В 1998 году Лоуренс Пейдж, Сергей Брин, Раджив Мотвани и Терри Виноград опубликовали статью «The PageRank Citation Ranking: Bringing Order to the Web», в которой описали знаменитый теперь алгоритм PageRank, ставший фундаментом Google. Спустя чуть менее двух десятков лет Google стал гигантом, и даже несмотря на то, что его алгоритм сильно эволюционировал, PageRank по-прежнему является «символом» алгоритмов ранжирования Google (хотя только немногие люди могут действительно сказать, какой вес он сегодня занимает в алгоритме).
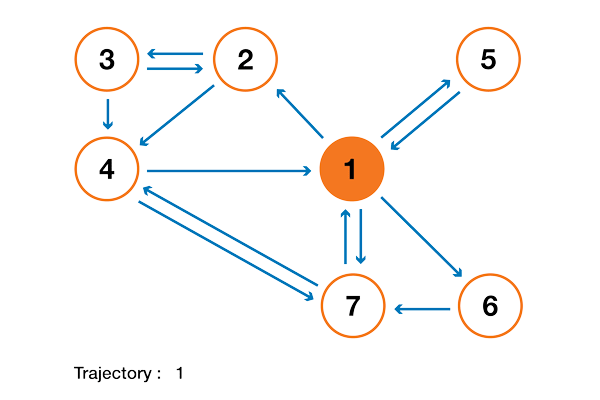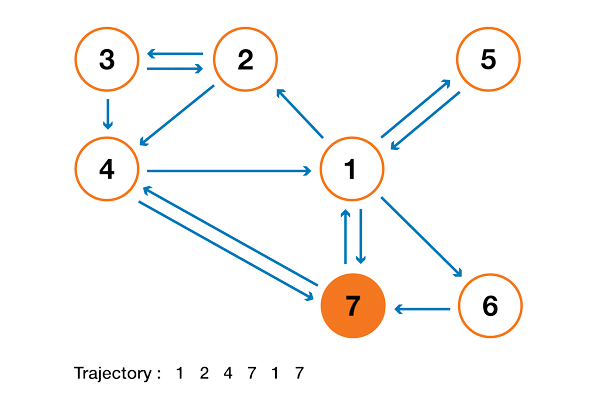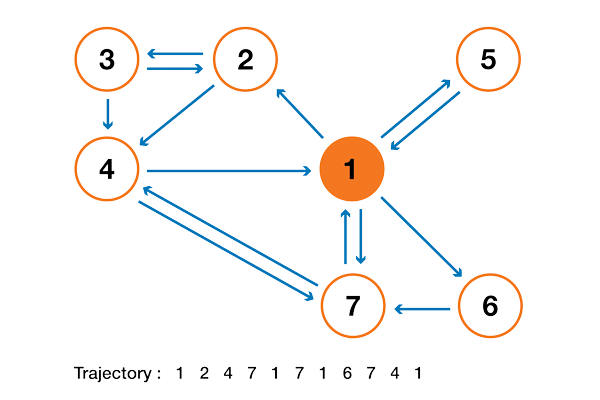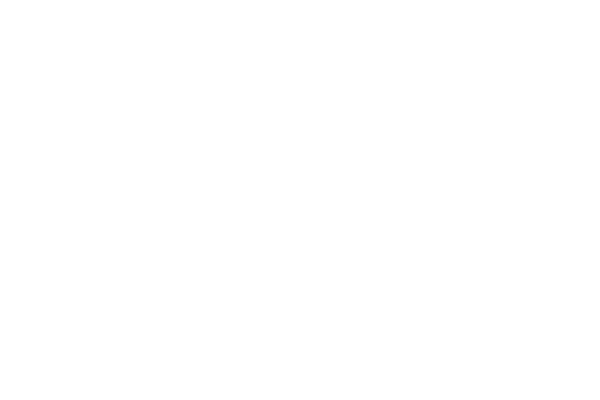
С теоретической точки зрения интересно заметить, что одна из стандартных интерпретаций алгоритма PageRank основывается на простом, но фундаментальном понятии цепей Маркова. Из статьи мы увидим, что цепи Маркова — это мощные инструменты стохастического моделирования, которые могут быть полезны любому эксперту по аналитическим данным (data scientist). В частности, мы ответим на такие базовые вопросы: что такое цепи Маркова, какими хорошими свойствами они обладают, и что с их помощью можно делать?