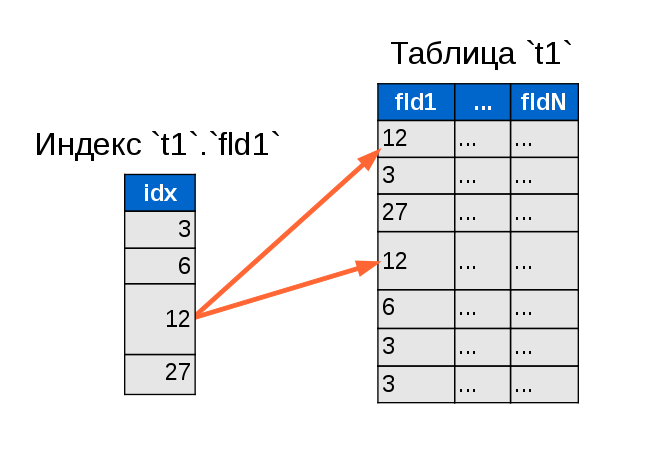
Оптимизация явно не является коньком MySQL сервера. Цель данной статьи объяснить разработчикам, которые плотно не работают с базами данных и иногда не понимают, по какой причине запрос, который успешно отрабатывает в других СУБД, в MySQL безбожно тормозит, каким образом оптимизируется конструкция between в MySQL.
MySQL использует rule based оптимизатор. Зачатки cost based оптимизации в нем конечно присутствуют, но не в должной мере, в какой их хотелось бы видеть. По этой причине часто мощности получаемых после применения фильтров множеств вычисляются неверно. Это приводит к ошибкам оптимизатора и выбору неверного плана выполнения. При чем полученные between оптимизации невозможно изменить явным указанием: индексов для выполнения запроса и порядка соединения таблиц.
MySQL использует rule based оптимизатор. Зачатки cost based оптимизации в нем конечно присутствуют, но не в должной мере, в какой их хотелось бы видеть. По этой причине часто мощности получаемых после применения фильтров множеств вычисляются неверно. Это приводит к ошибкам оптимизатора и выбору неверного плана выполнения. При чем полученные between оптимизации невозможно изменить явным указанием: индексов для выполнения запроса и порядка соединения таблиц.