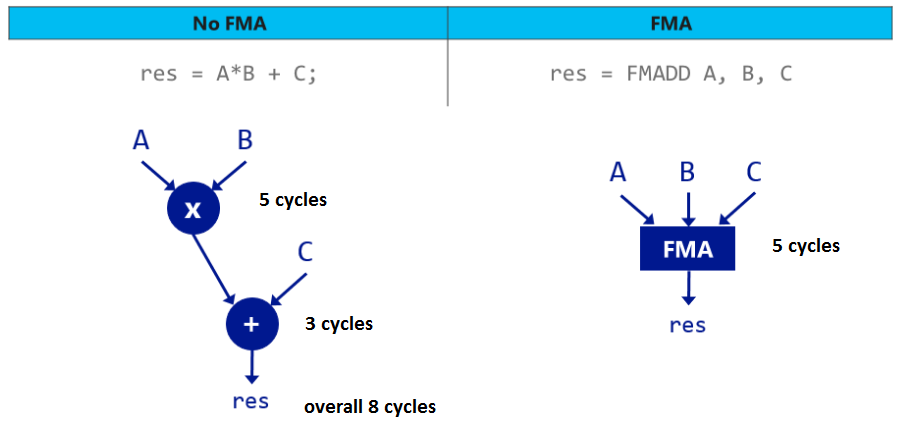
Приятно видеть знакомые фамилии в списке Acknowledgments официального релиза PostgreSQL 12. Мы решили свести вместе попавшие в релиз новшества и некоторые багфиксы, над которыми трудились наши разработчики.
1. Поддержка JSONPath
(В
Release Notes это звучит как
Add support for the SQL/JSON path language (Nikita Glukhov, Teodor Sigaev, Alexander Korotkov, Oleg Bartunov, Liudmila Mantrova)
Сам этот патч, возможности JSONPath и история вопроса обсуждались в деталях
в отдельной статье здесь на хабре. JSONPath — серьезное достижение Postgres Professional и одно из главных новшеств PostgreSQL 12 вообще.
В 2014 году А.Коротковым, О.Бартуновым и Ф.Сигаевым было разработано расширение
jsquery, вошедшее в результате в версию Postgres Pro Standard 9.5 (и в более поздние версии Standard и Enterprise). Оно дает дополнительные, очень широкие возможности для работы с json(b).
Когда появился стандарт SQL:2016, оказалось, что его семантика не так уж сильно отличается от нашей в расширении jsquery. Не исключено, что авторы стандарта даже поглядывали на jsquery, изобретая JSONPath. Нашей команде пришлось реализовывать немного по-другому то, что у нас уже было и, конечно, много нового тоже.
Хотя специальный патч с функциями до сих пор не закоммичен, в патче JSONPath уже есть ключевые функции для работы с JSON(B), например:
jsonb_path_query('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 2)') возвращает 3, 4, 5
jsonb_path_query('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 5)') возвращает 0 записей
Кроме того,
были оптимизированы и некоторые функции, которые уже работали с JSON раньше. Этим успешно занимался Никита Глухов.
Например, оператор
#>>, соответствующий функциям
jsonb_each_text() и
jsonb_array_elements_text(), раньше достаточно быстро преобразовывал JsonbValue в text, но работал неторопливо с другими типами. Сейчас всё работает быстро.