
5 разных библиотек Python, которые сэкономят ваше время
5 мин
Перевод

В этой подборке, переводом которой мы решили поделиться к старту курса о машинном и глубоком обучении, по мнению автора, каждая библиотека заслуживает отдельной статьи. Всё начинается с самого начала: предлагается библиотека, которая сокращает шаблонный код импортирования; заканчивается статья пакетом удобной визуализации данных для исследовательского анализа. Автор также касается работы с картами Google, ускорения и упрощения работы с моделями ML и библиотеки, которая может повысить качество вашего проекта в области обработки естественного языка. Посвящённый подборке блокнот Jupyter вы найдёте в конце.






 Экологически чистая энергетика иногда сталкивается с неожиданными препятствиями. Кто мог подумать, что против неё выступят простые американцы, а основанием для критики станет вред природе? В такое трудно поверить, но именно это произошло на городском собрании небольшого города
Экологически чистая энергетика иногда сталкивается с неожиданными препятствиями. Кто мог подумать, что против неё выступят простые американцы, а основанием для критики станет вред природе? В такое трудно поверить, но именно это произошло на городском собрании небольшого города 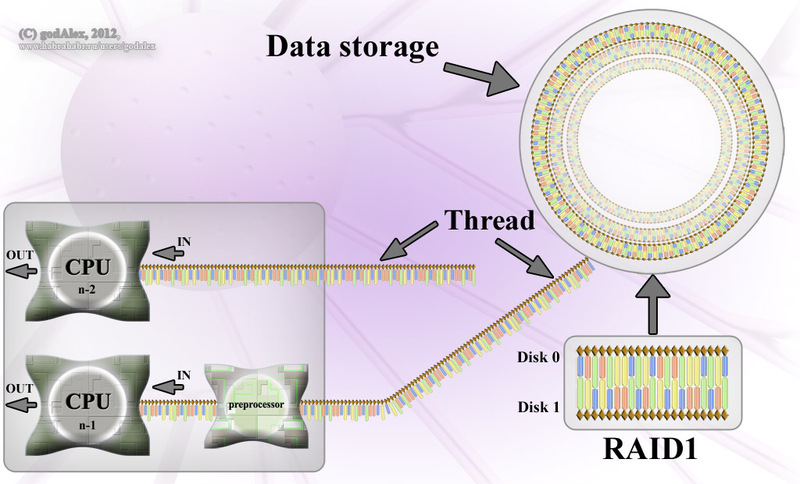
 В стремлении рассказать о самом сложном, как можно быстрее, очевидно, забываешь о самом простом. И, в моем случае, не только о простом, но и о важном связывающем звене. Причинно-следственная связь слегка нарушилась. В моих предыдущих статьях (
В стремлении рассказать о самом сложном, как можно быстрее, очевидно, забываешь о самом простом. И, в моем случае, не только о простом, но и о важном связывающем звене. Причинно-следственная связь слегка нарушилась. В моих предыдущих статьях ( В современном мире анализа данных использовать только один метод или только один подход означает, что рано или поздно ты столкнешься с фактом, как сильно ты ошибался. Для анализа данных комбинируют различные методики, сравнивают результат и на основании сравнения уже делают более точные прогнозы. В программе ZINBA использован именно такой подход. Разработчики объединили разнообразные методы анализа DNA-seq экспериментов в едином пакете. Этот пакет написан для программы статистической обработки данных R. Что же делает ZINBA? Находит различные обогащенные регионы даже в тех случаях, когда некоторые из них были усилены, например, химически или имеют разную степень соотношения сигнал-шум.
В современном мире анализа данных использовать только один метод или только один подход означает, что рано или поздно ты столкнешься с фактом, как сильно ты ошибался. Для анализа данных комбинируют различные методики, сравнивают результат и на основании сравнения уже делают более точные прогнозы. В программе ZINBA использован именно такой подход. Разработчики объединили разнообразные методы анализа DNA-seq экспериментов в едином пакете. Этот пакет написан для программы статистической обработки данных R. Что же делает ZINBA? Находит различные обогащенные регионы даже в тех случаях, когда некоторые из них были усилены, например, химически или имеют разную степень соотношения сигнал-шум.


