reCAPTCHA: дополнительная польза от борьбы со спамом.
1 min
Сотрудники Carnegie Mellon University подсчитали, что ежедневно по всему миру люди заполняют 60 миллионов каптч. Приняв время заполнения каптчи за 10 секунд, получаем более 160 000 человекочасов (или около 19-ти ЛЕТ!) за день.
И они решили попытаться хотя бы малую часть пропадающих зазря усилий направить на полезное дело, а именно — на распознавание книг.
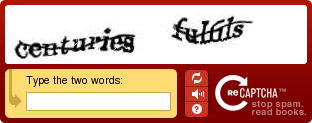
Суть их идеи такова: на реКАПТЧЕ даются ДВА идущих подряд слова из книги, одно из которых система распознания текста не осилила. реКАПТЧА проверяет известное слово, а вариант распознания неизвестного добавляет в свою базу. Оба этих слова задисторчены обыкновенными и специальными каптча-фильтрами, чтобы пользователь не схалявил, предложив вариант «упячка», к примеру.
Демо и подробности тут:
Университет предлагает готовые решения для форумов/блогов/почты. ИМХО если технология найдет свое применение, вебдваноль наконец сотворит что-то действительно полезное.
И они решили попытаться хотя бы малую часть пропадающих зазря усилий направить на полезное дело, а именно — на распознавание книг.
Суть их идеи такова: на реКАПТЧЕ даются ДВА идущих подряд слова из книги, одно из которых система распознания текста не осилила. реКАПТЧА проверяет известное слово, а вариант распознания неизвестного добавляет в свою базу. Оба этих слова задисторчены обыкновенными и специальными каптча-фильтрами, чтобы пользователь не схалявил, предложив вариант «упячка», к примеру.
Демо и подробности тут:
Университет предлагает готовые решения для форумов/блогов/почты. ИМХО если технология найдет свое применение, вебдваноль наконец сотворит что-то действительно полезное.
 Знаете, работа с стартапе, который пытается создать что-то новое и уникальное на рынке очень захватывает. И не только открывающимися возможностями, но и часто нетривиальными задачами и вопросами, которые ставятся перед создателями и которые раньше никто не решал. Вот один из таких вопросов как раз вчера появился передо мной: дано нам произвольную строку текста, заведомо известно, что она может быть двух, а в некоторых случаях и трехъязычной, то есть там смешанный текст из нескольких языков. Необходимо прозрачно для пользователя определить язык, на котором написан текст.
Знаете, работа с стартапе, который пытается создать что-то новое и уникальное на рынке очень захватывает. И не только открывающимися возможностями, но и часто нетривиальными задачами и вопросами, которые ставятся перед создателями и которые раньше никто не решал. Вот один из таких вопросов как раз вчера появился передо мной: дано нам произвольную строку текста, заведомо известно, что она может быть двух, а в некоторых случаях и трехъязычной, то есть там смешанный текст из нескольких языков. Необходимо прозрачно для пользователя определить язык, на котором написан текст.