Анализ временных рядов
Easy
8 min
Review

Привет! В последние годы аналитика данных переживает настоящий бум. Все большее количество компаний принимают решение сбора, хранения и анализа данных, чтобы повысить эффективность своих бизнес-процессов и принимать решения на основе фактов.
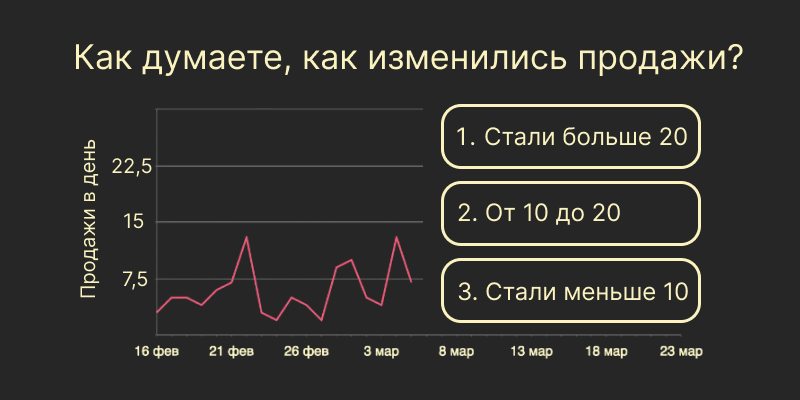
Одним из наиболее важных инструментов в аналитике данных является анализ временных рядов. Временной ряд - это последовательность наблюдений за определенным параметром в разные моменты времени. Таким образом, временной ряд содержит информацию о том, как изменяется параметр со временем.


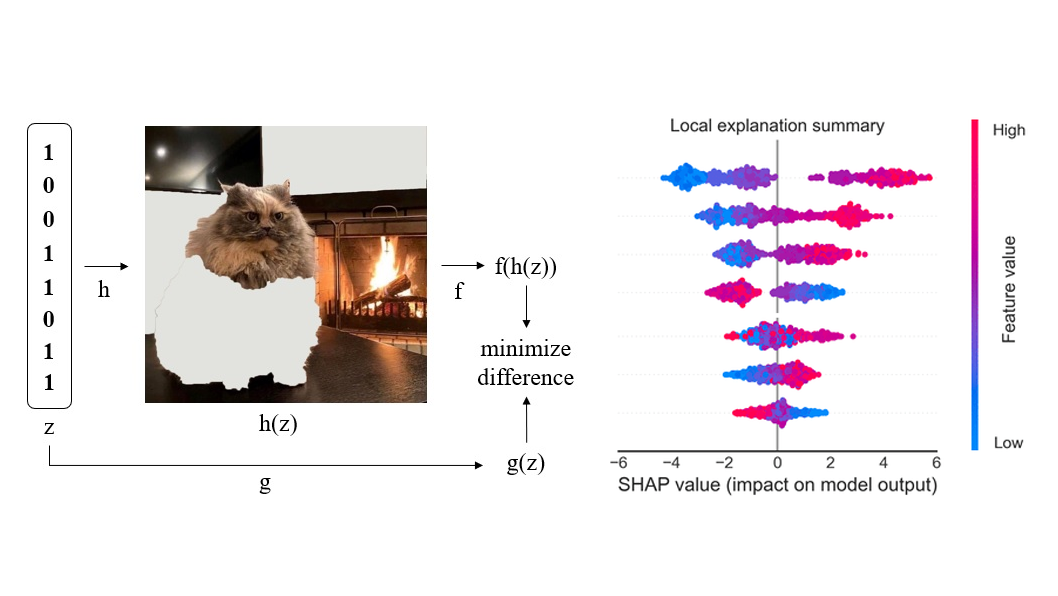






 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест 
 .
.