
2 дня унижения в чатах, пачка Ново-Пассита, но я выдержал это испытание и узнал, что до сих пор думают о фронтенд разработчиках «другие» разработчики. Будет интересно.

User
2 дня унижения в чатах, пачка Ново-Пассита, но я выдержал это испытание и узнал, что до сих пор думают о фронтенд разработчиках «другие» разработчики. Будет интересно.

Текст написан иностранным агентом – лицом, проживающим за пределами России (в Канаде). Иллюстрации взяты из открытых источников - если не указано иное, из Википедии.
В этой статье будет немного про компьютерные методы, чуть побольше – про комбинаторику, но в основном – про то, что оба подхода не всесильны и у обоих есть свои ограничения.
Это хорошо видно на примере изучения древних письменностей острова Крит, из которых была дешифрована только одна – наиболее позднее Линейное письмо В (и то не до конца). Что же касается более ранних надписей, то тут есть многочисленные нюансы…

Рецепт параллельных вычислений Fork/Join или Map/Reduce:
- разбить задачу на куски;
- посчитать куски по-отдельности;
- склеить вместе.
Неотрицательная сумма (a, b) -> max(0, a + b) неассоциативна и результат зависит от порядка склейки. Она сломает Fork/Join и результат будет некорректен. Магией моноида починить на Java, SQL и Haskell за 5 минут, но
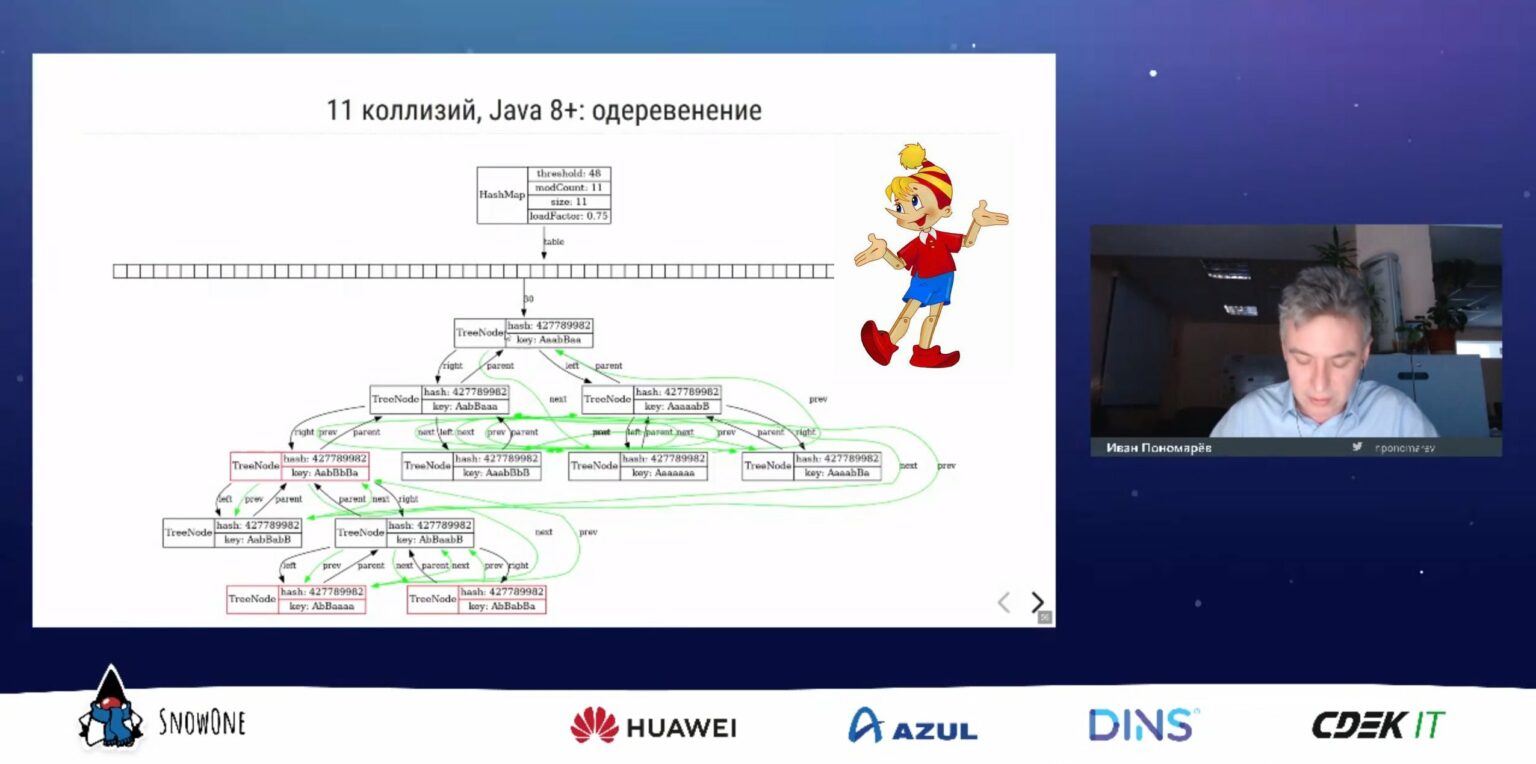
Эта статья является пересказом моего доклада на Java-конференции SnowOne 2021 года. LJV — проект, созданный в 2004 году как инструмент для преподавания языка Java студентам. Он позволяет визуализировать внутреннее устройство структур данных. В этом докладе я запускаю LJV на разных структурах (от String до ConcurrentSkipListMap) в разных версиях Java и разбираю, что там внутри, как оно менялось от версии к версии, и как это всё работает.

Можете ли вы уверенно сказать, что будет выведено на консоль в результате выполнения следующего кода?

Насколько человеческое восприятие, как умение формировать или представлять целостную картину, полагаясь лишь на силуэт или фрагмент объекта, эффективно? Почему эффективность важна, как оценить эффективность и что является параметрами эффективности в контексте восприятия?
Поскольку предмет исследования человеческое мышление - мышление образами, наиболее простым и продуктивным подходом будет формирование изолированной среды в виде логических задач на основе визуального восприятия.


Здорово, когда на работе можно заниматься не только важными и серьёзными делами, но и чем-то интересным, пусть и без явной пользы. Наши деврелы активно поддерживают эту позицию и время от времени подкидывают идеи каких-нибудь забавных штук. В этот раз было так: «А давайте возьмём рецепты новогодних салатов и напишем их кодом?».
«А давайте», — подумал я. У нас как раз код-фриз и заниматься продуктовыми задачами нельзя. А окунуться в новогоднее настроение — можно :)


В наше время все развивается с бешеной скоростью, а вместе с этим и постоянно меняются процессы. Такие темпы, мягко говоря, заставляют нас частенько попотеть, потому что релиз ждут еще вчера. В этих условиях нашему подразделению из центра компетенций ERP была поставлена задача по созданию проги для отражения аналитики и управления операциями по базе бухгалтерии. Если чуть подробнее, то от ПО требовалось по прописанным алгоритмам отражать аналитическую информацию и иметь пульт управления бухгалтерскими проводками (FI-документами) по всей базе за отчетные периоды.
Бизнес-процесс, который мы должны были автоматизировать, занимал месяцы, а от нашей разработки ожидали сокращения срока до нескольких часов, с отсутствием трудозатрат. При этом процесс требовалось изменить не только со стороны технической реализации, но и усовершенствовать с точки зрения бизнес-логики.
В таком виде эта задача упала к нам от заказчика: реализовать возможность для пользователя произвести процесс создания большого количество записей в учетной системе ERP при нажатии всего лишь одной кнопки. При этом, чтобы он мог при необходимости отменить созданные операции. Все же любят план «Б».
Первое, что пришло в голову — это безумие. Казалось, нам дали безумное требование, чтобы прога отрабатывала за 2 часа. При этом для создания всех операций из ТЗ требовалось настолько много системных ресурсов, что систему могло и парализовать и сделать работу пользователей в системе дискомфортной настолько, насколько это возможно. Это первая часть беды, а вторая — ПО являлось еще и аналитическим инструментом для принятия решений, что затрудняло вывод всего списка операций в ALV из-за их огромного количества записей.

Публикуем третью часть перевода материала о быстром алгоритме сортировки. Вот, на всякий случай, ссылки на первую и вторую части. В тех материалах мы говорили о теории сортировки, об особенностях работы нового алгоритма, разбирали тесты его производительности. Сегодня речь пойдёт о проблемах алгоритма, автор даст ответы на некоторые вопросы и поделится планами на будущее.
Прим. Wunder Fund: ну, вы наверное, и сами догадываетесь, как мы любим быстрые алгоритмы и оптимизации. Если вы тоже такое любите — вы знаете, что делать)
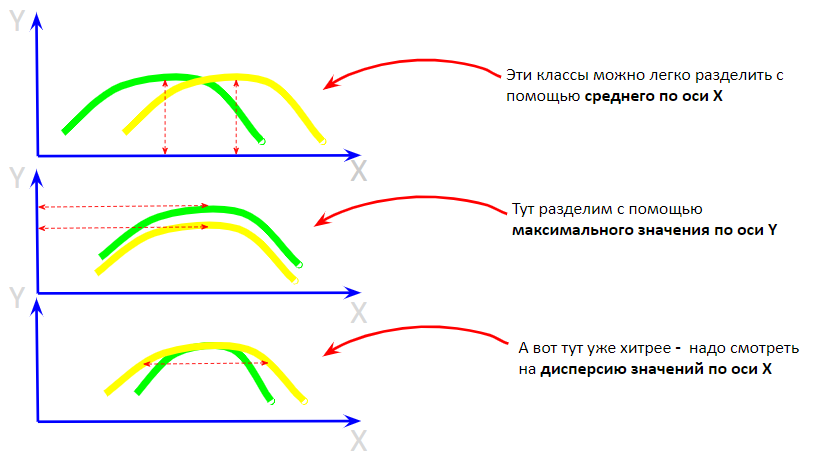
Разберем способы поднять точность модели!
Привет, чемпион! Возможно, перед тобой сейчас стоит задача построить предиктивную модель, или ты просто фармишь Kaggle, и тебе не хватает идей, тогда эта статья будет тебе полезна!
Наверное, уже только ленивый не слышал про Data Science и то, как модели машинного обучения помогают прогнозировать будущее, но самое крутое в анализе данных, на мой взгляд, - это хакатоны! Будь-то Kaggle или локальные соревнования, везде примерно одна задача - получить точность выше, чем у других оппонентов (в идеале еще пригодную для продакшена модель). И тут возникает проблема...
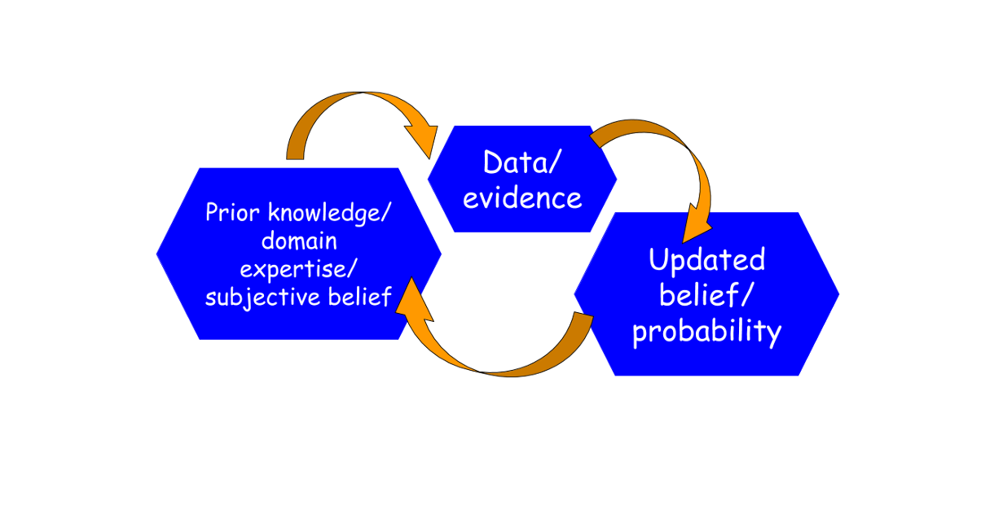
В этой статье мы рассказываем об основах и применении одного из самых мощных законов статистики - теоремы Байеса.
Мы продемонстрируем применение правила Байеса на очень простом, но практичном примере тестирования на наркотики и реализуем расчеты на языке програмирования Python. Мы также проиллюстрируем, как ограничения теста влияют на прогнозируемую вероятность и что в тесте необходимо улучшить, чтобы получить результат с высокой степенью достоверности.
Мы также покажем истинную силу байесовских рассуждений и как несколько байесовских вычислений можно объединить в цепочку, чтобы вычислить общую апостериорную вероятность.

Текст написан иностранным агентом – лицом, проживающим за пределами России (в Канаде)
За пару дней до Рождества на Хабре появился пост про транслитерацию польского языка кириллицей. Хотя идея на первый взгляд выглядит всего лишь как занимательное развлечение, на практике с задачами подобного рода периодически сталкиваются лингвисты. Когда лингвисту необходимо сравнить лексику родственных языков (особенно когда речь идёт о массовом сравнении в рамках корпусной лингвистики), сравниваемые языки нужно для начала «привести к общему знаменателю», то есть передать в единой графике, чаще всего латинице, чтобы облегчить сравнение. Даже с учётом неизбежных расхождений между орфографией и произношением (как в английском и французском языках) единая система письма сильно упрощает задачу сравнения. И не только сравнения, но и изучения. Скажем, если Вы начали учить язык с совершенно незнакомой системой письма (корейский, китайский, санскрит и т.п.), наверняка первые изученные Вами слова и фразы будут записаны в транслитерации латиницей (а то и кириллицей).
Ни кириллица, ни латиница не является единой унифицированной системой письма. В каждом языке, использующем кириллицу или латиницу, есть свои правила произношения того или иного знака, весьма отличные друг от друга. Но кроме того, существуют многочисленные дополнительные знаки для звуков, присутствующих в одном языке, но отсутствующих в другом. К примеру, звук «ш» существует во многих европейских языках, но создать единую букву для него в латинице так и не сподобились. Где-то обходятся сочетаниями (sh в английском и албанском, sch в немецком, ch во французском, sz в польском, sc в итальянском, sj в шведском, si или se – в ирландском), где-то под этот звук «переопределили» базовые буквы латиницы (x в португальском, старая знакомая s – в венгерском), где-то изобрели новые буквы путём добавления надстрочных или подстрочных значков к старым (š в чешском, словацком и балтийских, ş в турецком, ș в румынском – приглядевшись под микроскопом, увидите, что знак немного отличается от турецкого; и даже в искусственном языке эсперанто придумали свой знак ŝ). Некоторым языкам повезло – в них этого звука вообще нет, как не было его в латыни (отчего, собственно, и возникли эти проблемы с изобретением дополнительного символа).
Всем привет, я — Сергей Бобрецов, CTO в Wildberries.
Сегодня Wildberries — самый большой маркетплейс в России и мы так часто заняты повседневным хайлоадом, что не всегда успеваем рассказать что за всем этим стоит: какие технологии и решения под капотом, как мы справляемся с адом черной пятницы и ужасами киберпонедельника.
Стоит начать с того, что основным генератором прогресса в WB с самого начала и по сей день является фактор роста. По бизнес-метрикам мы растем примерно х2 каждый год уже много лет, а по техническим (количестуву запросов / транзакций / трафику / объему данных и т. д.) — рост может быть даже быстрее, и это создает множество вызовов: технических, архитектурных и организационных.
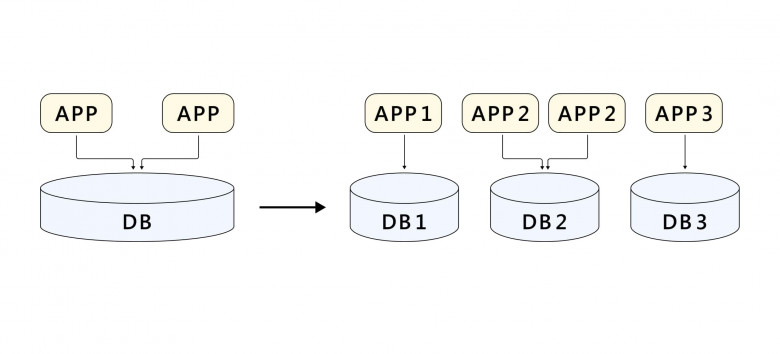
В итоге, чтобы запустить любую программу или систему в прод на мало-мальски долгий срок нужно обязательно учитывать кратный рост нагрузки, иначе совсем скоро придется вносить серьезные изменения в архитектуру или вообще все переделывать. Речь, конечно, не только про код – надо иметь стратегию масштабирования на уровне железа, сети, данных, самого приложения, команды и т. д.
Сегодня я хочу рассказать немного про нашу инфраструктуру.
На КДПВ в гостях у TalkPython вы видите Гвидо ван Россума — создателя Python, Марка Шеннона, план ускорения Python в 5 раз за 4 года и, конечно, автора подкаста. А мы делимся подборкой пакетов Python, о которых шла речь в выпусках за уходящий год.

Хотел бы написать небольшой цикл статей посвященных тому, как я написал свою RTOS с какими трудностями столкнулся и зачем вообще писать свою RTOS если уже есть FreeRTOS, RTX, embOS и т.д. список достаточно большой.
Начнем с того, что по мере работы я сталкивался с тем, что часть разработчиков (и я в том числе когда-то и сам) относятся к RTOS как к некоторому черному магическому ящику, мол что-то там происходит как-то все это работает и лучше туда не лесть, а то поломается ящик и проекту «ХАНА». И все хорошо пока хорошо, но как только появляются проблемы, то начинаются бессонные ночи с отладчиком, сроки по проекту горят, а самое главное и коварное, что ошибки в RTOS отловить крайне сложно. Зачастую они имеют плавающий характер и такие эффекты как переполнение стека, инверсия приоритетов, взаимные блокировки, и все, что связанное со средствами синхронизации отладить крайне сложно.
Cо всем этим я решил разобраться в корне, и чисто в академичесеких целях начал писать свою RTOS, чтобы так сказать прочувствовать все изнутри.
В итоге, оказалось, что написать RTOS ни так уж и сложно как кажется. И есть один существенный плюс, когда пишешь все сам и осознанно, то на поиск артефактов в виде багов уходит гораздо меньше времени (пара часов или полдня максиму). Кроме того открываются внутренние чакры и начинаешь чувствовать как работают другие RTOS в чем плюсы или минусы разных RTOS, в общем возникает чувство явного прозрения.
При написании RTOS, я осознанно отказался от поддержки проприетарных архитектур как AVR, PIC и мой выбор пал на семействе CORTEX, поскольку cortex-mX, на сегодня самая распространенная архитектура в Embedded.

Знакомо состояние перманентной усталости и низкого удовлетворения собственными результатами и отдачей от работы? У меня такое продолжалось пару лет, и я полностью выгорел и уволился из Яндекса.
Как так произошло? Я не супер вджобывал, чрезмерного внешнего давления тоже не было, в отпуска ездил регулярно. Но почему-то стресс копился и в итоге достиг критической массы.
Ошибки, приведшие к такому результату, довольно типичны. Их я и разберу в этой статье — вдруг кому-то поможет избежать таких же граблей.

22 ноября 2021 года президент Владимир Путин подписал закон № 377-ФЗ, который внес в Трудовой кодекс три новые статьи (ст. 22.1 — 22.3). Они регулируют правила электронного документооборота в организации. Давайте разберемся, что стало причиной их принятия и как теперь организации и индивидуальные предприниматели обязаны будут вести кадровое делопроизводство в цифровом виде.
Зачем вообще понадобилось принимать эти изменения?
Дело в том, что долгое время вопрос о законности применения электронных документов в вопросах кадрового делопроизводства вызывал самые противоречивые мнения как у специалистов, так и у органов власти. До начала пандемии, например, даже Минтруда России в своем письме указывало, что право работодателя, какую форму ведения документации ему выбирать — бумажную или электронную — не распространяется на те документы, которые либо предоставляются под роспись работнику, либо прямо предусмотрены ТК: такие документы могут быть исключительно бумажными (письмо от 06.03.2020 N 14-2/ООГ-1773). Подобная же точка зрения имела место быть и у многих региональных судов — в Белгороде, Екатеринбурге, Омске и других городах.
Во время весеннего локдауна позиция министерства начала постепенно меняться. Чиновники начали допускать возможность обмена электронными документами между работодателем и работником, при условии того, что потом они будут оформлены нормативно в надлежащем порядке (см. например, п. 3 письма Минтруда РФ от 27.03.2020 N 14-4/10/П-2741, информацию Роструда от 27.04.2020 (п. 12) и т.д.)

Всем привет! Меня зовут Максим, и я работаю бизнес-аналитиком на проекте Швейцарских Железных Дорог. За последние пять лет я описал больше четырех сотен пользовательских историй, экспериментируя со структурой и форматом. Под катом рассказ о том, какие проблемы у меня возникали, и как их удалось решить.