
Сейчас многие покупают точки доступа 802.11n, но хороших скоростей достичь удается не всем. В этом посте поговорим о не очень очевидных мелких нюансах, которые могут ощутимо улучшить (или ухудшить) работу Wi-Fi. Всё описанное ниже применимо как к домашним Wi-Fi-роутерам со стандартными и продвинутыми (DD-WRT & Co.) прошивками, так и к корпоративным железкам и сетям. Поэтому, в качестве примера возьмем «домашнюю» тему, как более родную и близкую к телу. Ибо даже самые администые из админов и инженеристые из инженеров живут в многоквартирных домах (или поселках с достаточной плотностью соседей), и всем хочется быстрого и надежного Wi-Fi.
[!!]: после замечаний касательно публикации первой части привожу текст целиком. Если вы читали первую часть — продолжайте отсюда.
[!!]: после замечаний касательно публикации первой части привожу текст целиком. Если вы читали первую часть — продолжайте отсюда.


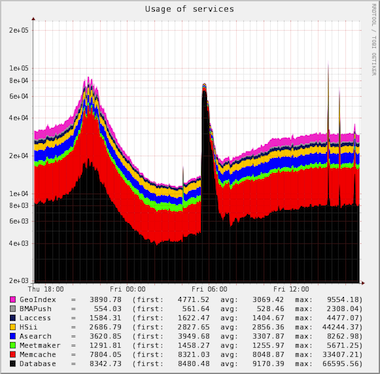 Давайте представим себе типичный, набирающий популярность стартап, использующий, например, PHP или Python. Сначала все находится на одном сервере — PHP (или Python), Apache, MySQL. Затем вы выносите MySQL на отдельный сервер, устанавливаете nginx для раздачи контента, возможно, добавляете memcached для кеширования и еще несколько серверов приложений…
Давайте представим себе типичный, набирающий популярность стартап, использующий, например, PHP или Python. Сначала все находится на одном сервере — PHP (или Python), Apache, MySQL. Затем вы выносите MySQL на отдельный сервер, устанавливаете nginx для раздачи контента, возможно, добавляете memcached для кеширования и еще несколько серверов приложений…

{kind=link}