3D лазерный сканер на Android телефоне
6 min

Представляю вниманию DIY сканер на базе Android смартфона.
При проектировании и создании сканера, в первую очередь, интересовало сканирование крупных объектов. Минимум – фигура человека в полный рост с точность – хотя бы 1-2 мм.
Данные критерии успешно достигнуты. Успешно сканируются объекты при естественном освещении (без прямого солнечного света). Поле сканирования определяется углом захвата камеры смартфона и расстоянием, на котором лазерный луч сохраняет достаточную для детектирования яркость (днем в помещении). Это фигура человека в полный рост (1.8 метров) с шириной захвата в 1.2 метров.
Сканер был сделан из соображений «а не сделать ли что ни будь более или менее полезное и интересное, когда заняться нечем». Все иллюстрации – на примере «тестового» объекта (выкладывать сканы людей не корректно).
Как показал опыт, для сканера такого типа ПО — это вторично и на него было потрачено меньше всего времени (на окончательный вариант. Не считая эксперименты и тупиковые варианты). Поэтому в статье особенностей ПО касаться не буду (Ссылка на исходные коды в конце статьи.)
Цель статьи – рассказать о тупиковых ветках и проблемах, собранных на пути к созданию окончательной рабочей версии.


 В продолжение своей вчерашней статьи на Geektimes хочу рассказать подробнее про реализацию оцифровки и кодирования звука на микроконтроллере STM32.
В продолжение своей вчерашней статьи на Geektimes хочу рассказать подробнее про реализацию оцифровки и кодирования звука на микроконтроллере STM32. 

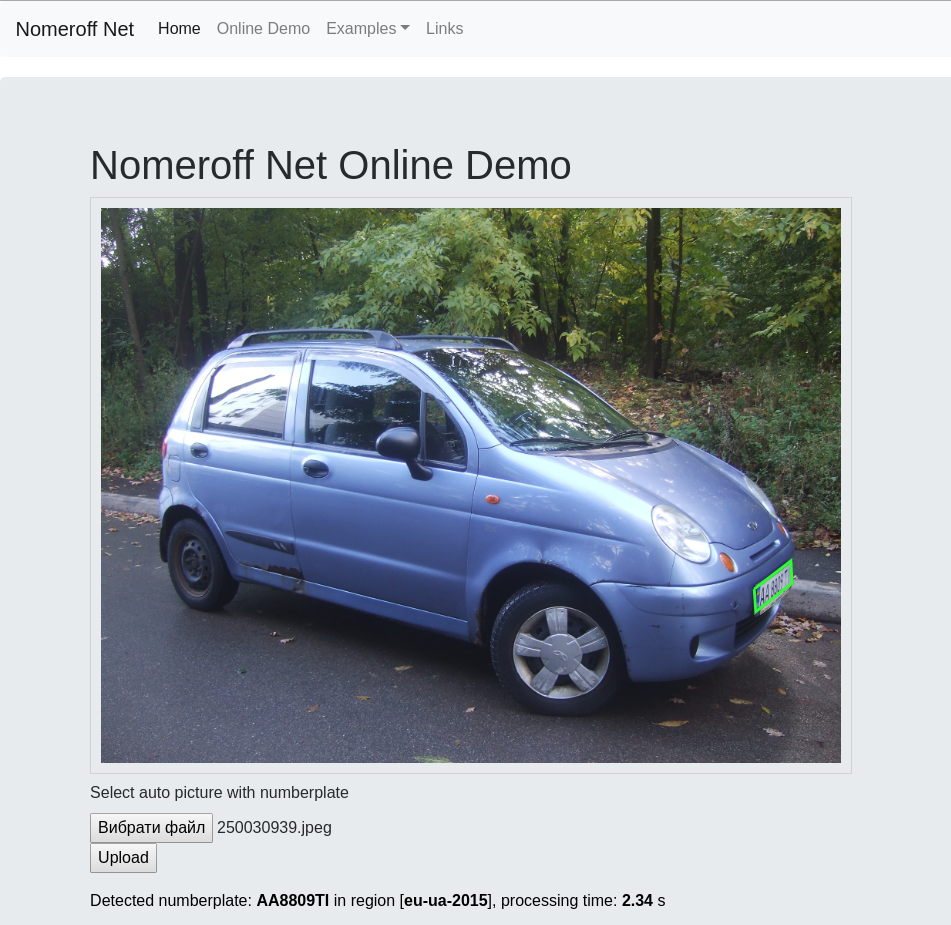

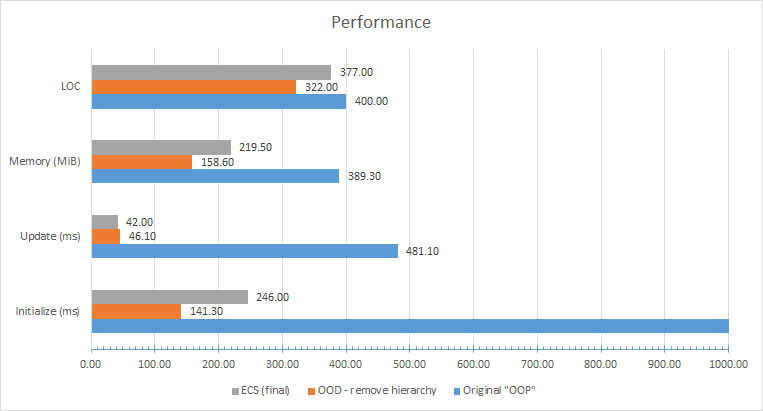
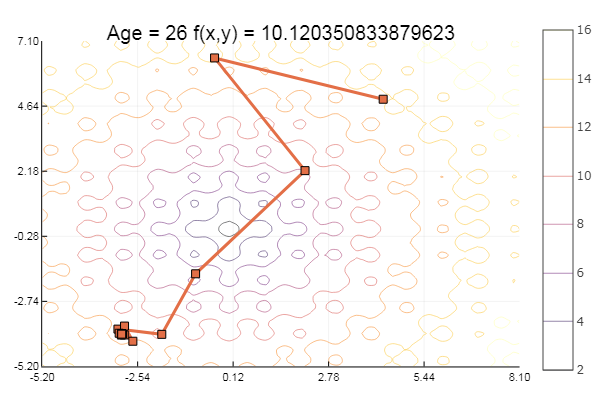

 Вкратце: статья будет полезна тем программистам, кто уже заинтересовался релевантным поиском и прочитал статьи по стартовой установке сфинкс поиска, погонял на тестовых примерах и таких же синтетических задачах. Часто эти примеры не дают ответа на вопрос, а как же ощутить реальную пользу от поискового модуля Sphinx в сравнении с другими более простыми вариантами поиска. Примеры кода в статье — на php+smarty, Sphinx 2.0.1-beta, база данных — mysql, исходники и дамп структуры базы выложены отдельным архивом в подвале. В статье описан пример использования таких особенностей сфинкса, как:
Вкратце: статья будет полезна тем программистам, кто уже заинтересовался релевантным поиском и прочитал статьи по стартовой установке сфинкс поиска, погонял на тестовых примерах и таких же синтетических задачах. Часто эти примеры не дают ответа на вопрос, а как же ощутить реальную пользу от поискового модуля Sphinx в сравнении с другими более простыми вариантами поиска. Примеры кода в статье — на php+smarty, Sphinx 2.0.1-beta, база данных — mysql, исходники и дамп структуры базы выложены отдельным архивом в подвале. В статье описан пример использования таких особенностей сфинкса, как: