
Всем, доброго времени суток.
По сути, к реализации этой маленькой автоматизации меня сподвигла лень.
Собственно, с чего все началось.
У меня есть ноутбук с установленной gentoo, и i3wm оконным менеджером. Так же есть несколько мониторов(дома, на работе и т д). Разрешения на всех мониторах разные, способы подключения тоже (VGA, HDMI, DVI) разные. Активно, использую первые два.
Раньше, при подключении второго монитора, приходилось вызывать команды, которые инициализировали этот самый монитор. Запуск команды с автоматическим ключом, не всегда давал, желаемого результата(не угадывал разрешение).
xrandr --auto
Потому, приходилось запускать эту же команду, но с набором других ключей, разрешение например.
--mode И хотя, в xrandr для каждого монитора у меня есть несколько вариантов разрешений, есть одно (максимальное для данного монитора, которое удовлетворяет), но на каждом мониторе оно разное(так как сами мониторы разные).
Потому пришлось искать решение…





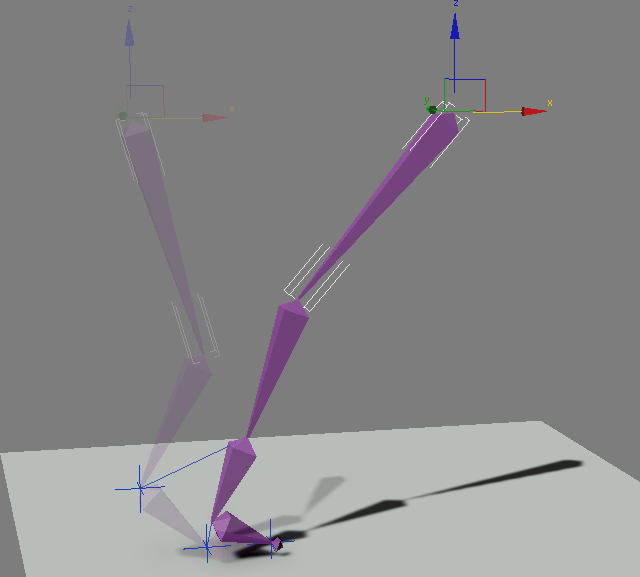 Что такое «Инверсная кинематика»?
Что такое «Инверсная кинематика»? Поскольку побеждать
Поскольку побеждать 
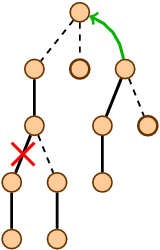 Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы.
Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы. 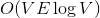 и
и 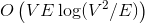 соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.
соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.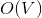 памяти и
памяти и 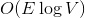 времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.
времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.