Для мониторинга IT-инфраструктуры мы используем множество инструментов, в том числе:
Можно долго обсуждать преимущества/недостатки тех или иных систем мониторинга, но я хочу остановиться только на одном вопросе — выявлении аномалий. Когда в вашей системе мониторинга количество метрик измеряется сотнями, отследить аномальное поведение одной или нескольких из них не составляет труда. Но когда количество метрик измеряется десятками или сотнями тысяч, вопрос автоматического выявления аномалий становится актуальным. Ни один администратор или группа администраторов не в состоянии вручную отследить поведение сложной системы, состоящей из сотен устройств.
Инженеры из Etsy в свое время столкнулись с этой проблемой и разработали свой инструмент для обнаружения и корреляции аномалий. Называется он Kale и состоит из двух частей:
Рассмотрим каждую из частей подробней.
Skyline – это система обнаружения аномалий в реальном времени. Она создана для того, чтобы проводить пассивное наблюдение за сотнями тысяч метрик, без необходимости настраивать пороги для каждой из них. Это означает, что вам не нужно вручную выставлять пороги срабатывания триггеров в вашей системе мониторинга – система автоматически анализирует поступающие в нее данные и на основании нескольких алгоритмов, встроенных в нее, принимает решение об «аномальности» этих данных.
Skyline состоит из нескольких компонент.
Horizon — это компонент, который отвечает за сбор данных. Он принимает данные в двух форматах: pickle (TCP) и MessagePack (UDP).
Таким образом, можно настроить следующую цепочку: система мониторинга шлет данные в формате «имя_метрики временной_штамп значение» в Graphite. Со стороны графита работает carbon-relay, который пересылает данные в формате pickle в Horizon. Далее, после получения данных, Horizon обрабатывает их, кодирует с помощью MessagePack и отправляет в Redis. Или можно донастроить систему мониторинга, чтобы она слала данные в Horizon напрямую, предварительно кодируя их в формат MessagePack. К тому же, большинство языков современных языков программирования имеют модули для работы с MessagePack.
Также, Horizon регулярно обрезает и очищает старые метрики. Если этого не делать, то вся свободная память в скором времени исчерпается.
В настройках также можно указать список метрик, которые будут игнорироваться.
Redis — это отдельный компонент, но без него Skyline работать не будет. В нем он хранит все метрики и закодированные временные ряды.
У этого решения есть свои преимущества и недостатки. С одной стороны, Redis имеет высокую производительность обусловленную тем, что все данные хранятся в оперативной памяти. Данные хранятся в виде «ключ — значение», где ключ — это имя метрики, а значение — соответствующий ей закодированный временной ряд. С другой стороны, Redis плохо справляется с очень длинными строками. Чем длинней строка тем меньше производительность. Как показала практика, хранить данные более, чем за день/два смысла не имеет. В большинстве систем данные имеют часовую, дневную, недельную и месячную периодичность. Но если хранить данные за несколько недель или месяцев, производительность Redis будет крайне низкой. Для решения этого вопроса можно воспользоваться альтернативными методами хранения временных рядов, например, используя библиотеку redis-timeseries или что-нибудь подобное.
Analyzer — этот компонент отвечает за анализ данных. Он получает общий список метрик из Redis-а, и запускает несколько процессов, каждому из которых назначает свои метрики. Каждый из процессов анализирует данные, используя несколько алгоритмов. Один за другим алгоритмы анализируют метрики и сообщают результат — аномальна метрика или нет. Если большинство из них сообщает, что в текущий момент метрика имеет аномалию, то она считается аномальной. Если «проголосовал» только один или несколько алгоритмов, то аномалия не засчитывается. В настройках можно указать порог — количество алгоритмов, которые должны сработать перед тем, как метрика классифицируется аномальной. По умолчанию он равен 6.
На данный момент реализованы следующие алгоритмы:
Большинство из них основано на контрольных картах и на правиле трех сигм. О принципе работы некоторых алгоритмов вы можете узнать из докладов, видео которых размещено в конце этой статьи. Также хочу посоветовать ознакомится с материалами блога Антона Лебедевича — mabrek.github.io. Он также вносит свой вклад в развитие Skyline.
Алгоритмы можно настраивать под себя, изменять, удалять или добавлять новые. Все они собраны в одном файле algorithms.py. В своих расчетах они используют библиотеки SciPy и NumPy. О последней есть неплохая статья на хабре.
Кроме аномальных, в результате анализа данных могут назначаться также следующие статусы:
Все аномальные метрики попадают в файл, на основании данных из которого формируется картинка в веб-приложении.
Analyzer также может отправлять уведомления. В качестве целей в данный момент доступны: почта, HipChat и PagerDuty.
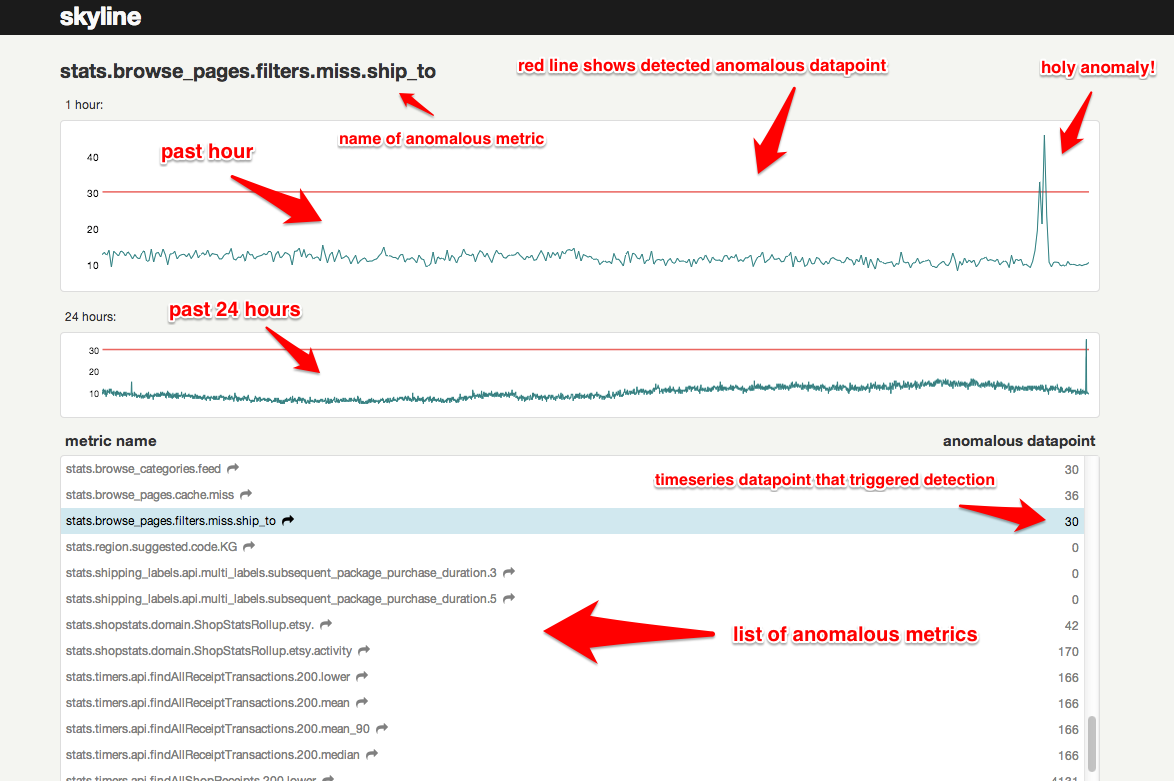
Для отображения аномальных метрик используется небольшое веб-приложение, написанное на Python с использованием фреймворка Flask. Оно предельно простое: в верхней части отображаются два графика — за прошедший час и день. Внизу под графиками расположен список всех аномальных метрик. При наведении курсора на одну из метрик картинка на графиках меняется. При клике открывается окно Oculus, о котором и пойдет речь дальше.
Oculus служит для поиска корреляции аномалий и работает в связке со Skyline. Когда Skyline находит аномалию и отображает ее в своем веб-интерфейсе, мы можем кликнуть по названию аномальной метрики и Oculus нам покажет все метрики, которые коррелируют с исходной.

Вкратце алгоритм поиска можно описать следующим образом. Вначале исходный ряд значений, например, ряд вида [960, 350, 350, 432, 390, 76, 105, 715, 715], нормализуется: ищется максимум — ему будет соответствовать 25, и минимум — ему будет соответствовать 0; таким образом, данные пропорционально распределяются в пределе целых чисел от 0 до 25. В итоге мы получаем ряд вида [25, 8, 8, 10, 9, 0, 1, 18, 18]. Затем нормализованный ряд кодируется с помощью 5 слов: sdec (резко вниз), dec (вниз), s (ровно), inc (вверх), sinc (резко вверх). В итоге получается ряд вида [sdec, flat, inc, dec, sdec, inc, sinc, flat].
Затем с помощью ElasticSearch происходит поиск всех метрик, по форме похожих на исходную. Данные в ElasticSearch хранятся в виде:
Сначала производится поиск по fingerprint. В результате получается выборка, количество метрик в которой на порядок меньше, чем общее количество. Далее для анализа применяется алгоритм быстрого динамического трансформирования времени (FastDTW), который использует значения values. Про алгоритм FastDTW есть хорошая статья.
В результате мы получаем данные всех найденных метрик, которые коррелируют с исходной.
Для импорта данных из Redis используются скрипты, написанные на Ruby. Они забирают все метрики с префиксом «mini», декодируют их, нормализуют и экспортируют в ElasticSearch. Во время обновления и индексирования скорость поиска ElasticSearch уменьшается. Поэтому, чтобы долго не ждать результатов, используется два сервера ElasticSearch в отдельных кластерах, между которыми Oculus регулярно переключается.
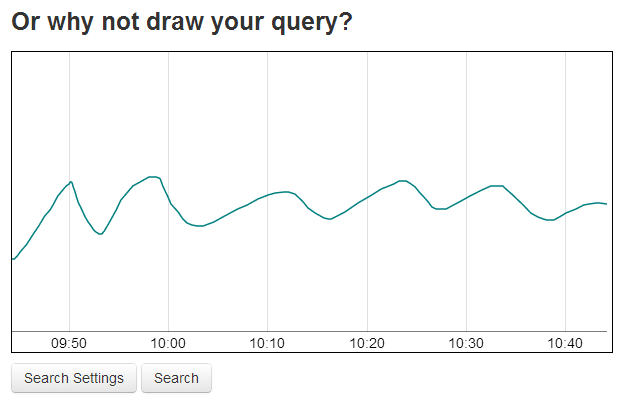
Для поиска и отображения графиков используется веб приложение которое использует фреймворк Sinatra. Поиск можно проводить как по названию метрики, так и просто нарисовав в специальном поле кривую:
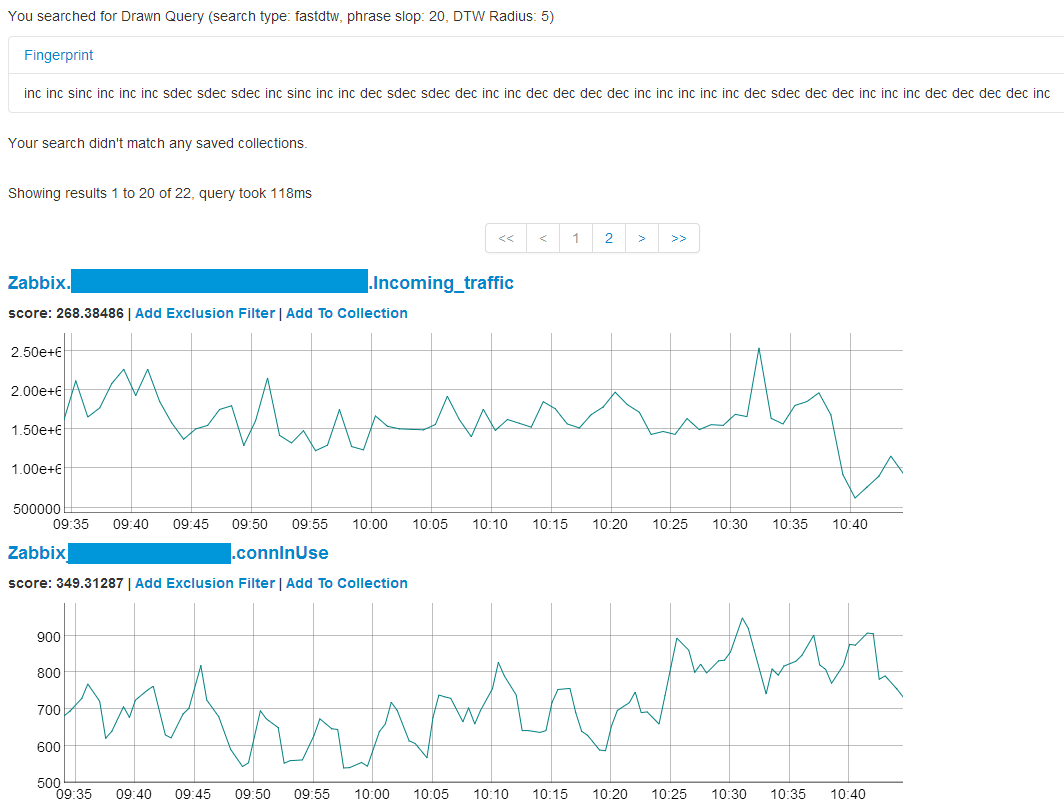
В результате мы увидим страницу, на которой отобразится:
Данные можно отфильтровать, а также сгруппировать в коллекцию, дать им описание и сохранить в памяти. Коллекции используются в следующих случаях. Допустим, мы выявили некоторую аномалию и получили список графиков, подтверждающих это явление. Удобно будет сохранить эти графики и дать им подробное описание. Теперь, когда похожая проблема случится в будущем, Oculus найдет нам эту коллекцию и написанное ранее описание поможет нам разобраться в причинах и способах устранения выявленной проблемы.
На рисунке ниже приведена схема работы Kale:

Я не буду описывать процесс установки и настройки, так как он не очень сложен и указан в документации Skyline и Oculus.
В настоящий момент мы запустили систему в тестовом режиме — все компоненты работают на одной виртуальной машине. Но даже при довольно слабой конфигурации (Intel Xeon E5440, 8 Gb RAM) система без проблем анализирует более одного десятка тысяч метрик в реальном времени. Основная сложность в эксплуатации — это настройка параметров выявления аномалий. Ошибок второго рода (false negatives) пока не возникало, а вот с ошибками первого рода (false positives) мы регулярно встречаемся и стараемся настроить алгоритмы под свои нужды. Основная проблема — это сезонность данных. Существует метод Холта-Винтерса, который учитывает сезонность, но у него есть ряд недостатков:
Так что вопрос разработки алгоритмов выявления аномалий, в особенности, с учетом сезонных данных, остается открытым.
github.com/etsy/skyline
github.com/etsy/skyline/wiki
https://groups.google.com/forum/#!forum/skyline-dev
github.com/etsy/oculus
mabrek.github.io
На видео представлено выступление Эйба Стенвея (Abe Stanway), разработчика Kale.
Доклад Джона Коуи (Jon Cowie) и Эйба Стенвея (Abe Stanway) на конференции Velocity, в котором они рассказывают о своем детище —
Вторая часть выступления.
Доклад Антона Лебедевича «Статистика на практике для поиска аномалий в нагрузочном тестировании и production»
- Zabbix — о нем написано немало статей здесь на хабре. Нам очень нравятся его возможности низкоуровневого обнаружения, но его возможности визуализации данных оставляют желать лучшего.
- Graphite — система, которая хранит данные и имеет удобный интерфейс для их отображения. Сейчас мы импортируем в нее метрики из Zabbix и храним историю.
- Shinken — система мониторинга, которая основана на Nagios и написана на языке Python. Сейчас мы присматриваемся к ней. Нам нравится то, что в нее очень просто импортировать данные из системы документации сети Netdot (о ней я уже писал ранее), а также она легко интегрируется с Graphite.
Можно долго обсуждать преимущества/недостатки тех или иных систем мониторинга, но я хочу остановиться только на одном вопросе — выявлении аномалий. Когда в вашей системе мониторинга количество метрик измеряется сотнями, отследить аномальное поведение одной или нескольких из них не составляет труда. Но когда количество метрик измеряется десятками или сотнями тысяч, вопрос автоматического выявления аномалий становится актуальным. Ни один администратор или группа администраторов не в состоянии вручную отследить поведение сложной системы, состоящей из сотен устройств.
Инженеры из Etsy в свое время столкнулись с этой проблемой и разработали свой инструмент для обнаружения и корреляции аномалий. Называется он Kale и состоит из двух частей:
Рассмотрим каждую из частей подробней.
Skyline
Skyline – это система обнаружения аномалий в реальном времени. Она создана для того, чтобы проводить пассивное наблюдение за сотнями тысяч метрик, без необходимости настраивать пороги для каждой из них. Это означает, что вам не нужно вручную выставлять пороги срабатывания триггеров в вашей системе мониторинга – система автоматически анализирует поступающие в нее данные и на основании нескольких алгоритмов, встроенных в нее, принимает решение об «аномальности» этих данных.
Skyline состоит из нескольких компонент.
Horizon
Horizon — это компонент, который отвечает за сбор данных. Он принимает данные в двух форматах: pickle (TCP) и MessagePack (UDP).
Таким образом, можно настроить следующую цепочку: система мониторинга шлет данные в формате «имя_метрики временной_штамп значение» в Graphite. Со стороны графита работает carbon-relay, который пересылает данные в формате pickle в Horizon. Далее, после получения данных, Horizon обрабатывает их, кодирует с помощью MessagePack и отправляет в Redis. Или можно донастроить систему мониторинга, чтобы она слала данные в Horizon напрямую, предварительно кодируя их в формат MessagePack. К тому же, большинство языков современных языков программирования имеют модули для работы с MessagePack.
Также, Horizon регулярно обрезает и очищает старые метрики. Если этого не делать, то вся свободная память в скором времени исчерпается.
В настройках также можно указать список метрик, которые будут игнорироваться.
Redis
Redis — это отдельный компонент, но без него Skyline работать не будет. В нем он хранит все метрики и закодированные временные ряды.
У этого решения есть свои преимущества и недостатки. С одной стороны, Redis имеет высокую производительность обусловленную тем, что все данные хранятся в оперативной памяти. Данные хранятся в виде «ключ — значение», где ключ — это имя метрики, а значение — соответствующий ей закодированный временной ряд. С другой стороны, Redis плохо справляется с очень длинными строками. Чем длинней строка тем меньше производительность. Как показала практика, хранить данные более, чем за день/два смысла не имеет. В большинстве систем данные имеют часовую, дневную, недельную и месячную периодичность. Но если хранить данные за несколько недель или месяцев, производительность Redis будет крайне низкой. Для решения этого вопроса можно воспользоваться альтернативными методами хранения временных рядов, например, используя библиотеку redis-timeseries или что-нибудь подобное.
Analyzer
Analyzer — этот компонент отвечает за анализ данных. Он получает общий список метрик из Redis-а, и запускает несколько процессов, каждому из которых назначает свои метрики. Каждый из процессов анализирует данные, используя несколько алгоритмов. Один за другим алгоритмы анализируют метрики и сообщают результат — аномальна метрика или нет. Если большинство из них сообщает, что в текущий момент метрика имеет аномалию, то она считается аномальной. Если «проголосовал» только один или несколько алгоритмов, то аномалия не засчитывается. В настройках можно указать порог — количество алгоритмов, которые должны сработать перед тем, как метрика классифицируется аномальной. По умолчанию он равен 6.
На данный момент реализованы следующие алгоритмы:
- среднее отклонение (mean absolute deviation);
- тест Граббса (Grubbs' test);
- среднее за первый час (first hour average);
- среднеквадратическое отклонение от средней (standard deviation from average);
- среднеквадратическое отклонение от скользящей средней (standard deviation from moving average);
- метод наименьших квадратов (least squares);
- выбросы на гистограмме(histogram bins);
- критерий согласия Колмогорова (K–S test).
Большинство из них основано на контрольных картах и на правиле трех сигм. О принципе работы некоторых алгоритмов вы можете узнать из докладов, видео которых размещено в конце этой статьи. Также хочу посоветовать ознакомится с материалами блога Антона Лебедевича — mabrek.github.io. Он также вносит свой вклад в развитие Skyline.
Алгоритмы можно настраивать под себя, изменять, удалять или добавлять новые. Все они собраны в одном файле algorithms.py. В своих расчетах они используют библиотеки SciPy и NumPy. О последней есть неплохая статья на хабре.
Кроме аномальных, в результате анализа данных могут назначаться также следующие статусы:
- TooShort: временной ряд слишком короткий чтобы делать какие-либо выводы;
- Incomplete: длина временного ряда в секундах меньше заданного в настройках полного периода (как правило, 86400 с);
- Stale: временной ряд давно не обновлялся (время в секундах задается в настройках);
- Boring: значения временного ряда не изменялись в течении некоторого времени (задается в настройках);
Все аномальные метрики попадают в файл, на основании данных из которого формируется картинка в веб-приложении.
Analyzer также может отправлять уведомления. В качестве целей в данный момент доступны: почта, HipChat и PagerDuty.
Flask webapp
Для отображения аномальных метрик используется небольшое веб-приложение, написанное на Python с использованием фреймворка Flask. Оно предельно простое: в верхней части отображаются два графика — за прошедший час и день. Внизу под графиками расположен список всех аномальных метрик. При наведении курсора на одну из метрик картинка на графиках меняется. При клике открывается окно Oculus, о котором и пойдет речь дальше.
Oculus
Oculus служит для поиска корреляции аномалий и работает в связке со Skyline. Когда Skyline находит аномалию и отображает ее в своем веб-интерфейсе, мы можем кликнуть по названию аномальной метрики и Oculus нам покажет все метрики, которые коррелируют с исходной.
Вкратце алгоритм поиска можно описать следующим образом. Вначале исходный ряд значений, например, ряд вида [960, 350, 350, 432, 390, 76, 105, 715, 715], нормализуется: ищется максимум — ему будет соответствовать 25, и минимум — ему будет соответствовать 0; таким образом, данные пропорционально распределяются в пределе целых чисел от 0 до 25. В итоге мы получаем ряд вида [25, 8, 8, 10, 9, 0, 1, 18, 18]. Затем нормализованный ряд кодируется с помощью 5 слов: sdec (резко вниз), dec (вниз), s (ровно), inc (вверх), sinc (резко вверх). В итоге получается ряд вида [sdec, flat, inc, dec, sdec, inc, sinc, flat].
Затем с помощью ElasticSearch происходит поиск всех метрик, по форме похожих на исходную. Данные в ElasticSearch хранятся в виде:
{
fingerprint: dec sinc dec sdec dec sdec sinc
values: 13.18 12.72 14.8 14.43 12.95 12.13 6.87 9.67
id: mini.Shinken_server.shinken.CPU_Stats.cpu_all_sys
}
Сначала производится поиск по fingerprint. В результате получается выборка, количество метрик в которой на порядок меньше, чем общее количество. Далее для анализа применяется алгоритм быстрого динамического трансформирования времени (FastDTW), который использует значения values. Про алгоритм FastDTW есть хорошая статья.
В результате мы получаем данные всех найденных метрик, которые коррелируют с исходной.
Для импорта данных из Redis используются скрипты, написанные на Ruby. Они забирают все метрики с префиксом «mini», декодируют их, нормализуют и экспортируют в ElasticSearch. Во время обновления и индексирования скорость поиска ElasticSearch уменьшается. Поэтому, чтобы долго не ждать результатов, используется два сервера ElasticSearch в отдельных кластерах, между которыми Oculus регулярно переключается.
Для поиска и отображения графиков используется веб приложение которое использует фреймворк Sinatra. Поиск можно проводить как по названию метрики, так и просто нарисовав в специальном поле кривую:
В результате мы увидим страницу, на которой отобразится:
- информация о параметрах поиска;
- закодированное представление исходного графика;
- список коллекций (о них ниже), в случае, если данные коррелируют с сохраненными ранее данными;
- список найденных графиков, отсортированных по возрастанию оценки корреляции (чем меньше оценка, тем больше данные коррелируют).
Данные можно отфильтровать, а также сгруппировать в коллекцию, дать им описание и сохранить в памяти. Коллекции используются в следующих случаях. Допустим, мы выявили некоторую аномалию и получили список графиков, подтверждающих это явление. Удобно будет сохранить эти графики и дать им подробное описание. Теперь, когда похожая проблема случится в будущем, Oculus найдет нам эту коллекцию и написанное ранее описание поможет нам разобраться в причинах и способах устранения выявленной проблемы.
На рисунке ниже приведена схема работы Kale:
Я не буду описывать процесс установки и настройки, так как он не очень сложен и указан в документации Skyline и Oculus.
В настоящий момент мы запустили систему в тестовом режиме — все компоненты работают на одной виртуальной машине. Но даже при довольно слабой конфигурации (Intel Xeon E5440, 8 Gb RAM) система без проблем анализирует более одного десятка тысяч метрик в реальном времени. Основная сложность в эксплуатации — это настройка параметров выявления аномалий. Ошибок второго рода (false negatives) пока не возникало, а вот с ошибками первого рода (false positives) мы регулярно встречаемся и стараемся настроить алгоритмы под свои нужды. Основная проблема — это сезонность данных. Существует метод Холта-Винтерса, который учитывает сезонность, но у него есть ряд недостатков:
- учитывается только один сезон (в реальных данных может быть более одного сезона — час, день, неделя, год);
- необходимо большее количество данных за несколько сезонов (поэтому этот метод неприменим в Skyline — размер строк в базе Redis будет слишком большим);
- в случае аномалии, она будет учитываться в будущих сезонах с постепенным затуханием;
Так что вопрос разработки алгоритмов выявления аномалий, в особенности, с учетом сезонных данных, остается открытым.
Ссылки
github.com/etsy/skyline
github.com/etsy/skyline/wiki
https://groups.google.com/forum/#!forum/skyline-dev
github.com/etsy/oculus
mabrek.github.io
Видео
На видео представлено выступление Эйба Стенвея (Abe Stanway), разработчика Kale.
Доклад Джона Коуи (Jon Cowie) и Эйба Стенвея (Abe Stanway) на конференции Velocity, в котором они рассказывают о своем детище —
Вторая часть выступления.
Доклад Антона Лебедевича «Статистика на практике для поиска аномалий в нагрузочном тестировании и production»
