Продолжаю серию переводов статей сайта html5rocks. Мы уже говорили про то, как внедрять шрифты, как работать с видео, сегодня мы поговорим про то как делать всплывающие сообщения в браузере с помощью Notifications API. Работает оно к сожалению пока только в Хроме, но есть уже начальная версия спецификации. Под катом подробности.

Mirror @Mirror
User
Выбор хостинга с упором в облака и с прицелом на развёртывание Rails 3 app
9 min
Несмотря на наличие «Rails 3» в названии топика, и рассмотрения в теле статьи специфичных для Rails 3 аспектов, она может быть интересна всем остальным из-за освещения аспектов общего характера.
На Хабре много ответов на разные мои вопросы, но ответа на вопрос «а где же мне хостится», получить я, даже при внимательном штудировании Хабра, не смог. Я даже воспользовался q&a, пытаясь определиться: раз и два, но окончательного ответа так и не получил. Пришлось проводить самостоятельное исследование.
Я решил поделиться своими скромными изысканиями на эту тему с хабрасообществом. Они не претендуют на всеохватность. Но могут внести некоторую ясность для человека, собирающегося выбрать облачно\vds-ный хостинг, но не имеющего никакого представления о рынке.
Поскольку я не учёл ещё целой кучи хороших хостингов, то я буду очень благодарен за комментарии, которые позволят пополнить этот список. А также ввиду того, что я не пользовался почти ни одним из нижеперечисленных хостингов, я буду рад поместить отзывы из первых рук в тело статьи, если таковые будут оставлены в комментариях.
Список упоминаемых хостингов: 1gb.ru, Hostingrails, RackspaceCloud, Mediatemple, Heroku, Amazon Web Services (шапочно), Engine Yard (шапочно), Altnet (привет с Хабрахабра), justhost.com (лучи поноса), Linode, Hetzner online (выделенный сервер), Server4you
На Хабре много ответов на разные мои вопросы, но ответа на вопрос «а где же мне хостится», получить я, даже при внимательном штудировании Хабра, не смог. Я даже воспользовался q&a, пытаясь определиться: раз и два, но окончательного ответа так и не получил. Пришлось проводить самостоятельное исследование.
Я решил поделиться своими скромными изысканиями на эту тему с хабрасообществом. Они не претендуют на всеохватность. Но могут внести некоторую ясность для человека, собирающегося выбрать облачно\vds-ный хостинг, но не имеющего никакого представления о рынке.
Поскольку я не учёл ещё целой кучи хороших хостингов, то я буду очень благодарен за комментарии, которые позволят пополнить этот список. А также ввиду того, что я не пользовался почти ни одним из нижеперечисленных хостингов, я буду рад поместить отзывы из первых рук в тело статьи, если таковые будут оставлены в комментариях.
Список упоминаемых хостингов: 1gb.ru, Hostingrails, RackspaceCloud, Mediatemple, Heroku, Amazon Web Services (шапочно), Engine Yard (шапочно), Altnet (привет с Хабрахабра), justhost.com (лучи поноса), Linode, Hetzner online (выделенный сервер), Server4you
cut и grep или awk?
2 min
Часто в скриптах можно встретить что-то вроде
Такой вызов awk всего лишь вывходит первую (n-ную) колонку из вывода предыдущей команды. Но это явный оверкилл! awk — довольно мощный язык потоковой обработки данных, и применение его как простого field-separator не есть хорошо.
Для вырезания из строки указанного поля лучше использовать команду cut. Она умеет меньше, а потому проще в использовании и быстрее.
В современном линуксе обработка вызова awk куда более сложна, чем вызов cut. В дебиане, например, awk — линк на /etc/alternatives/awk, который ведёт (чаще всего) на gawk. Который почти в 10 раз больше по размеру, чем cut. Разумееся, cut загружаеся быстрее.
cut умеет вырезать не только байты, но и нужные поля (опция -f). Поле — это текст между разделителями. По-умолчанию разделитель пробел/табуляция, но он легко меняется опцией -d.
Второй подход — использовать опцию -o у grep. Эта опция выводит не всю строку, а только совпадающее с критерием поиска grep. Очевидно бесполезно при поиске точной подстроки, но очень полезно при использовании регулярных выражений.
Например,
выведет список программ, запускающихся init'ом (четвёртое поле, поля разделяются двоеточием).
Или
выдаст список URL'ов из файла с ошибками (первый урл в строке).
… и никакого awk.
UPD: В комментариях подсказывают ещё более интересную конструкцию без запуска внешнего файла (команда read реализуеся средствами bash'а):
P.S. Речь не о единичном вызове (тут нет разницы awk, grep или даже python/perl). Речь о множестве вызовов в цикле в скрипте. Все примеры сравнивайте в цикле с сотнями (лучше тысячами) вызовов.
foobar|awk '{print $1}' («часто» — это действительно часто). Такой вызов awk всего лишь вывходит первую (n-ную) колонку из вывода предыдущей команды. Но это явный оверкилл! awk — довольно мощный язык потоковой обработки данных, и применение его как простого field-separator не есть хорошо.
Для вырезания из строки указанного поля лучше использовать команду cut. Она умеет меньше, а потому проще в использовании и быстрее.
В современном линуксе обработка вызова awk куда более сложна, чем вызов cut. В дебиане, например, awk — линк на /etc/alternatives/awk, который ведёт (чаще всего) на gawk. Который почти в 10 раз больше по размеру, чем cut. Разумееся, cut загружаеся быстрее.
cut умеет вырезать не только байты, но и нужные поля (опция -f). Поле — это текст между разделителями. По-умолчанию разделитель пробел/табуляция, но он легко меняется опцией -d.
Второй подход — использовать опцию -o у grep. Эта опция выводит не всю строку, а только совпадающее с критерием поиска grep. Очевидно бесполезно при поиске точной подстроки, но очень полезно при использовании регулярных выражений.
Например,
grep -v "#" /etc/inittab |cut -f 4 -d : -s выведет список программ, запускающихся init'ом (четвёртое поле, поля разделяются двоеточием).
Или
grep http://\\S\\+ -o /var/log/apache2/error.logвыдаст список URL'ов из файла с ошибками (первый урл в строке).
… и никакого awk.
UPD: В комментариях подсказывают ещё более интересную конструкцию без запуска внешнего файла (команда read реализуеся средствами bash'а):
foobar | (read p1 p2; echo p1)P.S. Речь не о единичном вызове (тут нет разницы awk, grep или даже python/perl). Речь о множестве вызовов в цикле в скрипте. Все примеры сравнивайте в цикле с сотнями (лучше тысячами) вызовов.
Как работают алгоритмы сортировки
1 min
Иногда для понимания того, как работает та или иная вещь, лучше один раз увидеть, чем сто раз услышать.
Замечательный сайт www.sorting-algorithms.com позволяет увидеть, как сортируются данные разными алгоритмами. Вы сможете посмотреть анимацию в зависимости от алгоритма, исходных данных.

Все это бегает и сортируется прямо на ваших глазах!
Работает на Google App Engine, видимо, поэтому и лежит от посетителей с «Хабра».
Замечательный сайт www.sorting-algorithms.com позволяет увидеть, как сортируются данные разными алгоритмами. Вы сможете посмотреть анимацию в зависимости от алгоритма, исходных данных.
Все это бегает и сортируется прямо на ваших глазах!
Работает на Google App Engine, видимо, поэтому и лежит от посетителей с «Хабра».
Система непересекающихся множеств и её применения
10 min
Добрый день, Хабрахабр. Это еще один пост в рамках моей программы по обогащению базы данных крупнейшего IT-ресурса информацией по алгоритмам и структурам данных. Как показывает практика, этой информации многим не хватает, а необходимость встречается в самых разнообразных сферах программистской жизни.
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было декартово дерево. В этот раз — система непересекающихся множеств. Она же известна под названиями disjoint set union (DSU) или Union-Find.
Поставим перед собой следующую задачу. Пускай мы оперируем элементами N видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
Формализируем задачу: создать быструю структуру, которая поддерживает следующие операции:
MakeSet(X) — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
Find(X) — возвратить идентификатор множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества — представителя множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству
Unite(X, Y) — объединить два множества, в которых лежат элементы X и Y, в одно новое.
На рисунке я продемонстрирую работу такой гипотетической структуры.
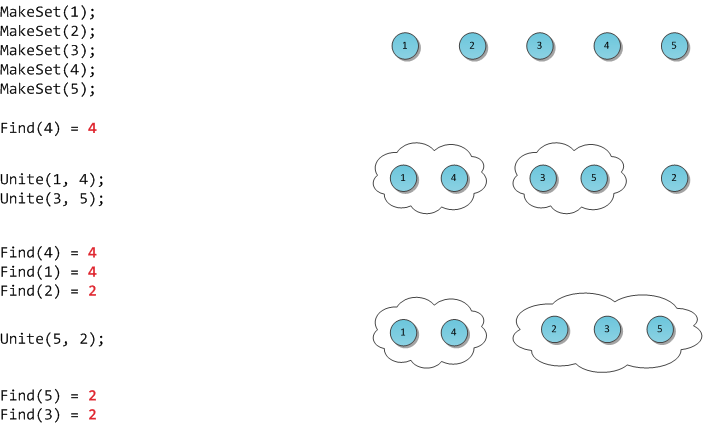
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было декартово дерево. В этот раз — система непересекающихся множеств. Она же известна под названиями disjoint set union (DSU) или Union-Find.
Условие
Поставим перед собой следующую задачу. Пускай мы оперируем элементами N видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
Формализируем задачу: создать быструю структуру, которая поддерживает следующие операции:
MakeSet(X) — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
Find(X) — возвратить идентификатор множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества — представителя множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству
if (Find(X) == Find(Y)).Unite(X, Y) — объединить два множества, в которых лежат элементы X и Y, в одно новое.
На рисунке я продемонстрирую работу такой гипотетической структуры.
HTML5 для веб-дизайнеров. Часть 4: Формы 2.0
11 min
Translation
HTML5 для веб-дизайнеров
- Краткая история языка разметки
- Модель HTML5
- Мультимедиа
- Формы 2.0
- Семантика
- HTML5 и современные условия
Когда браузеры стали поддерживать JavaScript, за ним быстро закрепились две основные задачи: эффекты при наведении мышью и улучшения для веб-форм. Потом в CSS появился псевдо-класс :hover и необходимость в скриптах для многих ситуаций первого плана отпала.
Эта история постоянно повторяется. Как только определенный шаблон или задача становятся достаточно популярными, они почти непременно в конце концов упрощаются в техническом плане и делаются более доступными. Именно так в CSS3 появилось много функций для создания простых анимаций, для которых прежде требовался JavaScript.
Говоря о формах, тут возможности CSS довольно ограничены. И теперь на сцену снова выходит HTML5. Следуя тому же принципу, он вводит новые функции, которые на самом деле вовсе не новые, но сделаны проще и удобнее.
Нетрудно догадаться, что прежде они были частью отдельной спецификации WHATWG под названием Web Forms 2.0.
HTML5 для веб-дизайнеров. Часть 3: Мультимедиа
14 min
Translation
HTML5 для веб-дизайнеров
- Краткая история языка разметки
- Модель HTML5
- Мультимедиа
- Формы 2.0
- Семантика
- HTML5 и современные условия
В истории всемирной сети каждый очередной виток перехода на новый уровень развития начинался с какого-нибудь технологического нововведения. Когда в HTML добавился элемент img, это в корне изменило облик сети. Затем введение JavaScript сделало ее более динамичной и интерактивной. Чуть позже появился Ajax, что открыло возможности для создания в сети полноценных приложений.
Современные веб-стандарты настолько продвинуты, что сейчас можно создать почти что угодно, используя лишь возможности HTML, CSS и JavaScript. Почти что угодно.
В спецификациях этих стандартов все еще есть пробелы. Так, если вы хотите сваять страницу с текстом и картинками, вы вполне обойдетесь HTML и CSS. Но если вам нужно опубликовать аудио или видео, тут неизбежно придется обратиться к сторонним технологиям — Flash или Silverlight.
Эти технологии — «плагины», эдакие «затычки», заполняющие «дыры» в сети. Они делают относительно простой публикацию игр, фильмов и музыки онлайн, но они не открыты и принадлежат и контролируются частными компаниями. Да, тот же Flash — мощный инструмент, но его применения в какой-то мере схоже со сделкой со злыми силами: мы получаем новые, недоступные другим путем, возможности, но взамен теряем часть свой независимости.
HTML5 призван восполнить этот недостаток. В данный момент он вступает в прямую конкуренцию с собственническими технологиями, вроде Flash и Silverlight, и главное его преимущество в этой борьбе — ему не требуется плагины, так как его мультимедиа-возможности «вшиты» в браузеры.
Консольный словарь sdcv
2 min
Очень часто, администраторам приходиться читать маны, которые, к сожалению, в большинстве случаев на английском языке. Конечно, большинство знают английский, и очень даже не плохо, но очень часто встречаются слова, которые очень трудно перевести. Хорошо, когда у вас под рукой есть какой-либо stardict или просто есть соединение с интернетом и можно глянуть перевод. А если нет? Или настраиваете сервер, и у вас только голая консоль без выхода в интернет. Понимаю, звучит фантастично, но в жизни всякое бывает. Или как в моем случае: мне нужен был простой словарик, который бы не висел в трее, не имел никаких лишних наворотов и гуев (пинок в сторону stardict) и был под рукой, ну или не далеко от нее. :) Вот именно для таких случаев (ну или вы просто заядлый Linux Geek и вам бы все в консоль) и есть консольный словарик sdcv — StarDict Console Version.
Эта небольшая софтина, размером в 155 КБ, к сожалению, есть далеко не в каждом Linux-дистрибутиве, так что возможно вам придется ее собрать самому, не думаю что это вызовет затруднение. :) Скачать ее можно тут — downloads.sourceforge.net/sourceforge/sdcv/sdcv-0.4.2.tar.bz2
Набрав в консоли
Казалось бы, зачем ради такой незначительной утилиты писать столько текста. Но если копнуть глубже и пораскинуть мозгами, то областей ее применения множество. Начиная от банальных переводов методом
Опций немного. Из интересных можно выделить парочку:
Эта небольшая софтина, размером в 155 КБ, к сожалению, есть далеко не в каждом Linux-дистрибутиве, так что возможно вам придется ее собрать самому, не думаю что это вызовет затруднение. :) Скачать ее можно тут — downloads.sourceforge.net/sourceforge/sdcv/sdcv-0.4.2.tar.bz2
Набрав в консоли
sdcv, мы получим предложение ввести слово или фразу и, после ее ввода и нажатия Enter, получим перевод и предложение ввести следующую фразу. И так до бесконечности. В случае, если у вас в системе установлено больше одного словаря, то он спросит, используя какой словарь ему следует переводить это слово или фразу. Для перевода программа использует словари stardict, так что они у вас должны быть. Если у вас их нет, вам надо будет их скачать и поместить в директорию со словарями. Казалось бы, зачем ради такой незначительной утилиты писать столько текста. Но если копнуть глубже и пораскинуть мозгами, то областей ее применения множество. Начиная от банальных переводов методом
ls | grep | sdcv и заканчивая использованием в скриптах. Опций немного. Из интересных можно выделить парочку:
-u для перевода слова используя какой-то конкретный словарь и -n для использования в скриптах. Кстати, назначение этой опции я либо не понял, либо неправильно использовал, но у меня ее результат выходил такой же, как если передать sdcv в качестве параметра слово для перевода.Почему Git
8 min
Было время, когда я ничего не знал про VCS, ни что это такое, ни тем более зачем это мне. И верхом своих достижений считал папочку с архивами версий. К моменту осознания необходимости системы контроля версий я уже набил шишек и прочувствовал необходимость такого инструмента. Но борландовский аналог CVS меня не впечатлил. У каждого файла свой номер версии. Как мне получить срез определенного релиза я так и не разобрался. А в это время SVN победоносно шла сквозь умы разработчиков. Черт, это было то, чего мне так не хватало. Прочитав доку и начав работать я просто влюбился в нее. Да, были трудности и определенные неудобства, но куда без них.
Так я и работал бы в SVN, но ничего не стоит на месте. В интернете уже потекли тонкие ручейки новостей про Git. Я не кидаюсь за каждой новой технологией, и прошло уже достаточно много времени, пока мне не прожужжали этим Git’ом все мозги. Мне стало любопытно, я вначале присматривался, примерялся, а потом плюнул и начал новый проект на Git. Мучался с ребятами 2 недели, накачал литературы, написал шпаргалку… ничего, привыкли, … а потом меня поперло.
Теперь меня регулярно просят рассказать про Git и что в нем такого. Уже надоело, поэтому этот пост для тех, кто еще сомневается.
Так я и работал бы в SVN, но ничего не стоит на месте. В интернете уже потекли тонкие ручейки новостей про Git. Я не кидаюсь за каждой новой технологией, и прошло уже достаточно много времени, пока мне не прожужжали этим Git’ом все мозги. Мне стало любопытно, я вначале присматривался, примерялся, а потом плюнул и начал новый проект на Git. Мучался с ребятами 2 недели, накачал литературы, написал шпаргалку… ничего, привыкли, … а потом меня поперло.
Теперь меня регулярно просят рассказать про Git и что в нем такого. Уже надоело, поэтому этот пост для тех, кто еще сомневается.
Как выглядит китайская клавиатура
8 min
Вы, вероятно, представляли ее себе как целый орган — грандиозное сооружение длиной в пару метров с сотнями и тысячами клавиш. На самом деле, большинство китайцев используют обычную клавиатуру с латинской раскладкой QWERTY. Но как с помощью нее можно набрать такое несметное количество различных иероглифов? Мы попросили рассказать об этом нашу сотрудницу Юлию Дрейзис. Ее с Китаем связывают и давняя любовь, и работа.
За несколько тысяч лет хитроумные китайцы успели довести количество иероглифов до 50000 с хвостиком. И хотя число нужных в повседневной жизни знаков не измеряется десятками тысяч, все равно, как ни крути, стандартный набор старой типографии — 9000 литер.
Долгое время набор осуществлялся по принципу «на каждый иероглиф — отдельный печатный элемент». Поэтому работать приходилось с машинками-монстрами вроде такой:

Печатная машинка фирмы «Шуангэ», 1947 год (принцип действия придуман японцем Киота Сугимото в 1915 году).
История вопроса: печатные машинки
За несколько тысяч лет хитроумные китайцы успели довести количество иероглифов до 50000 с хвостиком. И хотя число нужных в повседневной жизни знаков не измеряется десятками тысяч, все равно, как ни крути, стандартный набор старой типографии — 9000 литер.
Долгое время набор осуществлялся по принципу «на каждый иероглиф — отдельный печатный элемент». Поэтому работать приходилось с машинками-монстрами вроде такой:
Печатная машинка фирмы «Шуангэ», 1947 год (принцип действия придуман японцем Киота Сугимото в 1915 году).
This is my way to China (part 3)
5 min
После долгого перерыва — продолжаю свой рассказ. Начало — здесь и здесь. Конечно же, решение лежало на поверхности — придумать свою торговую марку, упаковку, а изготовление продукции — разместить по методу OEM (original equipment manufacturer) на специализированных фабриках и потом продвигать ее в России. Но это в теории все выглядит легко, а на практике нам пришлось попотеть изрядно.
Что и как покупать на Taobao
5 min

В нашей прошлой статье мы показали семь смешных товаров c китайского интернет-аукциона TaoBao, лишь вскользь упомянув о том, что же это такое. Пришло время подробнее рассказать о TaoBao, сравнить его с Ebay и поведать как можно удобно и недорого покупать на этом товарном торжестве победившего социализма
This is my way to China (part 2)
2 min
Продолжаю рассказ о моем пути в Китай. Тем, кто пропустил Part 1, рекомендую начать с нее.
В процессе становления дела нам казалось, что работа с известными производителями — это и есть надежность в бизнесе на долгие годы. Но очень скоро произошло следующее: в процессе роста — мы начали продвигать на рынок торговые марки различных расходных материалов, которые нам не принадлежали. Конечно, мы постоянно пытались получить заветный эксклюзивный контракт, но поставщики не очень-то шли нам навстречу.
Аргументы для отказа были разные: и наличие «более старых» клиентов в России и соответственно нежелание их потерять при заключении эксклюзивного контракта с нами, и наша неспособность выбирать у них весь ассортимент производимой продукции, и конечно, ежемесячный объем закупок. Вот здесь остановлюсь подробнее.
В процессе становления дела нам казалось, что работа с известными производителями — это и есть надежность в бизнесе на долгие годы. Но очень скоро произошло следующее: в процессе роста — мы начали продвигать на рынок торговые марки различных расходных материалов, которые нам не принадлежали. Конечно, мы постоянно пытались получить заветный эксклюзивный контракт, но поставщики не очень-то шли нам навстречу.
Аргументы для отказа были разные: и наличие «более старых» клиентов в России и соответственно нежелание их потерять при заключении эксклюзивного контракта с нами, и наша неспособность выбирать у них весь ассортимент производимой продукции, и конечно, ежемесячный объем закупок. Вот здесь остановлюсь подробнее.
This is my way to China (part 1)
3 min
Как и многие другие истории создания бизнеса – моя история, тоже началась, когда у меня -лопнуло терпение принимать «правила игры» от недалеких руководителей и чиновников, и слепо идти по жизни, навстречу судьбе.
Итак, на дворе — ноябрь 2005 года. Начало эры «углеводородной лихорадки». За моими плечами остались многие годы работы в структуре коммерческих отделов алкогольных компаний и ликеро-водочных заводов. А десятки выставок и командировок по городам нашей Родины — помогли накопить опыт, который в будущем — оказался для меня бесценным!
Итак, на дворе — ноябрь 2005 года. Начало эры «углеводородной лихорадки». За моими плечами остались многие годы работы в структуре коммерческих отделов алкогольных компаний и ликеро-водочных заводов. А десятки выставок и командировок по городам нашей Родины — помогли накопить опыт, который в будущем — оказался для меня бесценным!
WebHiTech ’2010. Вы уже используете HTML 5? Подайте хороший пример остальным!
3 min
 Уважаемые коллеги, приветствую! Рад объявить, хотя и с некоторым запозданием, о начале приема заявок на конкурс технологического совершенства сайтов WebHiTech, который проводится в этом году, подумать только, уже в третий раз.
Уважаемые коллеги, приветствую! Рад объявить, хотя и с некоторым запозданием, о начале приема заявок на конкурс технологического совершенства сайтов WebHiTech, который проводится в этом году, подумать только, уже в третий раз.Напомню, что наш конкурс нацелен на содействие распространению в Рунете практики разработки в духе уважительного отношения к современным веб-стандартам. С того момента, как конкурс был организован впервые, много воды утекло. Веб в технологическом плане заметно изменился. Сегодня уже мало кого из веб-стандартисткого сообщества удивишь качественной версткой в соответствии со спецификациями XHTML 1.0 Strict и CSS2.1 — для нас это уже в порядке вещей, хотя, к сожалению, для подавляющего большинства функционирующих в Рунете сайтов даже этот уровень по-прежнему является недостижимой планкой. Но время стремительно, неумолимо и не ждет тех, кто плетется в хвосте. Веб-разработчики, привыкшие творить на переднем крае прогресса, уже вовсю экспериментируют с HTML 5, создавая на его основе вполне жизнеспособные и самодостаточные проекты. Уже можно пользоваться такими «чудесами», как веб-шрифты, SVG и Canvas, геолокация и мн. др.
В прошлом году на наш конкурс не было заявлено ни одного проекта, созданного с использованием новых структурных элементов HTML 5. В нынешнем же году мы получили такую заявку в один из первых дней этапа выдвижения работ, и, надеемся, что она в своем роде далеко не последняя. Уверен, что жюри конкурса как-то по-особенному поддержит проекты, основанные на «технологиях будущего». Конечно же, по достоинству будут оценены и сайты, грамотно использующие просто современные технологии, «технологии настоящего». Итак, ждем ваших заявок на конкурс WebHiTech по версии 2010 года.
Функции наносят ответный удар
5 min
В этом топике хочу рассказать о подходе, который эксплуатирую уже несколько лет.
Сразу предупрежу, если Вы истовый фанат ООП, огромных конструкций и монструозных диаграмм классов, не читайте.
Вкратце, суть концепции — это перенос части unix way в программирование на PHP.
А конкретно, концепции простых программ, выполняющих одну функцию.
Сразу предупрежу, если Вы истовый фанат ООП, огромных конструкций и монструозных диаграмм классов, не читайте.
Вкратце, суть концепции — это перенос части unix way в программирование на PHP.
А конкретно, концепции простых программ, выполняющих одну функцию.
MapReduce или подсчеты за пределами возможностей памяти и процессора (попробую без зауми)
8 min
Давно хотел рассказать про MapReduce, а то как ни взгляшешь на подобное — такая заумь, что просто ужас берет, а на самом деле очень простой и полезный подход для многих целей. И реализовать самому — не так уж и сложно.
Сразу скажу — топик — для тех, кто не разобрался что такое MapReduce. Для тех, кто разобрался — полезного тут ничего не будет.
Начнем с того как собственно родилась лично у меня идея MapReduce (хотя я и не знал, что он так называется, и, разумеется, пришла она мне куда позже чем Гугловсцам).
Сначала опишу как она рождалась (подход был неправильный), а потом как надо правильно делать.
А родилась она, как и, наверное, везде — для подсчета частоты слов, когда обычной памяти не хватает (подсчет частоты всех слов в Википедии). Вместо слова «частота» тут скорее должно быть «количество вхождений», но для простоты оставлю «частота».
В самом простом случае мы можем завести хеш (dict, map, hash, ассоциативный массив, array() в PHP) и считать в нем слова.
Но что делать когда память под хеш кончится, а мы посчитали только одну сотую всех слов?
Сразу скажу — топик — для тех, кто не разобрался что такое MapReduce. Для тех, кто разобрался — полезного тут ничего не будет.
Начнем с того как собственно родилась лично у меня идея MapReduce (хотя я и не знал, что он так называется, и, разумеется, пришла она мне куда позже чем Гугловсцам).
Сначала опишу как она рождалась (подход был неправильный), а потом как надо правильно делать.
Как посчитать все слова в Википедии (неправильный подход)
А родилась она, как и, наверное, везде — для подсчета частоты слов, когда обычной памяти не хватает (подсчет частоты всех слов в Википедии). Вместо слова «частота» тут скорее должно быть «количество вхождений», но для простоты оставлю «частота».
В самом простом случае мы можем завести хеш (dict, map, hash, ассоциативный массив, array() в PHP) и считать в нем слова.
$dict['word1'] += 1Но что делать когда память под хеш кончится, а мы посчитали только одну сотую всех слов?
HTML5 для веб-дизайнеров. Часть 2: Модель HTML5
12 min
Translation
HTML5 для веб-дизайнеров
- Краткая история языка разметки
- Модель HTML5
- Мультимедиа
- Формы 2.0
- Семантика
- HTML5 и современные условия
Великая Французская революция была временем радикальных политических и социальных преобразований. Времени как такового они тоже коснулись: в определенный период своего существования Французская Республика жила по новой системе — в сутках было 10 часов по сто минут каждый. Очевидно, что она была была куда логичнее и «правильнее» привычной шестидесятеричной.
Вместе с тем, она была полным провалом. Никто ей не пользовался.
То же самое можно сказать и про XHTML 2. W3C только лишний раз доказал то, чему нас научил урок послереволюционной Франции: изменить привычки людей по приказу очень-очень трудно.
Почему текст, набранный заглавными буквами, трудно читать
2 min

Неизвестно откуда пошла мода на оформление текста заглавными буквами, но факт остается фактом – использование заглавных букв окружает нас повсеместно. Если вы напишете в интернете текст прописными, люди решат, что вы кричите, или усомнятся в вашем психическом здоровье. Но чаще всего все прописные раздражают людей, а текст написанный таким образом очень трудно быстро прочесть.
Тормозной SQLite? Совсем нет!
2 min
Как-то заинтересовавшись SQLite я решил проверить, а не будет ли оно быстрее MySQL, или хотя бы равным по скорости.
Я исходил из того, что SQLite скорее всего будет удобна для мелких таблиц, типа простых счетчиков посещений.
Поэтому провел тесты следующим способом: я пять раз мерял время по 100 циклов обновления записи в базе и пять раз по 100 чтения.
Код
Я исходил из того, что SQLite скорее всего будет удобна для мелких таблиц, типа простых счетчиков посещений.
Поэтому провел тесты следующим способом: я пять раз мерял время по 100 циклов обновления записи в базе и пять раз по 100 чтения.
Код
тут.