
Начать изучение

Аналитик данных

Инференсом ML-модели называют процесс её работы на конечном устройстве. Соответственно, чем больше мы разгоняем инференс, тем быстрее работает модель. Скорость может зависеть от разных условий, например, от архитектуры, которую вы выбрали для модели, или от железа, на котором работает устройство. Кроме того, проблема тяжёлого инференса остро ощущается на больших языковых моделях (LLM) так остро, как ни на каких других моделях.
Меня зовут Роман Горб, я старший ML-разработчик в команде YandexGPT. Тема инференса LLM заинтересовала меня, потому что я занимался R&D в квантовании сеток для CV-задач. Сегодня я расскажу, как безболезненно увеличить скорость инференса. Сперва разберёмся, зачем это нужно, а потом рассмотрим разные методы ускорения и фреймворки, которые могут в этом помочь.

С момента выхода первой статьи «Attention is All You Need» я с жадностью и любопытством, присущими любому исследователю, пытаюсь углубиться во все особенности и свойства моделей на базе архитектуры трансформер. Но, если честно, я до сих пор не понимаю, как они работают и почему так хорошо обучаются. Очень хочу разобраться, в чём же причина такой эффективности этих моделей, и есть ли предел их возможностей?
Такому изучению трансформеров «под микроскопом» и посвящена наша научная работа, только что представленная на конференции EACL 2024, которая проходила на Мальте — «The Shape of Learning: Anisotropy and Intrinsic Dimensions in Transformer-Based Models». В этой работе мы сфокусировались на наблюдении за пространством эмбеддингов (активаций) на промежуточных слоях по мере обучения больших и маленьких языковых моделей (LM).
С момента выхода оригинальной статьи про трансформер прошло уже больше 7 лет, и эта архитектура перевернула весь DL: начав с NLP архитектура теперь применяется везде, включая генерацию картинок. Но та ли это архитектура или уже нет? В этой статье я хотел сделать краткий обзор основных изменений, которые используются в текущих версиях моделей Mistral, Llama и им подобным.

Мы команда data science Ozon fresh. В этой статье мы расскажем об одной из наших задач - алгоритм, который помогает управлять нашим огромным ассортиментом.
Ozon fresh — это сервис быстрой доставки продуктов, бакалеи, бытовой техники, электроники и других товаров. В нашем ассортименте более 35 000 уникальных позиций (готовая еда, мясо, рыба, фрукты, овощи, товары для гигиены и многое другое). Специфика Ozon fresh заключается в мини-складах, где хранятся товары. Они доставляются клиентам в радиусе нескольких километров.
Управление таким количеством позиций требует много человеческих и технологических ресурсов. У нас этим занимаются более 30 человек. Для упрощения работы мы используем различные группировки товарных позиций. Самая популярная — иерархическая четырёхуровневая группировка (далее мы будем называть её «категорийное дерево»).

Привет, меня зовут Александр Егоров, я MLOps инженер. В статье расскажу о том, как мы в банке выкатываем огромное количество моделей. Разберём не только пайплайн по выкладке отдельных моделей, но и целые каскады.

Привет! Меня зовут Василий Землянов, я занимаюсь разработкой ML-инфраструктуры. Несколько лет я проработал в команде, которая делает споттер — специальную маленькую нейросетевую модельку, которая живёт в умных колонках Яндекса и ждёт от пользователя слова «Алиса». Одной из моих задач в этой команде была квантизация моделей. На пользовательских устройствах мало ресурсов, и мы решили, что за счёт квантизации сможем их сэкономить — так в итоге и вышло.
Потом я перешёл в команду YandexGPT. Вместо маленьких моделей я стал работать с очень крупными. Мне стало интересно, как устроена квантизация больших языковых моделей (LLM). Ещё меня очень впечатляли истории, где люди берут гигантские нейросети, квантизируют в 4 бита и умудряются запускать их на ноутбуках. Я решил разобраться, как это делается, и собрал материал на доклад для коллег и друзей. А потом пришла мысль поделиться знаниями с более широкой аудиторией, оформив их в статью. Так я и оказался на Хабре :)
Надеюсь, погружение в тему квантизации будет интересно как специалистам, так и энтузиастам в сфере обучения нейросетей. Я постарался написать статью, которую хотел бы прочитать сам, когда только начинал изучать, как заставить модели работать эффективнее. В ней мы подробно разберём, зачем нужна квантизация и в какой момент лучше всего квантизовать модель, а ещё рассмотрим разные типы данных и современные методы квантизации.
Ежемесячная аудитория ОК только в России превышает 36 млн человек. Причём это активные пользователи, которые хорошо взаимодействуют с нашим контентом: ставят Классы, комментируют, делают репосты. Залогом активного отклика во многом является формирование новостной ленты с учетом предпочтений каждого конкретного пользователя.
Меня зовут Дмитрий Решетников. Я тимлид команды рекомендаций в Ленте ОК. В этой статье я расскажу, как выглядит наш пайплайн рекомендации в ленте новостей, о месте item2vec в нём и результатах внедрения такого подхода.
Кластеризация — это набор методов без учителя для группировки данных по определённым критериям в так называемые кластеры, что позволяет выявлять сходства и различия между объектами, а также упрощать их анализ и визуализацию. Из-за частичного сходства в постановке задач с классификацией кластеризацию ещё называют unsupervised classification.
В данной статье описан не только принцип работы популярных алгоритмов кластеризации от простых к более продвинутым, но а также представлены их упрощённые реализации с нуля на Python, отражающие основную идею. Помимо этого, в конце каждого раздела указаны дополнительные источники для более глубокого ознакомления.


Авторский обзор 90+ нейросетевых моделей на основе Transformer для тех, кто не успевает читать статьи, но хочет быть в курсе ситуации и понимать технические детали идущей революции ИИ.

Разносторонний системный рассказ о том, какими способами можно научить модель работать с длинными последовательностями. Для специалистов, занимающихся обучением LLM, и всех, кто хочет разобраться в теме.

Обзор методов кодирования позиций токенов в нейросетевых моделях Transformer с упором на обработку длинных текстов. Для тех, кто учит и использует LLM, и для всех интересующихся.

Привет, Хабр! Если вы интересуетесь NLP или просто современными DL моделями, то приглашаю вас узнать, как можно, имея всего лишь одну A100, около 30 гигабайтов текста и несколько дней обучения, решить проблему ограниченного окна контекста для русскоязычных трансформеров. А ещё сделаем несколько оптимизаций и добьёмся почти лучших метрик в бенчмарке encodechka.

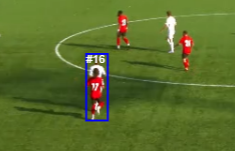
Все же знают серию компьютерных футбольных симуляторов FIFA? Раньше я много играл в эту игру. Кто-то скажет, что это бесполезная трата времени, но я с этим не согласен. Эта игра вдохновила меня на разработку pet-проекта, который стал моим бакалаврским дипломом.
Во время игры в FIFA пользователь видит небольшую карту с местоположением игроков и мяча на поле, данный элемент интерфейса является очень полезной фичей, без которой невозможно представить полноценный игровой процесс. Мне показалось, что данную карту было бы неплохо перенести в реальный мир, используя видеозапись матча и нейросеть.

В этой статье я расскажу о нашей последней работе — Multilingual Triple Match — системе для поиска ответов на фактологические вопросы, которая по своей точности обходит даже ChatGPT.
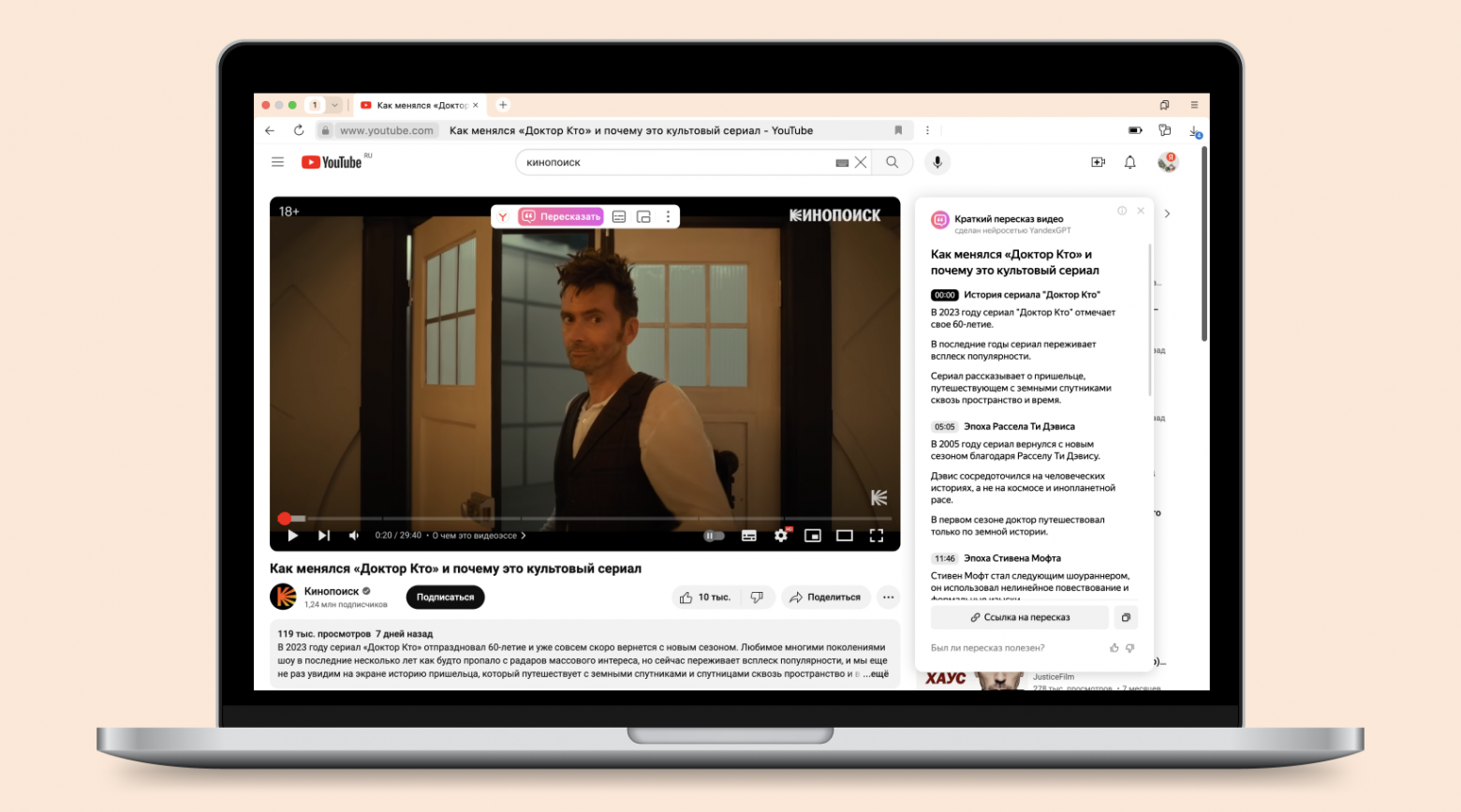
Порой бывает сложно перематывать длинный ролик в надежде найти хоть что-то интересное или тот самый момент из Shorts. Или иногда хочется за ночь узнать, о чём шла речь на паре научных конференций. Для этого в Браузере есть волшебная кнопка — «Пересказать», которая экономит время и помогает лучше понять, стоит ли смотреть видео, есть ли в нём полезная информация, и сразу перейти к интересующей части.
Сегодня я расскажу про модель, которая быстро перескажет видео любой длины и покажет таймкоды для каждой части. Под катом — история о том, как мы смогли выйти за лимиты контекста модели и научить её пересказывать даже очень длинные видео.

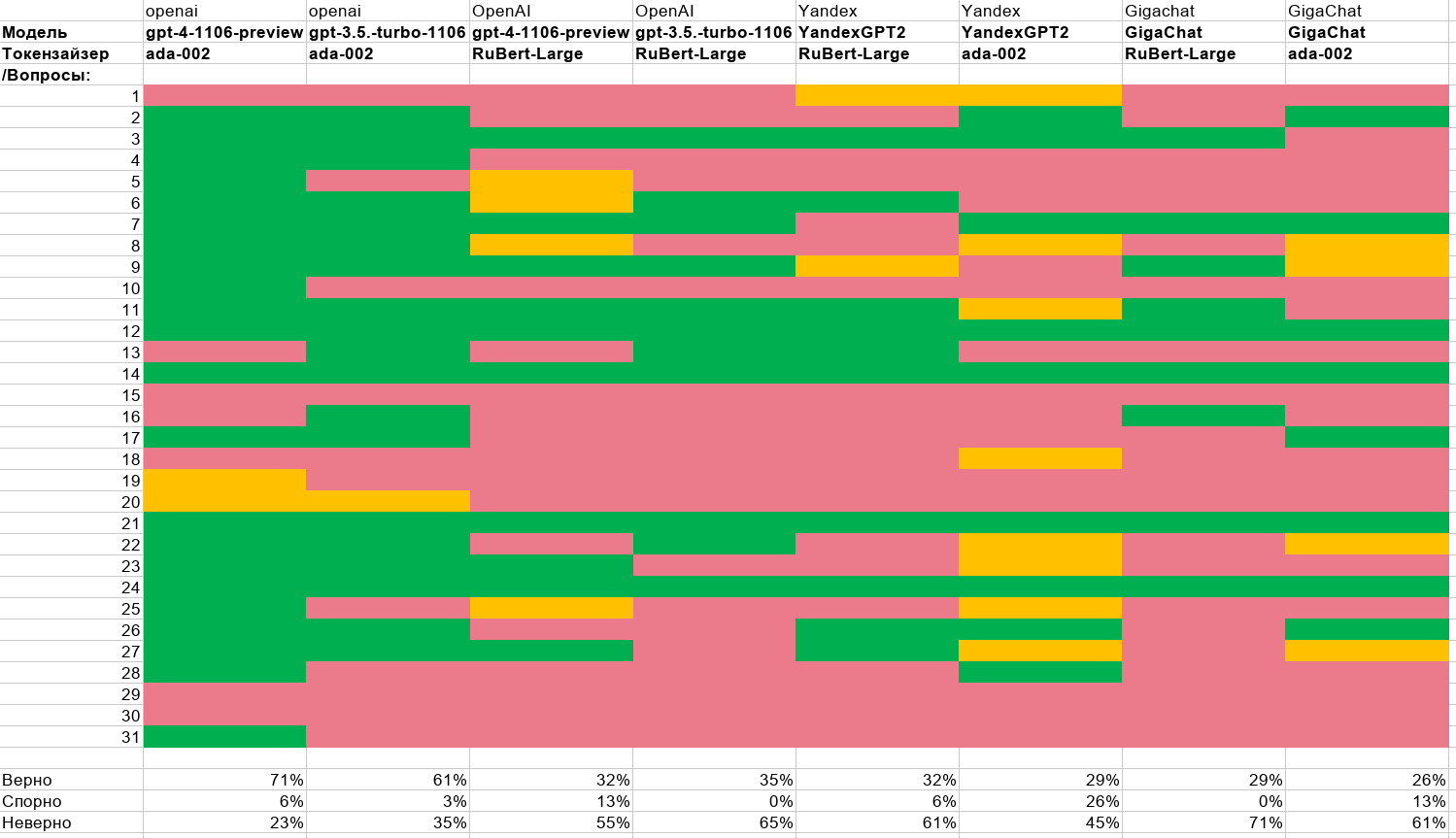
В первой части статьи я рассказывал о создании цифрового юриста, способного отвечать на вопросы на основе 200-страничного регламента. Цель — работа такого юриста в закрытом контуре организации, без использования облачных технологий.
Особенностью эксперимента является в том, что оценку ответов делают обычные люди. Юристы.
Во второй части мы рассмотрим как и зачем делать локальные токензайзеры и попробуем запустить всё полностью на локальной машине с видеокартой 4090.
В конце будет приведена полная сравнительная таблица разных моделей и токензайзеров.
Меня зовут Дмитрий Гуреев. Я занимаю должность CDTO в одной из медицинских компаний и параллельно веду работу по популяризации ИИ в среднем бизнесе. Генеративные модели привлекли мое внимание ещё в феврале 2022 года. Тогда я внедрил цифрового ассистента для полевых продавцов.
Летом 2022 года хороший знакомый из крупной компании предложил совместный эксперимент. Создать цифрового юриста, способного отвечать на вопросы первой линии, используя в качестве базы знаний 200-страничный регламент из более чем 1200 пунктов. Все это должно было функционировать в закрытом контуре. Без интернета.
Задача представлялась крайне интересной...
Вторая часть здесь.