
let foo = print "Hello"
case foo of (IO "Foo") -> print "It was foo"
_ -> Вам придется выполнить функцию print чтобы можно было сматчить результат. В сишке так тоже можно было бы сделать, если бы все действия оборачивали в структуру-дескриптор, но
1) так никто не делает
2) нет гарантий что функция только вычисляет результат.
error: Not in scope: data constructor ‘IO’Можно заменить на результат.
В C# тоже можно заменить на результат.
Ссылочная прозрачность. Если бы питон возвращал IO () то я мог бы отменить это действие, не использовав биндинг.
Это только до тех пор, пока ты считаешь что он возвращает не IO. Если будешь считать, что возвращает IO — то все так же точно.
Третий раз говорю, что отличать можно.
Как?
Как мне сначала вызвать Console.WriteLn, а потом отменить факт того, что я его вызывал?
var x = Console.WriteLn
Ну так посмотри олучше.
Посмотрел. Вижу тот же результат — если я вызову в хаскеле prin то она выводит на консоль (это фактическое поведение, вызвать print так, чтобы она ничего не вывела в хаскеле невозможно — что и логично). Как интерпретировать этот результат — уже другой вопрос. Я могу считать что на консоль вывела сама print, а могу считать что print вернула IO, которео уже в свою очередь запущено чудесным каким-то абстрактным вычислятором. Точно так же я могу считать, что либо Console.WriteLn выводит строку, либо это Console.WriteLn возвращает некоторое IO, которое так же запускается некоторым абстрактным вычислятором.
Разницы никакой нет.
Тогда как мне отменить результат вывода текста на экран?
Что значит "отменить"? Если ты что-то вывел, то ты что-то вывел, путешествовать в прошлое никто пока не научился. Никак не отменишь.
Ничего не мешает сделать "своё" ИО с публичным конструктором.
"Свое" IO можно сделать и в C#, или в условной фп-интерпретированном питоне. но мы вроде договорились, что это все не в счет, т.к. никто такое "своей ИО" не использует, библиотек для него нет и все такое.
Твоя модель не дает мне отличить чистую функцию от "автолифтанутой" функции, вот и вся её проблема.
Ну это тебе не дает. А по факту, с объективной формально-теоретической точки зрения — дает. Постоянно это делаю, брат жив. Советую тебе тоже попробовать.
Вот есть у тебя в динамическом ЯП ф-я f x = x + 2 — она будто бы чистая, хотя типов и ИО никакого нет, прикинь. Или в C# функция something x = (y) => {
var y = x + 2; Console.WriteLn(y), return y; } — тоже могу спокойно считать ее чистой, без каких-либо траблов. А могу — не считать. Зависит от ситуации и моей задачи. Чистота — вопрос интерпретации, не более того.
В C# тоже можно заменить на результат.
Нельзя, я на примере раста показал это вроде.
Это только до тех пор, пока ты считаешь что он возвращает не IO. Если будешь считать, что возвращает IO — то все так же точно.
Если написано ИО я считаю, что возвращается ИО, очевидно. С чего бы мне считать иначе.
var x = Console.WriteLn
Написал так — текст на экран вывелся все равно. в x — пустой тапл. чяднт?
Посмотрел. Вижу тот же результат — если я вызову в хаскеле prin то она выводит на консоль (это фактическое поведение, вызвать print так, чтобы она ничего не вывела в хаскеле невозможно — что и логично).
Делаю невозможную вещь — принт который не выводится:
let x = print "Hello""Свое" IO можно сделать и в C#, или в условной фп-интерпретированном питоне. но мы вроде договорились, что это все не в счет, т.к. никто такое "своей ИО" не использует, библиотек для него нет и все такое.
Но это свойство распространяется и на обычное ИО, которое, сюрприз, есть в хаскелле но нет в сишарпе.
Ну это тебе не дает. А по факту, с объективной формально-теоретической точки зрения — дает. Постоянно это делаю, брат жив. Советую тебе тоже попробовать.
Покажи, как отличить автолифтанутую функу от честного ИО не заглядывая в тело метода. Хоть формально, хоть как.
Если написано ИО я считаю, что возвращается ИО, очевидно. С чего бы мне считать иначе.
А с чего считать, что возвращается ИО? Нет никаких причин ни для первого варианта ни для второго. Может вернуть что угодно, у тебя нет никакой информации чтобы можно было сделать какие-то выводы о характере результата. С-но в этом и смысл, как только ф-я зашкварена об ИО — это равносильно утверждению "хз что там". Это семантика ИО в хаскеле. Именно по-этому ты можешь внутри ИО совершать эффекты — ведь в рамках денотационной семантики они невыразимы.
Написал так — текст на экран вывелся все равно. в x — пустой тапл. чяднт?
Зачем же ты врешь? Ничего не выводится, т.к. функция не запускается.
Делаю невозможную вещь — принт который не выводится:
Не запускается, потому и не выводится. В точности как в C# или в любом другом языке. Запусти ф-ю в main и он будет выведен.
Но это свойство распространяется и на обычное ИО
Но это свойство не распространяется на "обычное ИО". Именно по-этому тебе и пришлось писать свое собственное для примера.
Покажи, как отличить автолифтанутую функу от честного ИО не заглядывая в тело метода
Что такое "честное ИО"? Мы же уже договорились, что под "честным ИО" мы подразумеваем то, что считаем "честным ИО" в данной конкретной модели? Т.е. ф-я с логом может быть, а может и не быть "честным ИО", так?
Зачем же ты врешь? Ничего не выводится, т.к. функция не запускается.
Хочешь докопаться до лени? Ну ок, давай возьмем раст:
async fn io_print() -> () {
println!("Hello IO print")
}
fn print() -> () {
println!("Hello print")
}
fn main() {
let x = io_print();
let y = print();
}Я вызвал функцию io_print, надписи не появилось. Вызов очевидно это когда я пишу function_name с двумя скобочками (), а не то что ты можешь выдумать.
Но это свойство не распространяется на "обычное ИО". Именно по-этому тебе и пришлось писать свое собственное для примера.
Очередной друулинг.
Что такое "честное ИО"? Мы же уже договорились, что под "честным ИО" мы подразумеваем то, что считаем "честным ИО" в данной конкретной модели? Т.е. ф-я с логом может быть, а может и не быть "честным ИО", так?
как отличить io_print от print в примере выше?
Просто оставлю немного бартоша здесь:
From that perspective, a Haskell program is just one big Kleisli arrow in the IO monad. You can compose it from smaller Kleisli arrows using monadic composition. It’s up to the runtime system to do something with the resulting IO object (also called IO action).
Notice that the arrow itself is a pure function — it’s pure functions all the way down. The dirty work is relegated to the system. When it finally executes the IO action returned from main, it does all kinds of nasty things like reading user input, modifying files, printing obnoxious messages, formatting a disk, and so on. The Haskell program never dirties its hands (well, except when it calls unsafePerformIO, but that’s a different story).
Of course, because Haskell is lazy, main returns almost immediately, and the dirty work begins right away. It’s during the execution of the IO action that the results of pure computations are requested and evaluated on demand. So, in reality, the execution of a program is an interleaving of pure (Haskell) and dirty (system) code.
Вызов очевидно это когда я пишу function_name с двумя скобочками ()
Не-не, мы должны в обоих случаях под "вызовом" подразумевать одно и то же. Либо в обоих случаях мы считаем "вызовом" запуск IO, которое вернулось из ф-и (и тогда вызов ф-и, возвращающей ИО, пишет в консоль в обоих случаях), либо мы считаем вызовом сам возврат IO (и тогда при вызове ф-и, возвращающей ИО, ничего не выводится). Если ты каким-то своим произвольным способом под одним и тем же термином понимаешь разные вещи — конечно, у тебя будут проблемы.
Очередной друулинг.
Что прости? Ну покажи мне это свойство в "обычном IO", как ты там собрался результат из-под конструктора вытаскивать? Через unsafePerform?
как отличить io_print от print в примере выше?
Ну, при условии, что первая функция будет возвращать IO, а не Async? Никак, очевидно, это же одна и та же функция будет. Т.е., это эквивалентые термы.
Просто оставлю немного бартоша здесь:
Ну тебе ж с самого начала и пишут: "From that perspective", то есть это просто интерпретация (одна из многих), а не то, как реально работает хаскель. Оставим в стороне ненадолго хаскель, давай про Clean, там очевиднее, т.к. внутренность IO не прячется, как в хаскеле, а имеет явную структуру (т.е. ИО можно реализовать и увидеть как оно работает, а не вводить исключительно ad-hoc).
В Clean ты пишешь ф-ю, которая, например, берет некоторый массив и возвращает новый массив, в котором одно из значений будет изменено по сравнению с последним. Если тип массива уникальный — то в реальности никакого нового массива не создается. Но ты можешь считать, будто бы создается. В реальности — ф-я не чистая. По факту. Она не ведет себя как чистая. Т.к. она берет и меняет значение массива — это то, что она делает. Но ты можешь считать, что она чистая до тех пор, пока грязные эффекты данной ф-и для тебя "достаточно незаметны" (ты не можешь сравнивать "новый" массив со "старым").
Совершенно аналогичная ситуация с ИО в хаскеле — конечно же, при выполнении кода на хаскеле, никто не создает никакие ИО-замыкания (или что-то эквивалентное, для представления вычислений) и не пидорасит их в биндах, чтобы сделать потом над этим какой-то run. Этого ничего там нет, а вызов print в скомпилированном коде не возвращает какую-то там обертку над чем-то (как ты понимаешь, было бы иначе — хаскель бы тормозил просто где-то за уровнем неюзабельности), он просто выводит текст в консоль.
Но при этом ты можешь думать, что это все создается, и что возвращается какой-то условный State X World (точно так же как это можно делать в Clean) — но этого не происходит по факту. Но ты можешь думать, что это происходит. Но оно не происходит.
Так вот, нет никакой разницы, будешь ли ты думать, что происходит то, чего в реальности не происходит, применительно к хаскелю или применительно к какому-либо другому языку. Это все просто модель. Эта модель не соответствует реальному поведению (пока что человечество не придумало ни одной модели, которая бы в точности соответствовала реальному моделируемому объекту, впрочем, от модели такого и не ждут никогда). Но эта модель достаточно корректна, чтобы описывать некоторые важные характеристики программы и делать какой-то ризонинг про нее. Причем этот ризонинг делаться будет совершенно одинаково что в хаскеле, что на сишке.
Причем этот ризонинг делаться будет совершенно одинаково что в хаскеле, что на сишке.
Это касается абсолютно всех программ программ на хаскеле или только того подмножества где есть только монада IO и ни одной функции не использующей этой монады?
Не-не, мы должны в обоих случаях под "вызовом" подразумевать одно и то же. Либо в обоих случаях мы считаем "вызовом" запуск IO, которое вернулось из ф-и (и тогда вызов ф-и, возвращающей ИО, пишет в консоль в обоих случаях), либо мы считаем вызовом сам возврат IO (и тогда при вызове ф-и, возвращающей ИО, ничего не выводится). Если ты каким-то своим произвольным способом под одним и тем же термином понимаешь разные вещи — конечно, у тебя будут проблемы.
Посмотри определение в ЯПах что такое вызов функции. Это именно что вызов со скобочками.
А то что оно делает разные вещи я талдычу уже который раз, видимо теперь до тебя дошло. Интерпретация ИО в термин "выполнение функции" не выходит. И именно разделение формирования ИО и его интерпретация и есть весь профит. Если его схлопнуть в одно то понятное дело нихрена работать не будет. Только это ликвидация основного преимущества. Цитата в темку:
Perhaps you think it is OK to pretend that something is a category when it is not. In that case, you would also pretend that the Haskell monads are actual category-theoretic monads. I recall a story from one of my math professors: when she was still a doctoral student she participated as “math support” in the construction of a small experimental nuclear reactor in Slovenia. One of the physicsts asked her to estimate the value of the harmonic series 1 + 1/2 + 1/3 + ⋯ to four decimals. When she tried to explain the series diverged, he said “that’s ok, let’s just pretend it converges”.
Далее
Что прости? Ну покажи мне это свойство в "обычном IO", как ты там собрался результат из-под конструктора вытаскивать? Через unsafePerform?
Никак не собрался, у меня есть система типов которая поможет мне и скажет "чувак, тут ИО, нужно оборачивать в другое ИО". Когда она этого не говорит (в сишке) — начинаются проблемы. Если переформулировать: то из под конструктора СЛУЧАЙНО достать значение в хаскелле я не могу, а с автолифтанутыми функциями псевдоси — изи.
Ну, при условии, что первая функция будет возвращать IO, а не Async? Никак, очевидно, это же одна и та же функция будет. Т.е., это эквивалентые термы.
IO === Async, в этих языках. С одними и теми же свойствами. Не надо выдумывать различий которых нет. Это в хаскелле это разные типы только по историческим причинам. Как return vs pure, в первом нет никакого смысла, но он есть.
Ну тебе ж с самого начала и пишут: "From that perspective", то есть это просто интерпретация (одна из многих), а не то, как реально работает хаскель.
Это единственная перспектива которая меня интересует, потому что эта модель помогает мне делать reasoning о флоу кода, а твоя модель — не позволяет (я не могу отличить >>= от unsafePerformIO).
Посмотри определение в ЯПах что такое вызов функции. Это именно что вызов со скобочками.
В хаскеле нет скобочек. В хаскеле функции не вызываются? Чем в хаскеле вызов нульарной ф-и отличается от константы, не подскажешь?
А то что оно делает разные вещи я талдычу уже который раз
Но это чушь. Оно делает одни и те же вещи просто по факту. Ты можешь притворяться, что оно делает разные вещи — точно так же как ты можешь притворяться что в Clean у тебя массивы копируются. Не более того.
И именно разделение формирования ИО и его интерпретация и есть весь профит.
Так это разделение существует только в голове у программиста. Это ты никак и не хочешь понять. Функция возвращающая ИО, которое выводит что-то на экран и функция выводящая что-то на экран — это по определению, просто в силу семантики своей, одна и та же функция.
Далее
Очень забавно, что как раз гармонический ряд — наверное, самый известный случай, когда можно объявить, что "пусть ряд сходится и пусть он равен -1/12" — и это будет полностью осмысленно, и будет приносить профит, и на практике приносит.
Никак не собрался
Если не вытаскивать — где обсуждаемое свойство?
а с автолифтанутыми функциями псевдоси — изи.
Вытащить что-то из-под конструктора в ИО тебе запрещает не могучая система типов хаскеля, а банальное отсутствие конструктора в скопе. Точно так же в сишке ничего не вытащишь — конструктора-то нет, как вытаскивать собрался?
IO === Async, в этих языках.
kek. IO === Id !== Async.
Это в хаскелле это разные типы только по историческим причинам
IO и Async разные типы по историческим причинам? :cry:
Ничего что у них семантика совершенно разная? Если это один и тот же тип, то почему оно компилируется в принципиально разный код?
Это единственная перспектива которая меня интересует, потому что эта модель помогает мне делать reasoning о флоу кода
Так я про это тебе и талдычу.
а твоя модель — не позволяет
Все верно, ризонинг (ну т.е. свойства которые ты можешь исследовать) зависит от применяемой модели.
Когда ты смотришь на хаскель как на сишку (используешь императивную модель), то ты не можешь делать о программе на хаскеле какой-то разумный ФП-ризонинг.
Но ты почему-то вычеркиваешь двойственное утверждение — если ты используешь ФП-модель для кода на сишке, то ты можешь точно так же делать точно тот же самый ризонинг для кода на сишке, который ты делаешь для кода хаскеле.
Здесь совершенно зеркальная ситуация. Какую модель применяешь — тот ризонинг и делаешь.
я не могу отличить >>= от unsafePerformIO
Нигде не можешь, т.к. bind выражается через unsafePerformIO. Т.е. любой код с bind можно заменить на код с unsafePerformIO, который делает все точно то же самое и обладает всеми теми же самыми свойствами. А этот код с unsafePerformIO можно потом наоборот свернуть в код с bind. Просто синтаксическая разница (до тех пор пока unsafePerfomIO используется корректно, конечно же).
В хаскеле нет скобочек. В хаскеле функции не вызываются? Чем в хаскеле вызов нульарной ф-и отличается от константы, не подскажешь?
Ничем. Но ведь раст это не хаскель.
Но это чушь. Оно делает одни и те же вещи просто по факту.
нет
Если не вытаскивать — где обсуждаемое свойство?
Тебе ли не знать что через bind можно работать со значением внутри. Но достать его — анейсперформио и низя, да.
Вытащить что-то из-под конструктора в ИО тебе запрещает не могучая система типов хаскеля, а банальное отсутствие конструктора в скопе.
Вытащить что-то из под конструктора нельзя потому что это ломает все преимущества, и сиганутры начинают врать
kek. IO === Id !== Async.
IO === id… Ты забыл выпить свои таблетки?
Но ты почему-то вычеркиваешь двойственное утверждение — если ты используешь ФП-модель для кода на сишке, то ты можешь точно так же делать точно тот же самый ризонинг для кода на сишке, который ты делаешь для кода хаскеле.
Потому что к сишке эту модель никто не применил. Потому что от ФП модели можно откатиться к ИП модели (запилить unsafeperformIO вместо биндов и порядок), только вот обратно — нет. Потому что информации в ФП строго больше. Отображение ФП модели на ИП сюръективное и необратимое, потому что маппит функи io_print и unsafe_print на один сишный print.
Нигде не можешь, т.к. bind выражается через unsafePerformIO.
Не выражается.
Ничем. Но ведь раст это не хаскель.
Т.е. у тебя два разных определения "вызова" в расте и в хаскеле. Что ты пытаешься вывести на основе такой подмены понятий? В расте-то нульарные ф-и от констант отличаются, нет?
нет
Как нет, если я пишу код main = print 'yoba' на хаскеле, и он мне выводит йобу, я пишу код на условном хаскеле без ио main = print 'yoba', и он мне тоже точно так же выводит йобу. В чем разница? Если две программы ведут себя эквивалентно я говорю, что эти программы эквивалентны. Это же очевидно.
Тебе ли не знать что через bind можно работать со значением внутри.
Так тебе именно достать надо :cry:
Именно за этим ты там выше выдумал "свое костыльное ИО" — потому что твой пример необходимо требовал возможности достать изнутри значение. На "обычном" ИО он просто не пишется.
Вытащить что-то из под конструктора нельзя потому что это ломает все преимущества, и сиганутры начинают врать
Вытащить что-то из-под конструктора нельзя потому, что конструктор неимпортирован. Если бы он был импортирован — вытащить было бы можно, и это бы в сигнатурах ничего не сломало.
Хаскель — не Clean, никакие сигнатуры не будут врать от того, что ты вытащил значение из ИО, в том-то и штука (собственно, unsafePerformIO вытаскивает значение из IO, при том имеет корректную сигнатуру, относительно которой реализация корректно тайпчекается). В хаскеле нет никакого способа сформулировать "вот эта ф-я возвращает йобу, а вот эта возвращает йобу и еще пишет в файл или консоль или отправляет что-то по сети". Так просто договорились, что будут к возвращаемому типу таких ф-й (которые выводят, пишут, шлют по сети) добавлять IO, но при этом IO вводится как ad-hoc конструкция, ее поведение в рамках семантики хаскеля — неопределено и наличие ИО само по себе никак не влияет на поведение функции. С точки зрения хаскелевской семантики разницы между ф-ей, которая что-то возвращает и ф-ей, которая возвращает то же самое, но при этом еще и кудато там пишет — просто нет. Внутри "мира хаскеля" разницу между этими функциями нельзя пронаблюдать.
IO === id
Код в IO ведет себя во всех контекстах в точности так же как код в Id. Гарантии корректности ИО в хаскеле форсятся не формой ИО (ее нельзя задать, т.к. хаскель не достаточно выразителен), а характером вызова биндов и тем, что никак кроме биндов ты не можешь связывать вычисления.
Если ты возьмешь код на хаскеле, заменишь там везде IO на Id, а потом запретишь экспорт конструктора Id (чтобы из Id нельзя было ничего вытащить) — поведение кода не изменится. Твои программы будут делать ровно то же самое что и делали. Все сайд-эффекты будут выполняться корректно и в нужном порядке.
Потому что к сишке эту модель никто не применил.
Я применяю регулярно. Ну, не на сишке, да. Сишка же у нас условная (т.е. просто какой-то нехаскель)?.. Да куча людей регулярно применяет, многие, скорее всего, и конкретно на сишке.
Потому что от ФП модели можно откатиться к ИП модели (запилить unsafeperformIO вместо биндов и порядок), только вот обратно — нет.
В смысле, нет? Что помешает? Постоянно так делаю, и никаких проблем не возникает, брат жив. Я маг что ли какой-то, что совершаю невозможное?
Потому что информации в ФП строго больше.
Какой информации? То, что все сайдэффекты находятся внутри IO — это просто договоренность, которая никак не контролируется со стороны самого языка (в хаскеле, по крайней мере). Точно так же ты можешь договориться, что у тебя в сишке будут чистые функции и они будут на конце имени иметь pure.
Или просто посмотреть на ф-ю, увидеть что она логов не пишет, в сеть не лезет и сказать: "она чистая", и дальше можешь спокойно считать эту ф-ю чистой и применять все те же рассуждения для таких чистых ф-й, которые ты применяешь в хаскеле. Это все вопрос договоренностей. До тебя это не доходит все никак. Ничего не значащая и ничего не делающая приписка IO к типу по факту ни на что не влияет, точно так же как и приписка к имени. Это просто приписка. Синтаксический костыль для удобства. Нам надо как-то отделять одни ф-и от других, вот по-этому к типу одних из них будем приписку делать. Все, на этом заканчивается весь рокет сайенс.
давай упростим.
Вот есть функция: int printStuff(), как мне не заглядывая в тело функции узнать — вызывает она printf("Hello") или нет?
Вот есть функция: int printStuff(), как мне не заглядывая в тело функции узнать — вызывает она printf("Hello") или нет?
Ну, очевидно, что вся информация о семантике ф-и находится в ее теле и только в нем, с-но, не зная тела — нельзя ничего сказать о семантике.
Можно, однако, договориться какую-то часть этой информации указывать в некотором другом месте — в названии ф-и (все ф-и с print в имени вызывают print, значит и printStuff вызывает), в типе, в документации. Если такой договор есть и мы верим, что человек, который ф-ю писал, ему следует — то надо, с-но, посмотреть на имя функции/тип/документацию и выяснить, вызывает она внутри print или нет. Если же договоренности нет (или веры нет) — только тело смотреть, других вариантов не остается.
А ещё можно договориться, что определённую часть договора проверит компилятор, так что верить человеку, который писал функцию, в каком-то вопросе не потребуется. Не для этого ли нужно явное наличие типа IO?
А ещё можно договориться, что определённую часть договора проверит компилятор
В случае ИО в хаскеле компилятор ничего не проверяет (да и не может проверить по достаточно очевидным причинам). Там именно что договор уровня "мамой клянусь" между людьми.
да и не может проверить по достаточно очевидным причинам
По каким?
Насколько я понял, он проверяет и заставляет громко поклясться мамой (unsafeperformio) что легко отличимо на code review либо не использовать.
Насколько я знаю, есть раcширение Safe Haskell в GHC которое позволяет отличать тех кто клянется мамой от тех кто использует чужие клятвы мамой и выбирать доверять этим клятвам или нет.
Во-вторых, "проверяет" не то же самое, что "проверяет и дает 100% гарантию". 100% гарантии нигде нет.
сли такой договор есть и мы верим, что человек, который ф-ю писал, ему следует — то надо, с-но, посмотреть на имя функции/тип/документацию и выяснить, вызывает она внутри print или нет.
Если договоренность есть, то можно написать инструмент, который будет проверять это. Если договоренности нет, то придется исследовать все дерево вызовов.
Язык программирования вообще это договоренность. Наши рассуждения для времени выполнения программы справедливы лишь настолько насколько разработчики компилятора и рантайма соблюдают свои договоренности.
100% гарантии никогда нет — бывают ошибки в компиляторах или рантаймах.
Если же договоренности нет (или веры нет) — только тело смотреть, других вариантов не остается.
Т.е. есть разница между наличием и отсутствием договоренностей?
Можно, однако, договориться какую-то часть этой информации указывать в некотором другом месте — в названии ф-и (все ф-и с print в имени вызывают print, значит и printStuff вызывает), в типе, в документации.
Только типы — валидируются, а вот имена функций и документация — нет
Если такой договор есть и мы верим, что человек, который ф-ю писал, ему следует — то надо, с-но, посмотреть на имя функции/тип/документацию и выяснить, вызывает она внутри print или нет. Если же договоренности нет (или веры нет) — только тело смотреть, других вариантов не остается.
Я могу написать линтер который запретит использовать unsafePerformIO и будет ворнить за undefined. Тогда если проект собирается без ворнингов, я могу быть уверенным что функция в консоль не пишет.
Как мне что-то такое сделать вне хаскелля?
Если говорить понятнее, то в хаскелле сформировалась культура, как в языке, так и в библиотеках, где ИО от не-ИО отделены, и договоренности соблюдается.
В сишном мире таких договоренностей нет, а те, которые есть, не сболюдаются.
Поэтому то что "ночью все кошки серые" — это интересное наблюдения, но с практической точки зрения это неинтересно. Интересно, могу ли я взять инструмент и иметь какие-то гарантии (пусть даже не стопроцентные, а хотя бы с некоторой точностью) или нет.
Только типы — валидируются, а вот имена функций и документация — нет
И каким именно образом хаскель валидирует, что какая-нибудь core ф-я не пишет в консоль?
Тогда если проект собирается без ворнингов, я могу быть уверенным что функция в консоль не пишет.
Если у нас будет в некотором языке договор, что разработчики все "пишущие в консоль ф-и" некоторым образом промаркировали, то можно запретить импорт ф-й с этим маркером (аналог твоего линтера) и применение фунаргов. Тогда ф-я, определенная в файле с этим запретом импорта и без фунаргов, гарантированно не пишет в консоль.
Поэтому то что "ночью все кошки серые" — это интересное наблюдения, но с практической точки зрения это неинтересно.
С практической точки зрения эти договоренности не имеют никакого отношения к ФП, вот в чем штука. Ну договорились и договорились, окей, это полезно, это можно использовать, тут никто не спорит.
Нельзя заменять bind на unsafePerformIO пока unsafePerfomIO используется корректно, потому что это будет некорректное использование unsafePerfomIO.
это будет некорректное использование unsafePerfomIO.
"Некорректное" в каком смысле? Программа будет вести себя точно так же как до преобразования, эффекты будут исполняться в ожидаемом порядке и в соответствии со спецификацией (ну, формально, надо тогда не просто фунарг применить, а зафорсить его перед этим, т.к. хаскель ленивый, но это несущественные детали). Почему это "некорректно"?
Смысл ФП в том, чтобы статически можно было доказывать некоторые инварианты, свойственный программе.
А можно узнать источник такого смысла? Мне всегда казалось, что ФП/ИП и статическая/динамическая типизация (как и сильная/слабая) ортогональны друг другу. А смысл ФП в контролируемости побочных эффектов и в детерминированности чистых функций.
Ну вот ссылочная прозрачность — это как раз такой инвариант. Например, когда можем менять функцию на результат и обратно.
На практике можно видеть, что все практические ФП языки идут в комплекте с сильной системой типов. Ну просто вот так удобнее получается.
Синтаксически сделать для чистых один синтаксис, для грязных — другой.
Типа того. Как в Паскале процедуры и функции разделены синтаксически. Или как async/await модификаторы в JS — так даже лучше.
В итоге абстрагироваться от функций которые могут что-то вернуть (или нет) в языке невозможно.
Отличное решение, надо его копировать.
В каком смысле абстрагироваться?
Ну вот например вот такой код:
fn execute_any<T>(f: impl Fn() -> T) -> T {
f()
}
fn main() {
println!("{}", execute_any(|| "I'm a function"));
execute_any(|| println!("I'm a procedure"));
}Я принимаю любую функцию или процедуру и возвращаю то же, что и она (ничего в случае процедуры) (а если точнее, юнит).
В дотнете кстати та же проблема с тем, что void нельзя в генериках использовать. В итоге изобретают всякие мусорные значения и не советуют пользоваться воидом. Но что поделать, это всё костыли, и все внешние либы о таких соглашениях не в курсе.
Смысл ФП в том, чтобы статически можно было доказывать некоторые инварианты, свойственный программе.
Чот пропустил. Это просто не так, по двум причинам:
- Статически доказывать можно свойства абсолютно любой программы
- Статически доказывать можно по-разному — т.е., используя разные модели.
Так вот, ФП — это когда ты рассуждаешь о программе (т.е. статически доказываешь свойства) в рамках некоторой интерпретации, которая близка к денотационной семантике (и в пределе ей в точности соответствует), выбирая вполне конкретный тип. мат моделей из многих возможных. Еще раз — не когда ты как-то там по особому программу пишешь, а когда ты об уже написанной программе (пусть она у тебя и в голове будет написана) рассуждаешь. Рассуждаешь определенным образом. Рассуждать таким образом можно о любой программе на любом ЯП.
А код — это не только поведение. Код — это еще и восприятие человеком. Для людей нужны названия переменных, комментарии, разбиение на функции для понятности и так далее.
Еще мне интересно как вы автолифтанете reflection. Я не очень во все этих монадах. Но мне кажется, что тогда из семантики языка придется убрать всякие int и прочее и оставить только IO int либо думать о что MethodInfo.GetParameterType возвращает анлифченный тип параметра.
Йэп.
Грязная часть это интерпретация ИО. Его создание — чистая вещь.
Вся грязная работа происходит за пределами main, поэтому с точки зрения программы её эффективно не существует.
Я так понимаю, что когда она интерпретируется то тоже нет сайд эффектов, так как состояние мира передается как RealWorld
Если эту ф-ю вызвать, то она выводит текст на консоль — по факту выводит.
Насколько я помню, если полученный объект IO не вернуть (непосредственно или завёрнутым в другой IO) из main — ничего этот print не выведет.
Сырые байты в ассемблере можно считать имеющими какой-то тип, но это не делает ассемблер типизированным. Структурки в си можно считать объектами, меточки рядом с enum'ами – размеченными объединениями, а указатели на функции – ФВП, но это не делает си объектно-ориентированным или функциональным с алгебраическими типами.
(правда, я не очень пониманию, что такое интерпретация программы в его, э, интерпретации)
Я здесь подразумеваю некое интуитивное представление (которое, в принципе, может достаточно точно соответствовать некоторой формальной семантике и в любом случае какой-то мере на ней базируется), когда мы о программе рассуждаем, но до полной формальной строгости эти рассуждения не доводим. Специально не писал "семантика" т.к. этот термин в данном контексте уже давно застолблен и имеет четкое значение.
Представьте себе, что в условном C IO написано просто везде, поэтому, чтобы не захламлять программу, договорились его нигде не писать явно — компилятор проставит
Если компилятор проставит, то это значит изменение типа — т.е. я смогу например в своей функции мемоизации проверить не содержит ли тип IO и принять решение могу ли я мемоизировать эту функцию или нет.
Рассуждения Druu верны если отбросить то, что у библиотек, компиляторов, IDE, RTTI и других людей уже есть некоторое соглашение о том, что является типом и аргументами функции а что — нет.
То, что мы мысленно можем преобразовать любую императивную программу в вырожденный случая чисто функциональной программы не означает, что императивная и чисто функциональная программа — одно и то же.
есть некоторое соглашение
Т.е. "функциональность" зависит не от самого кода и не от того, как этот код себя ведет, а от некоторого произвольного "соглашения" людей о том, как этот код воспринимать. Т.е. мы договорились воспринимать хаскелевское ИО как чистое, а принтф сишки — как грязный. Это именно то, о чем я и говорю :)
Смысл ИО в том, чтобы разделять ИО и не-ИО. Поэтому считать что всё в него завернуто (как в си) — бестолку.
Смысл ИО в том, чтобы разделять ИО и не-ИО.
Так мы не это обсуждаем. Мы обсуждаем то, что отделить чистые ф-и от нечистых по объективным критериям нельзя. Это все просто вопрос договоренностей. Вот мы, опять же, договорились не лифтить в ИО ф-и без эффектов.
И ниже вон обсуждается, какой консольный лог в рамках договоренности считать сайд-эффектом, а какой — нет. Или вот аллокация списка в хипе — в хаскеле это не сайд-эффект, а в низкоуровневых языках вроде сишки вполне.
И функциональное программирование, соответственно — это не когда кто-то пишет чистые (в рамках определенной договоренности) ф-и, а когда в голове у программиста в качестве "интерпретации" нечто достаточно близкое денотационной семантике.
Объективный критерий тут простой: является ли функция детерминированной и имеет ли побочные эффекты в момент вызова.
Если функция обладает побочными эффектами — то она не является чистой, даже если её можно переписать как чистую.
Объективный критерий тут простой: является ли функция детерминированной и имеет ли побочные эффекты в момент вызова.
В этом случае ф-и, возвращающие IO в хаскеле — не чистые. Вы с этим утверждением согласны? Они же в момент вызова исполняют сайд-эффекты. В смысле, по факту исполняют — то есть мы можем вызвать ф-ю и пронаблюдать, что сайд-эффект вызван (текст выведен на консоль).
даже если её можно переписать как чистую
Так в том и смысл, что ничего переписывать не надо, любая ф-я УЖЕ может интерпретироваться как чистая. Если мы можем интерпретировать String => IO () в хаскеле (договорившись считать, что сама эта ф-я при вызове ничего не выводит, а лишь возвращает грязное вычисление) как чистую ф-ю, то мы можем точно так же интерпретировать printf в сишке (аналогично договорившись, что эта ф-я сама ничего не выводит, а возвращает грязное вычисление) — разницы нет никакой. Никакие особенности семантики сишки тут ничему не мешают, т.е. подобная интерпретация будет полностью корректной. И какую выбирать интерпретацию из двух — вопрос исключительно нашего желания. Точно так же исключительно вопросом нашего желания является выбор интерпретации для IO в хаскеле. Хотим — считаем эти ф-и чистыми, хотим — считаем их грязными, в обоих случаях мы получаем корректную, непротиворечивую модель.
Фактически, можно даже формализовать мое утверждение — я говорю о том, что для любого языка (и, значит, для любой конструкции данного языка — функции/подпрограммы/метода в том числе) найдется какая-нибудь денотационная семантика и аксиоматическая семантика.
Тут какой-нибудь пример с конкатенативными языками хорошо зайдет — вот если вы в форте напишите "1 2 3" — то это можно интерпретировать как "положить на стек 1, потом положить на стек 2, потом положить на стек 3" — императивненько, сайд-эффекты. А можно — как "композиция ф-й Stack -> Stack", никаких сайд-эффектов, чистая функциональщина. Обе интерпретации распространены, обе широко используются (т.е. это не как в сишке, где мы ИО жопой на глобус натягиваем).
Нет. В Хаскеле, чтобы иметь возможность пронаблюдать текст в консоли, надо вернуть результат работы функции print из функции main, прямо или косвенно. Простой вызов print не делает ничего.
В C# простой вызов Console.WriteLine выводит текст в консоль как только до него доходит управление. У нас как у программиста нет такой опции, как вызвать Console.WriteLine, а потом забыть об этом вызове.
Нет. В Хаскеле, чтобы иметь возможность пронаблюдать текст в консоли, надо вернуть результат работы функции print из функции main, прямо или косвенно.
Это только один из вариантов интерпретации. Есть второй — в котором ф-я пишет в консоль сама по себе. Существование и корректность такой интерпретации гарантируется тем простым фактом, что на практике, а не в теории, все именно так и происходит — print именно сама пишет в консоль, никаких "вычислений" она не возвращает. И, раз это то, что происходит с ф-ей по факту, то, конечно, не может не быть интерпретации, которая просто это фактическое поведение и описывает.
В C# простой вызов Console.WriteLine выводит текст в консоль как только до него доходит управление. У
И это тоже только один из вариантов интерпретации. И так же как в хаскеле вы можете интерпретировать print как возвращающую IO (хотя по факту она IO не возвращает, а пишет в консоль), точно так же и в C# вы можете Console.WriteLine интерпретировать как ф-ю, возвращающую IO (хотя по факту она ведет себя в точности как print в хаскеле — т.е. пишет в консоль, а не возвращает что-то там).
В обоих случаях есть две разные интерпретации. Они обе корректны и обе полностью согласованы с поведением этих ф-й. По-этому выбор конкретной интерпретации — это произвол, какую захочется, ту и выбираете. Нет никаких причин, по которым одна из этих интерпретаций в каком-то смысле "неверна", они обе одинаково "верны". Это просто две разные математически модели, которыми вы описываете один объект.
Почему идея о том что один и тот же объект можно описать двумя разными мат. моделями (сформулировать семантики разного типа для одного ЯП) вызывает у вас такое непонимание?
Пример с фортом вы не прочитали? Вроде, по нему должно быть ну совсем все очевидно.
А можно — как "композиция ф-й Stack -> Stack", никаких сайд-эффектов, чистая функциональщина.
Можно предложить разделение на формально-функциональную и функциональную по духу программу.
Последняя отличается тем, что там не используются модели состояний, которые не нужны в предметной области. Например, для сложения двух чисел не нужно понятие стека. Можно написать в state monad эмулятор программы на форте вычисляющей математическое выражение и программа будет формально функциональной, но не функциональной по духу.
Прок от формальной функциональности в том, что императивный стековый мирок там будет изолирован.
Так а какая разница?
Разница в том, что автор считает чисто функциональной программу в которой есть одно гигантское определение чистой функции внутри которого грязный код
Нет содержательного способа отличить чистую функцию от грязной, об этом речь.
Я не очень понимаю, что такое "содержательный способ" в данном случае. В моем представлении речь идет о том из кусков какого типа мы составляем программу — то есть о форме записи алгоритма.
Если является — то грязных функций не существует, т.к. любую грязную ф-ю в любом языке можно рассматривать как функцию, возвращающую ИО.
Речь идет о способе выражения программы. В тот момент как мы представляем функцию, возвращающую IO мы мысленно делаем эквивалентную функциональную программу. Мы можем мысленно перевести практически все с русского на английский, это не означает что английский и русский, это одинаковые языки. Или что запись длины в дюймах то же самое, что запись длины в сантиметрах. Или что полярные координаты это то же самое что и декартовы.
Мы можем, конечно, себя ограничить и написать формально чисто функциональную программу написанную в императивном стиле, как допустим, мы можем написать объектно ориентированный эмулятор оборудования на C# и писать все на нем (типа processor.Registers.Ax.Move(processor.Registers.Bx)). Но тогда у нас, по крайней мере, будет способ заводить новые чистые функции и они будут отделены от IO/RealWorld.
Что вы подразумеваете под "чистой ф-ей" в данном случае?
"В языках программирования, чистая функция, это функция, которая:
- является детерминированной;
- не обладает побочными эффектами"
Т.о., само понятие оказывается бессодержательным — т.к. либо абсолютно все полезные программы функциональны, либо нет, с-но, отделять друг от друга нечего.
Так же можно заявлять что ООП понятие оказывается бессодержательным и таковых программ не существует в природе. Ибо любая программа транслитерируется, в конечном счете, в более низкое, машинное представление в котором нет места таким абстракциям как объекты. Мы живем в иллюзорном мире.
Предельно понятно выражен смысл чистой функции.
Еще мысль — можем ли мы договориться считать сайд эффект здесь ненаблюдаемым, как допустим изменение температуры ЦП в результате выполнения функции.
int Factorial(int n)
{
Log.Info($"Computing factorial of {n}");
return Enumerable.Range(1, n).Aggregate((x, y) => x * y);
}Как если мы запретим другим частям программы, например, читать этот лог, но мы получим ссылочную прозрачность и можем считать эту функцию чистой.
Да, это есть в примечании в статье сразу после определения ссылочной прозрачности) Там, где я предлагаю этот вариант не рассматривать по разумным причинам.
Требование может звучать следующим образом:
Программа обязана вывести в лог строчку "Computing factorial of {n}", где{n}— некоторое число, каждый раз когда она начинает вычислять факториал числа{n}.
Если это не выражено в типах, значит программист неправильно запрограммировал требования, о чем и говорит qw1
считать сайд эффект здесь ненаблюдаемым
Иммутабельность, комбинаторы, замыкания, рекурсия вместо циклов, каррирование, из того, о чём обычно вещают.
Каррирование программист делает сам
Так, функция, принимающая кортеж — это тоже, в некотором роде, функция нескольких параметров — при этом определение такой функции ничуть не сложнее определения каррированной функции.
add1 a b = a+b
add2 (a, b) = a+b
Замыкания — это такие вложенные функции, их необходимость неочевидна.
Если рекурсию заменить циклом, то логика программы от этого не пострадает.
Сборка мусора тоже для удобства.
Монад и моноидов в Лиспе вроде не было(?).
В качестве грязного рантайма в Схеме (Scheme) используется функция bing-bang (бесконечный loop).
Т.е. ФП — это иммутабельность, комбинаторы (лямбды), бесконечный loop для грязного рантайма, так?
Замыкания — это такие вложенные функции, их необходимость неочевидна.
очевидно, если Вы писали промышленный код и использовали сторонние библиотеки.
Если рекурсию заменить циклом, то логика программы от этого не пострадает.
любую ли рекурсию можно заменить циклом? Концевую — да. А если qsort какой-нибудь? Попробуйте это переписать без рекурсии, чтобы это хотя бы было читабельным и поддерживаемым кодом.
И вообще поясните, пожалуйста, — Вы собственно что хотите сказать?
любую ли рекурсию можно заменить циклом? Концевую — да. А если qsort какой-нибудь? Попробуйте это переписать без рекурсии, чтобы это хотя бы было читабельным и поддерживаемым кодом.
В теории любой цикл можно переписать в рекурсию и наоборот, это сильный тезис Чёрча. Другой вопрос, что вы часто не захотите так делать. Как вы например на захотите проверить тезис "на ассемблере можно написать точную копию Windows 10".
Каррирование программист делает сам
Непонятно, что имелось в виду. Каррирование это способ записи. И не все языки его разрешают. Например, в си или джаве каррирования нет.
Замыкания — это такие вложенные функции, их необходимость неочевидна.
Необходимость чего-либо — вещь спорная. Нужны ли циклы? Можно же просто goto на метку писать.
Если рекурсию заменить циклом, то логика программы от этого не пострадает.
Обычно как раз страдает. Например, обход дерева в рекурсивном варианте куда логичнее и естественнее чем вариант на циклах.
Сборка мусора тоже для удобства.
В теории да, на практике же ФП язык без ГЦ сейчас это такой блидинг эдж, по сравнению с которым идрис — промышленный язык, а хаскель — легаси.
Монад и моноидов в Лиспе вроде не было(?).
Так "Лисп — ФП" один из самых устойчивых, но мифов.
Что такео ФП на мой взгляд я написал — ссылочная прозрачность. Иммутабельность не обязательна, в хаскелле вон на линейных типах сделали вполне себе мутабельный хэшмап. Лямбды — смотря что под ними понимать, всегда можно объявлять топ-левел функции и прокидывать структуру замыкания дополнительным аргументом. При чем тут бесконечный loop я так и не понял, как ни старался.
В теории да, на практике же ФП язык без ГЦ сейчас это такой блидинг эдж, по сравнению с которым идрис — промышленный язык, а хаскель — легаси.
Вот это, кстати, интересно. Неужели для такого "продвинутого" способа вычислений на удалось найти более изящный способ управления памятью?
Стоит посмотреть с какими трудностями столкнулись в расте когда думали как бы им монады сделать.
Это лишь монады, базовый конструкт. Про какие-нибудь rank2 polymorphism и прочие продвинутые штуки даже речи не идёт.
Не, конечно можно обтянуть аллокации в отдельную монаду, наверное оно даже будет как-то работать. Но нужно понимать, что кроме теоретической возможности нужна прикладная практичность. А вот её пока нет кроме как с гц.
Я думаю, что весь секрет в ленивости вычислений — она же дает космическую эффективность. Реализуйте ее без GC и поддержки со стороны рантайма. Сможете? Сильно сомневаюсь. Я уж не говорю о том, что объекты языка — далеко не просто int32 и прочие POD'ы
Непонятно, что имелось в виду.
https://habr.com/ru/post/249241/#comment_8252293
Как бы рекурсию компилятор/интерпретатор переводят в цикл.
Вызов подпрограммы на асме можно делать рекурсивно (тут мне надо более детально разбираться).
В Схеме для циклов используется let
Лямбды
Я имел в виду, что функциональность реализуется на комбинаторах (композиция) и лямбдах (как вариант).
прокидывать структуру замыкания дополнительным аргументом
эээ, может в статье напишите, как это реализуется?
А в ФП циклы вообще используются?
а какие аргументы за циклы? Если у Вас нет связи между итерациями цикла — лучше взять map() — он параллелится. Если же есть — это reduce() (например, посчитай сумму всех элементов). В остальном — циклы — почему нет ?
В scala есть scala.collection.Iterator.sliding
Циклы все равно будут переписаны в рекурсию, так же, как TCO переписывает рекурсию в циклы — базовые примитивы в языке такие.
Что до методов — то на итераторах/списках всегда есть подходящие методы, в крайнем случае, всегда можно сделать map/fold на (0..n) и получить тот же цикл.
Подобные алгоритмы без особых проблем переписываются на fold (reduce), причем если компилятор обучен извлекать выгоду из линейных типов — то это будет даже работать с той же скоростью. А если не обучен — ну, понадобится foldM.
эээ, может в статье напишите, как это реализуется?
Да ничего сложного, можно посмотреть как компилятор какого-нибудь сишарпа генерирует замыкание, это просто структура с функцией. В структуру пихается всё, что нужно лямбде, а функция принимает this и получает доступ ко всей этой информации.
"Объекты это замыкания для бедных".
Не слышал, хорошее выражение, надо запомнить )
Это пролог к <<Ken Dickey, "Scheming with Objects", AI Expert 7(10):24-33, October 1992>>
There is a saying--attributed to Norman Adams--that "Objects are a
poor man's closures." In this article we discuss what closures are and
how objects and closures are related, show code samples to make these
abstract ideas concrete, and implement a Scheme Object System which
solves the problems we uncover along the way.
Да ничего сложного
Спасибо
Можем. Собственно, пример это и демонстрировал: что фп это не fancy дата трансформеры и прочее, а отсутсвие сайдэффектов. Если сделать как вы хотите то так и получится, примеры с циклом и LINQ просто подчеркивают поинт статьи.
К слову, это не означает что чистые функции нельзя логгировать, просто это должно быть обычным эффектом, а не сайд эффектом. Обычный — это тот, который в типах виден. Из стандартных дотнет эффектов есть Nullable или Task.
Примерно так могло бы выглядеть в чистом виде:
Logged<int> Factorial(int n)
{
return Log.Info($"Computing factorial of {n}").Map(() =>
Enumerable.Range(1, n).Aggregate((x, y) => x * y));
}К слову, это не означает что чистые функции нельзя логгировать, просто это должно быть обычным эффектом, а не сайд эффектом
А можно сделать гораздо проще — не считать логирование сайд-эффектом, так же как мы не считаем сайд-эффектом потребление памяти, нагревание процессора и т.д.
Можно и так, только если у нас не будет логгироваться функция (кроме скажем первого вызова) то наверное для нас это будет проблемой. Ведь на сайдэффекты нельзя рассчитывать. Какой-нибудь хачкель с удовольствием закэширует вызов такого Factorial и не будет логгировать ничгео кроме первого вызова
Ну и чудесно. Лично мне интересно видеть в логе строчку "Computing factorial of {n}" только тогда, когда он реально вычисляется, но никак не когда используется кешированное значение.
Как угодно, whatever works for you как говорится.
Правда тут теряются все плюсы по автоматическому батчингу/буферизации запросов на логгирование например, и прочие бенефиты от разделения факта логгирования с его непосредственной интерпретацией, но как хотите так собственно и делайте.
А так можно было бы использовать логи по назначению: сюда пришли, всё выполняется как ожидалось, а сюда уже не пришли, значит, упало/зависло где-то между точками логирования.
Ну у меня сейчас как раз обратная проблема — синхронное логггирование без батчинка просто рпс роняет в 10 раз (60к вместо 600к). Зато ничего не теряем, да, всё пишем в стдаут. Пробовали по сети писать — стало только хуже.
А вообще — проблема аналогий всегда в том, что они неточны. Если я начну про MonadSqlBackend m рассказывать и реалистичную обработку эффектов вы меня нафиг пошлете. Решил показать что-то +- реалистичное, что можно встретить в коде.В идеале были бы асинки, но как раз их принято в шарпе декорировать эффектом явно, за async void почти всегда разработчика обижают.
Ну и ваш пример — не проблема, запишется так же как записалось бы в другом случае. Единственный реалистичный кейс — это если мы накопили запись для логгирования, собрались писать — а приложения прибили и логи потерялись. Это да, возможный сценарий, но как я говорил — это одна из опций. Мы вот её рассматриваем потому что перфоманс слишком сильно страдает при синхронном записывании.
А ещё у нас был момент где всунутый не туда лог ронял приложение по ООМ: логи в горячем месте копились быстрее, чем отсылались, в итоге выжирали 3 гига памяти и у приложение заканчивался юзерспейс. Если бы лог был эффектом то ошибка компиляции в горячей чистой функции дала бы шанс заметить это до того как это попало в прод.
Функциональное программирование — это не то, что нам рассказывают