Интересные алгоритмы кластеризации, часть первая: Affinity propagation
11 мин
Часть первая — Affinity Propagation
Часть вторая — DBSCAN
Часть третья — кластеризация временных рядов
Часть четвёртая — Self-Organizing Maps (SOM)
Часть пятая — Growing Neural Gas (GNG)
Если вы спросите начинающего аналитика данных, какие он знает методы классификации, вам наверняка перечислят довольно приличный список: статистика, деревья, SVM, нейронные сети… Но если спросить про методы кластеризации, в ответ вы скорее всего получите уверенное «k-means же!» Именно этот золотой молоток рассматривают на всех курсах машинного обучения. Часто дело даже не доходит до его модификаций (k-medians) или связно-графовых методов.
Не то чтобы k-means так уж плох, но его результат почти всегда дёшев и сердит. Есть более совершенные способы кластеризации, но не все знают, какой когда следует применять, и очень немногие понимают, как они работают. Я бы хотел приоткрыть завесу тайны над некоторыми алгоритмами. Начнём с Affinity propagation.
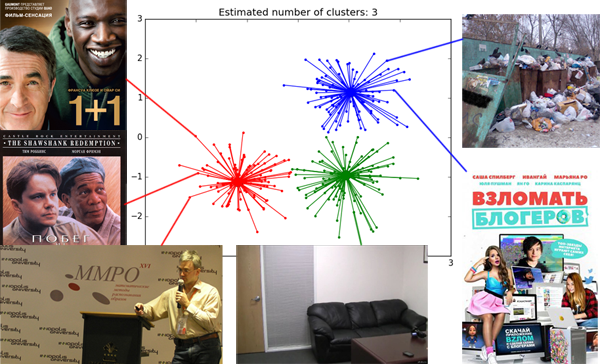
Часть вторая — DBSCAN
Часть третья — кластеризация временных рядов
Часть четвёртая — Self-Organizing Maps (SOM)
Часть пятая — Growing Neural Gas (GNG)
Если вы спросите начинающего аналитика данных, какие он знает методы классификации, вам наверняка перечислят довольно приличный список: статистика, деревья, SVM, нейронные сети… Но если спросить про методы кластеризации, в ответ вы скорее всего получите уверенное «k-means же!» Именно этот золотой молоток рассматривают на всех курсах машинного обучения. Часто дело даже не доходит до его модификаций (k-medians) или связно-графовых методов.
Не то чтобы k-means так уж плох, но его результат почти всегда дёшев и сердит. Есть более совершенные способы кластеризации, но не все знают, какой когда следует применять, и очень немногие понимают, как они работают. Я бы хотел приоткрыть завесу тайны над некоторыми алгоритмами. Начнём с Affinity propagation.




 На Хабре уже было несколько публикаций о том, как айтишники строят себе дома и что из этого получается.
На Хабре уже было несколько публикаций о том, как айтишники строят себе дома и что из этого получается.