
Краткое и понятное описание подхода RAG (Retrieval Augmented Generation) при работе с большими языковыми моделями.

Пользователь
Краткое и понятное описание подхода RAG (Retrieval Augmented Generation) при работе с большими языковыми моделями.
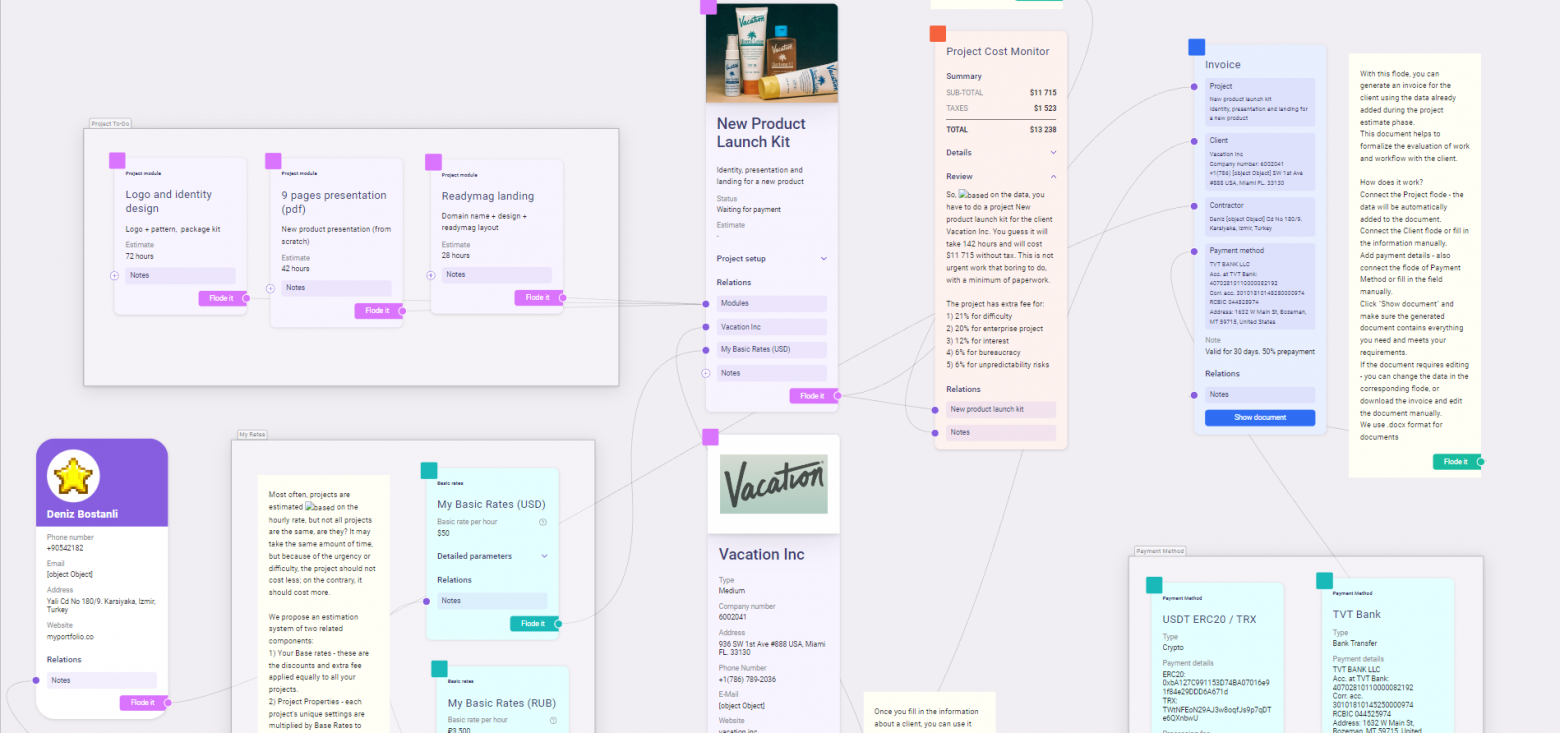
Рабочее пространство в нашем приложении представляет собой бесконечную доску, по которой могут перемещаться ноды. Необходимо реализовать масштабирование этого пространства и перемещение по нему. Все это мы делаем без использования Canvas, так как приложение построено на React, в дизайн-системе используется antd, а ноды могут быть огромными формами. Согласитесь, реализовывать такие интерфейсы было бы гораздо сложнее, не будь у нас доступа к нативным средствам HTML-5.

Представьте, в вашем проекте есть куча разбросанных по пространству логически связанных элементов, которые (о ужас!) могут свободно перемещаться по пространству. Задача - красиво и наглядно показать пользователю эти связи, чтобы упорядочить представление. В данной статье я покажу нашу реализацию.

В процессе разработки UI для игр Forza Horizon 3 и Forza Motorsport 7 я имел возможность поработать с потрясающими акриловыми матовыми элементами дизайна.
Вдохновлённый этим дизайном, я захотел создать похожий эффект при помощи HTML. В этом посте я расскажу о своих попытках создания красивого эффекта стекла, а также представлю пример кода и ассетов для тех, кто захочет попробовать реализовать эту методику самостоятельно.

Шпаргалка по основным секциям Nginx, которые следует держать под рукой. Ниже приведены самые частые функции: включение SSL, переадресация, раздача статики и т.д.

Мой обеденный кофе прервался. Начали приходить уведомления от мониторинга, что сайт и API не отвечают, а CloudFlare отдаёт 521-ю ошибку на все запросы. Спустя пять минут ко мне в личку пришли пользователи с жалобами на неработающие приложения. А ещё спустя пять позвонил сооснователь проекта и сказал, что от нас требуют $250 за остановку DDOS'a.
Ниже расскажу, как мы командой решали проблему, какие ошибки допустил я и чем всё закончилось.

Всем привет! Одна из моих рутинных задач - это подъем новых проектов и микросервисов в облаках. Для этого практически всегда нужны домены и поддомены с наличием SSL сертификата. У меня выработался подход, с помощью которого я автоматизировал процесс выдачи сертификатов с помощью certbot. О чём и хочу рассказать.

В предыдущей статье мы подготовили наше тестовое приложение — бота для обмена анонимными сообщениями в Telegram.
Пришло время отобразить все данные, которые мы собрали. Для этого мы будем использовать Redash.

В последнее время я занимался файнтюнингом Llama 3 на открытых датасетах, а сейчас планирую собрать собственный датасет для новых экспериментов. Встает вопрос, как оценивать эффективность обучения.
Для оценки моделей используются специальные наборы текстовых запросов, промптов, которые проверяют, например, насколько хорошо модель следует инструкциям. Для разных типов задач будут разные критерии оценки.
Например, есть GLUE (General Language Understanding Evaluation), оценка общего понимания естественного языка. Оценивает в том числе способность модели отвечать на вопросы, логическую связность и sentiment analysis - умение распознавать эмоциональную окраску. Это обширная область задач, и одного GLUE-бенчмарка явно мало, чтобы как следует оценить общее понимание моделью естественного языка, поэтому существуют другие тестовые наборы, например, SuperGLUE и MMLU (Massive Multitask Language Understanding). Последний бенчмарк оценивает, насколько хорошо в среднем модель понимает сложные вопросы из разных категорий - гуманитарной, социальной, STEM - то есть точные науки и естествознание.
Есть HellaSwag - это интересный бенчмарк, составленный из непростых вопросов, которые проверяют модель на здравый смысл, common sense. HellaSwag датасет содержит текстовое описание события, записанного на видео, и несколько вариантов завершения этого события, только один из которых правильный.

В этой статье я расскажу, как я смог обучить модель, которая превзошла GPT 3.5 Turbo на русскоязычной части MT-Bench. Также я рассмотрю новую конфигурацию для обучения на двух графических процессорах параллельно с помощью accelerate и deepspeed.
Особенный интерес представляет мой датасет для обучения. Он получен из сабсета мультиязычных промтов набора lightblue/tagengo-gpt4 на русском, английском и китайском, всего 10 тысяч примеров, сгенерированных с помощью GPT-4o. Это в 8 раз меньше, чем исходный набор Tagengo, но обученная на последнем Suzume, как показали бенчмарки, лишь очень незначительно превосходит мою модель на ru_mt_bench, а на англоязычном бенче и вовсе уступает ей. Это значит, что я в разы сэкономил на GPU за счет более высокого качества данных, полученных с помощью GPT-4o.
Я использовал скрипт для получения ответов по заданным промптам. Для генерации русскоязычной выборки я изменил часть скрипта, чтобы выбрать все промпты на русском из Tagengo (8K примеров), так как основной фокус при обучении модели был на русском языке.
В итоге я получил датасет ruslandev/tagengo-rus-gpt-4o и приступил к обучению.
Для этого я создал виртуальную машину с NVIDIA H100, используя сервис immers.cloud. Для достижения наилучших результатов по instruction-following (что проверяется на MT-Bench) я взял в качестве исходной модели meta-llama/Meta-Llama-3-8B-Instruct. Именно на ней обучена модель Suzume, у которой высокая оценка на MT Bench. Предыдущие эксперименты показали, что базовая Llama-3 8B, а особенно ее четырехбитная версия для QLoRA — unsloth/llama-3-8b-bnb-4bit - значительно отстает по оценкам бенчмарка.

В этой данной статье познакомимся с LangChain, перспективным фреймворком для работы с языковыми моделями. С его помощью можно создать свой собственный аналог ChatGPT всего в несколько строк кода. Благодаря модульной структуре, LangChain позволяет быстро и легко разрабатывать AI приложения различной сложности.

Привет! Меня зовут Оля, я программист учебного центра компании «Тензор».
В декабре 23-го мне поступила творческая задача разработать телеграм-бот для проведения новогоднего марафона-тренинга по личностному росту.
В этой статье расскажу о проблеме, с которой столкнулась при разработке телеграм-бота. Разберем ошибку 429 (Too Many Requests) и лимиты на доступ к API.
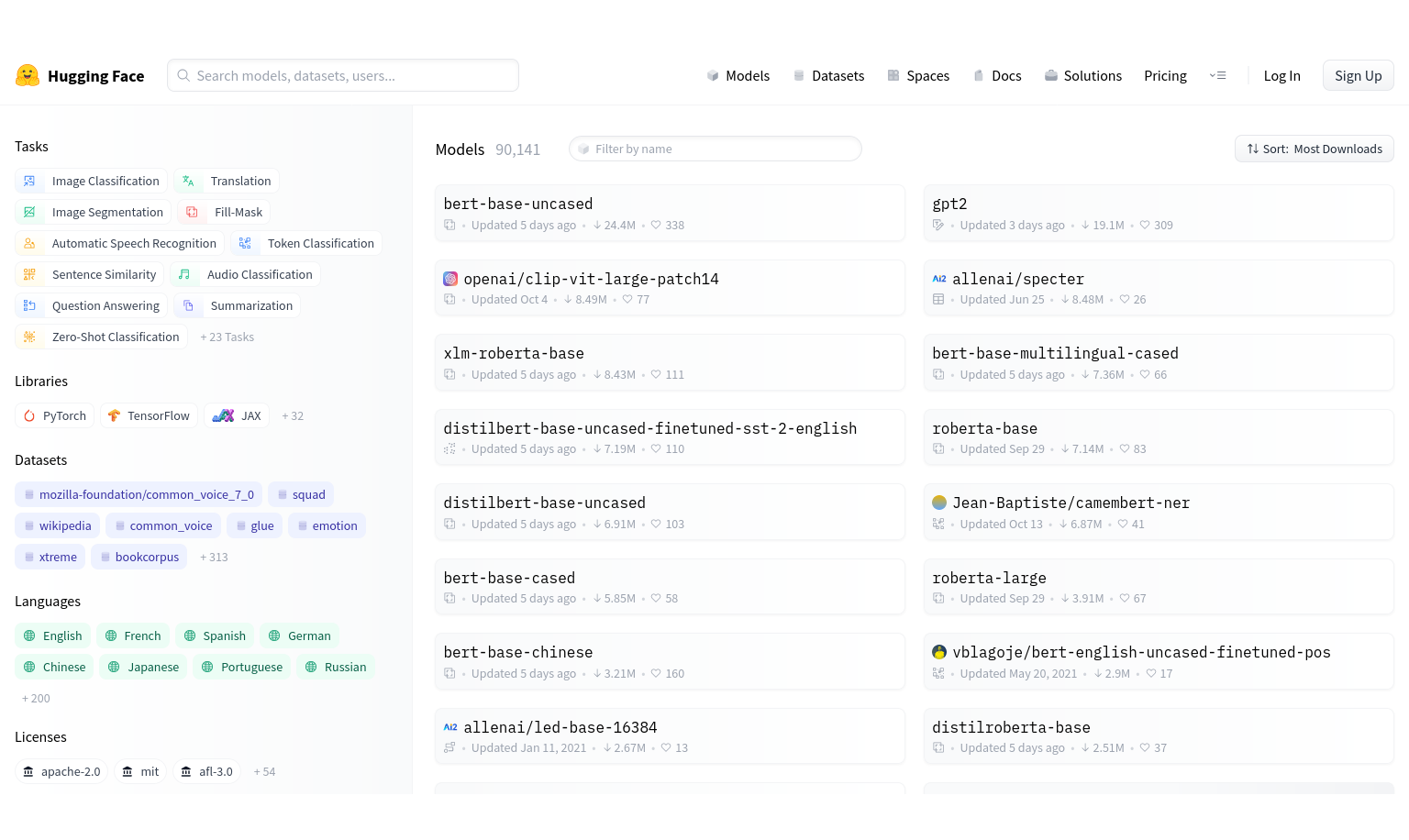
Библиотека Transformers предоставляет доступ к огромному кол-ву современных предобученных моделей глубокого обучения. В основном основаных на архитектуре трансформеров. Модели решают весьма разнообразный спектр задач: NLP, CV, Audio, Multimodal, Reinforcement Learning, Time Series.
В этой статье пройдемся по основным ее возможностям и попробуем их на практике.
ТК LLM is all you need | ТК Private Sharing | Курс: Алгоритмы Машинного обучения с нуля

Инференсом ML-модели называют процесс её работы на конечном устройстве. Соответственно, чем больше мы разгоняем инференс, тем быстрее работает модель. Скорость может зависеть от разных условий, например, от архитектуры, которую вы выбрали для модели, или от железа, на котором работает устройство. Кроме того, проблема тяжёлого инференса остро ощущается на больших языковых моделях (LLM) так остро, как ни на каких других моделях.
Меня зовут Роман Горб, я старший ML-разработчик в команде YandexGPT. Тема инференса LLM заинтересовала меня, потому что я занимался R&D в квантовании сеток для CV-задач. Сегодня я расскажу, как безболезненно увеличить скорость инференса. Сперва разберёмся, зачем это нужно, а потом рассмотрим разные методы ускорения и фреймворки, которые могут в этом помочь.
Обычно pytest используется не самостоятельно, а в среде тестирования с другими инструментами. В этой главе рассматриваются другие инструменты, которые часто используются в сочетании с pytest для эффективного и результативного тестирования. Хотя это отнюдь не исчерпывающий список, обсуждаемые здесь инструменты дадут вам представление о вкусе силы смешивания pytest с другими инструментами.


FastAPI — это современная, быстрая (высокопроизводительная) веб-инфраструктура для создания API-интерфейсов с Python 3.7+ на основе стандартных подсказок типов Python.
В этой статье мы рассмотрим как написать его с нуля.

Привет, друзья!
Хочу поделиться с вами заметками о Next.js (надеюсь, кому-нибудь пригодится).
Next.js — это основанный на React фреймворк, предназначенный для разработки веб-приложений, обладающих функционалом, выходящим за рамки SPA, т.е. так называемых одностраничных приложений.
Как известно, основным недостатком SPA являются проблемы с индексацией страниц таких приложений поисковыми роботами, что негативно влияет на SEO.
Впрочем, по моим личным наблюдениям, в последнее время ситуация стала меняться к лучшему, по крайней мере, страницы моего небольшого SPA-PWA-приложения нормально индексируются.
Кроме того, существуют специальные инструменты, такие как react-snap, позволяющие превратить React-SPA в многостраничник путем предварительного рендеринга приложения в статическую разметку. Метаинформацию же можно встраивать в head с помощью таких утилит, как react-helmet. Однако Next.js существенно упрощает процесс разработки многостраничных и гибридных приложений (последнего невозможно добиться с помощью того же react-snap). Он также предоставляет множество других интересных возможностей.
Обратите внимание: данная статья предполагает, что вы обладаете некоторым опытом работы с React. Также обратите внимание, что заметки не сделают вас специалистом по Next.js, но позволят получить о нем исчерпывающее представление.
Заметки состоят из 2 частей. Это часть номер два.
Привет, друзья!
Хочу поделиться с вами заметками о Next.js (надеюсь, кому-нибудь пригодится).
Next.js — это основанный на React фреймворк, предназначенный для разработки веб-приложений, обладающих функционалом, выходящим за рамки SPA, т.е. так называемых одностраничных приложений.
Как известно, основным недостатком SPA являются проблемы с индексацией страниц таких приложений поисковыми роботами, что негативно влияет на SEO.
Впрочем, по моим личным наблюдениям, в последнее время ситуация стала меняться к лучшему, по крайней мере, страницы моего небольшого SPA-PWA-приложения нормально индексируются.
Кроме того, существуют специальные инструменты, такие как react-snap, позволяющие превратить React-SPA в многостраничник путем предварительного рендеринга приложения в статическую разметку. Метаинформацию же можно встраивать в head с помощью таких утилит, как react-helmet. Однако Next.js существенно упрощает процесс разработки многостраничных и гибридных приложений (последнего невозможно добиться с помощью того же react-snap). Он также предоставляет множество других интересных возможностей.
Обратите внимание: данная статья предполагает, что вы обладаете некоторым опытом работы с React. Также обратите внимание, что заметки не сделают вас специалистом по Next.js, но позволят получить о нем исчерпывающее представление.
Заметки состоят из 2 частей. Это часть номер раз.

Если одной метафорой, то произошли первые испытания термоядерной бомбы. Специалисты с благоговейным ужасом и радостью смотрят на поднимающийся над планетою гриб. Остальное человечество живёт обычной жизнью, пока не зная, современниками какого события они являются. Мне нравилось изучение цифровых технологий, сильнее интересовала только работа человеческой психики и междисциплинарное знание, которое можно объединить под условным названием «общая теория информации». Эти увлечения позволили увидеть в смене цифр смену эпох. Постараюсь объяснить суть случившегося максимально доступно.
Систематическое тестирование программного обеспечения, особенно в сообществе Python, часто либо полностью игнорируются или выполняются специальным образом. Многие программисты на Python совершенно не подозревают о существовании pytest. Брайен Оккен берет на себя труд, доказать, что тестирование программного обеспечения с помощью pytest легко, естественно и даже интересно.
Dmitry Zinoviev
Author of Data Science Essentials in Python

