Работая над статьей «Глубокое обучение на R...», я несколько раз встречал упоминание t-SNE — загадочной техники нелинейного снижения размерности и визуализации многомерных переменных (например, здесь), был заинтригован и решил разобраться во всем в деталях. t-SNE это t-distributed stochastic neighbor embedding. Русский вариант с «внедрением соседей» в некоторой мере звучит нелепо, поэтому дальше буду использовать английский акроним.

Pavel Danilov @Pashtetikusread-only
User
Kaggle Mercedes и кросс-валидация
18 min

Всем привет, в этом посте я расскажу о том, как мне удалось занять 11 место в конкурсе от компании Мерседес на kaggle, который можно охарактеризовать как лидера по количеству участников и по эпичности shake-up. Здесь можно ознакомиться с моим решением, там же ссылка на github, здесь можно посмотреть презентацию моего решения в Yandex.
В этом посте пойдет речь о том, как студент консерватории попал в data science, стал призером двух подряд kaggle-соревнований, и каким образом методы математической статистики помогают не переобучиться на публичный лидерборд.
Начну я с того, что немного расскажу о задаче и о том, почему я взялся ее решать. Должен сказать, что в data science я человек новый. Лет 7 назад я закончил Физический Факультет СПбГУ и с тех пор занимался тем, что получал музыкальное образование. Идея немного размять мозг и вернуться к техническим задачам впервые посетила меня примерно два года назад, на тот момент я уже работал в оркестре Московской Филармонии и учился на 3 курсе в Консерватории. Начал я с того, что вооружившись книгой Страуструпа стал осваивать C++. Далее были конечно же разные онлайн курсы и примерно год назад я стал склоняться к мысли о том, что Data Science — это пожалуй именно то, чем я хотел бы заниматься в IT. Мое “образование” в Data Science — это курс от Яндекса и Вышки на курсере, несколько курсов из специализации МФТИ на курсере и конечно же постоянное саморазвитие в соревнованиях.
Отжиг и вымораживание: две свежие идеи, как ускорить обучение глубоких сетей
4 min
Translation
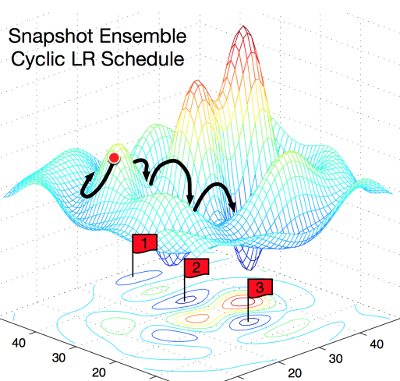
В этом посте изложены две недавно опубликованные идеи, как ускорить процесс обучения глубоких нейронных сетей при увеличении точности предсказания. Предложенные (разными авторами) способы ортогональны друг другу, и могут использоваться совместно и по отдельности. Предложенные здесь способы просты для понимания и реализации. Собственно, ссылки на оригиналы публикаций:
Библиотеки для глубокого обучения Theano/Lasagne
14 min
Tutorial
 Привет, Хабр!
Привет, Хабр!
Параллельно с публикациями статей открытого курса по машинному обучению мы решили запустить ещё одну серию — о работе с популярными фреймворками для нейронных сетей и глубокого обучения.
Я открою этот цикл статьёй о Theano — библиотеке, которая используется для разработки систем машинного обучения как сама по себе, так и в качестве вычислительного бекэнда для более высокоуровневых библиотек, например, Lasagne, Keras или Blocks.
Theano разрабатывается с 2007 года главным образом группой MILA из Университета Монреаля и названа в честь древнегреческой женщины-философа и математика Феано (предположительно изображена на картинке). Основными принципами являются: интеграция с numpy, прозрачное использование различных вычислительных устройств (главным образом GPU), динамическая генерация оптимизированного С-кода.
kaggle: IEEE's Camera Model Identification
7 min
В конце зимы этого года прошло соревнование IEEE's Signal Processing Society — Camera Model Identification. Я участвовал в этом командном соревновании в качестве ментора. Об альтернативном способе формирования команды, решении и втором этапе под катом.

Вижу, значит существую: обзор Deep Learning в Computer Vision (часть 1)
17 min
Компьютерное зрение. Сейчас о нём много говорят, оно много где применяется и внедряется. И как-то давненько на Хабре не выходило обзорных статей по CV, с примерами архитектур и современными задачами. А ведь их очень много, и они правда крутые! Если вам интересно, что сейчас происходит в области Computer Vision не только с точки зрения исследований и статей, но и с точки зрения прикладных задач, то милости прошу под кат. Также статья может стать неплохим введением для тех, кто давно хотел начать разбираться во всём этом, но что-то мешало ;)

Основы deep learning на примере дебага автоэнкодера, часть №1
16 min
Tutorial
Если почитать обучение по автоэнкодерам на сайте keras.io, то один из первых посылов там звучит примерно так: на практике автоэнкодеры почти никогда не используются, но про них часто рассказывают в обучалках и народу заходит, поэтому мы решили написать свою обучалку про них:
Their main claim to fame comes from being featured in many introductory machine learning classes available online. As a result, a lot of newcomers to the field absolutely love autoencoders and can't get enough of them. This is the reason why this tutorial exists!
Тем не менее, одна из практических задач, для которых их вполне себе можно применять — поиск аномалий, и лично мне в рамках вечернего проекта потребовался именно он.
На просторах интернетов есть очень много туториалов по автоэнкодерам, нафига писать еще один? Ну, если честно, тому было несколько причин:
- Сложилось ощущение, что на самом деле туториалов примерно 3 или 4, все остальные их переписывали своими словами;
- Практически все — на многострадальном MNIST'е с картинками 28х28;
- На мой скромный взгляд — они не вырабатывают интуицию о том, как это все должно работать, а просто предлагают повторить;
- И самый главный фактор — лично у меня при замене MNIST'а на свой датасет — оно все тупо переставало работать.
Дальше описан мой путь, на котором набиваются шишки. Если взять любую из предложенных плоских (не сверточных) моделей из массы туториалов и втупую ее скопипастить — то ничего, как это ни удивительно, не работает. Цель статьи — разобраться почему и, как мне кажется, получить какое-то интуитивное понимание о том, как это все работает.
Я не специалист по машинному обучению и использую подходы, к которым привык в повседневной работе. Для опытных data scientists наверное вся эта статья будет дикой, а для начинающих, как мне кажется, может что-то новое и встретится.
Мениски в коленном суставе — что это, зачем это, как это лечится если повредилось?
7 min
Решил сегодня поделиться с сообществом небольшой статьей, продолжающей знакомство с ортопедией и биомеханикой. Тема разговора – мениски коленного сустава. Что это такое, зачем они нужны, почему они такие важные и какие современные тенденции в лечении повреждений менисков.
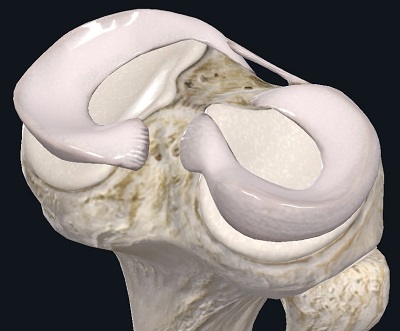
Цель данной статьи – информированность людей.
Кому интересно – заходим под кат.
Цель данной статьи – информированность людей.
Кому интересно – заходим под кат.
Что такое *args и **kwargs в Python?
4 min
Translation
Функции — это жизнь. Правда? Если вы только начали осваивать Python, неважно — первый ли это ваш язык программирования, или вы пришли в Python из другого языка, то вы уже знаете о том, что количество параметров в объявлении функции соответствует количеству аргументов, которые передают функции при вызове.

Это — основы. Это то, что помогает людям понимать окружающий мир. Но утверждение «количество параметров равно количеству аргументов» закладывает в голову новичка бомбу замедленного действия, которая срабатывает после того, как он увидит в объявлении функции таинственные конструкции
Не позволяйте всяким значкам загонять себя в ступор. Тут нет ничего архисложного. В общем-то, если эти конструкции вам незнакомы — предлагаю с ними разобраться.
Это — основы. Это то, что помогает людям понимать окружающий мир. Но утверждение «количество параметров равно количеству аргументов» закладывает в голову новичка бомбу замедленного действия, которая срабатывает после того, как он увидит в объявлении функции таинственные конструкции
*args или **kwargs.Не позволяйте всяким значкам загонять себя в ступор. Тут нет ничего архисложного. В общем-то, если эти конструкции вам незнакомы — предлагаю с ними разобраться.
Smart IDReader SDK — как написать Telegram-бота на Python для распознавания документов за 5 минут
4 min

Мы, Smart Engines, продолжаем цикл статей про то, как встроить наши технологии распознавания (паспортов, банковских карт и других) в ваши приложения. Ранее мы уже писали про встраивание на iOS и Android, а сегодня мы расскажем про то, как работать с Python-интерфейсом библиотеки распознавания Smart IDReader и напишем простого Telegram-бота.
Кстати, список поддерживаемых нами языков программирования расширился и теперь включает C++, C, C#, Objective-C, Swift, Java, Python, а также такие эзотерические языки, как Visual Basic и, разумеется, PHP. Как и раньше, мы поддерживаем все популярные и многие непопулярные операционные системы и архитектуры, а наши бесплатные приложения доступны для скачивания из App Store и Google Play.
По традиции, демо-версия Smart IDReader SDK для Python вместе с исходным кодом реализации Telegram-бота выложены на Github и доступны по ссылке.
Как я писал telegram-бота и заливал его на удаленный сервер
7 min
Вступление
Как только на территории РФ вступил в силу запрет на анонимность в мессенджерах, у меня дошли руки написать пост про telegram-бота. По ходу создания бота столкнулся с большим количеством проблем, которые пришлось решать по отдельности, и буквально выцеживать крупинки информации со всего интернета. И вот после нескольких месяцев страданий и мучений (кодинг – не основное моё занятие) я наконец-то закончил с ботом, разобрался со всеми проблемами и готов поведать свою историю Вам.

Перенос стиля
5 min
Перенос стиля это процесс преобразования стиля исходного к стилю выбранного изображения и опирается на Сверточный тип сети (CNN), при этом заранее обученной, поэтому многое будет зависеть от выбора данной обученной сети. Благо такие сети есть и выбирать есть из чего, но здесь будет применяться VGG-16.
Для начала необходимо подключить необходимые библиотеки
Для начала необходимо подключить необходимые библиотеки
Код объявления библиотек
import time
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
import torchvision
from torchvision import transforms
from io import BytesIO
from PIL import Image
from collections import OrderedDict
from google.colab import files
Автоэнкодеры в Keras, Часть 1: Введение
11 min
Tutorial
Содержание
- Часть 1: Введение
- Часть 2: Manifold learning и скрытые (latent) переменные
- Часть 3: Вариационные автоэнкодеры (VAE)
- Часть 4: Conditional VAE
- Часть 5: GAN (Generative Adversarial Networks) и tensorflow
- Часть 6: VAE + GAN
Во время погружения в Deep Learning зацепила меня тема автоэнкодеров, особенно с точки зрения генерации новых объектов. Стремясь улучшить качество генерации, читал различные блоги и литературу на тему генеративных подходов. В результате набравшийся опыт решил облечь в небольшую серию статей, в которой постарался кратко и с примерами описать все те проблемные места с которыми сталкивался сам, заодно вводя в синтаксис Keras.
Автоэнкодеры
Автоэнкодеры — это нейронные сети прямого распространения, которые восстанавливают входной сигнал на выходе. Внутри у них имеется скрытый слой, который представляет собой код, описывающий модель. Автоэнкодеры конструируются таким образом, чтобы не иметь возможность точно скопировать вход на выходе. Обычно их ограничивают в размерности кода (он меньше, чем размерность сигнала) или штрафуют за активации в коде. Входной сигнал восстанавливается с ошибками из-за потерь при кодировании, но, чтобы их минимизировать, сеть вынуждена учиться отбирать наиболее важные признаки.
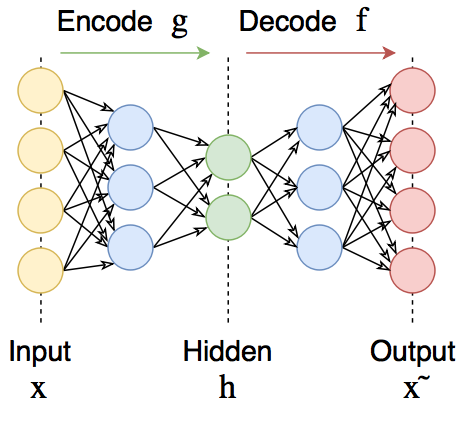
Кому интересно, добро пожаловать под кат
О работе ПК на примере Windows 10 и клавиатуры ч. 1
16 min
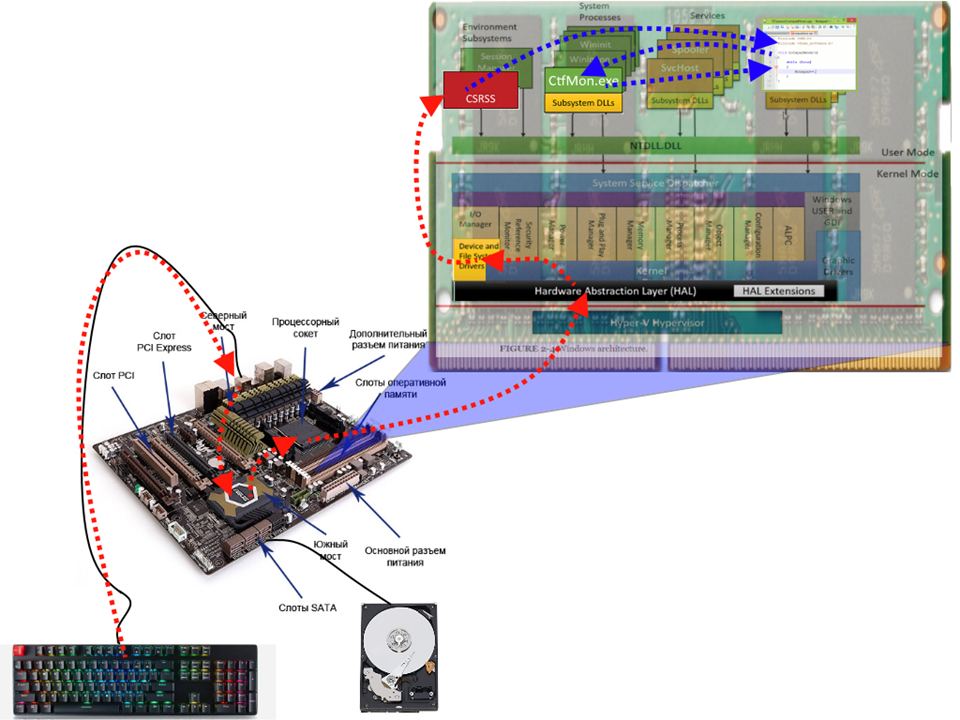
Меня зовут Андрей Артемьев, я работаю в Microsoft над ядром ОС Windows 10, ранее я работал над Windows 10x (WCOS), XBox, Windows Phone и Microsoft Edge. Я хочу популярно в образовательных целях рассказать о том как работает компьютер на примере клавиатурного ввода и Windows 10. Данный цикл статей рассчитан в первую очередь на студентов технических специальностей. Мы рассмотрим какой путь проходит информация о нажатой клавише от клавиатуры до отображения в Notepad.exe. В виду обширности и междисциплинарности темы в статьях могут быть неточности, о которых сообщайте в комментариях. Какая-то информация может быть устаревшей в виду скорости с которой развивается Windows.
SSD на базе QLC — убийца жёстких дисков? На самом деле нет
11 min
SSD-накопители уже давно вышли из разряда дорогой и ненадежной экзотики и стали привычным компонентом компьютеров всех уровней, от бюджетных офисных «печатных машинок» до мощных серверов.
В этой статье мы хотим рассказать о новом этапе эволюции SSD — очередном повышении уровня записи данных в NAND: о четырехуровневых ячейках, хранящих по 4 бита, или QLC (Quad-Level Cell). Накопители, сделанные по этой технологии имеют большую плотность записи, это упрощает увеличение их объема, а стоимость оказывается меньше, чем у SSD с «традиционными» ячейками MLC и TLC.
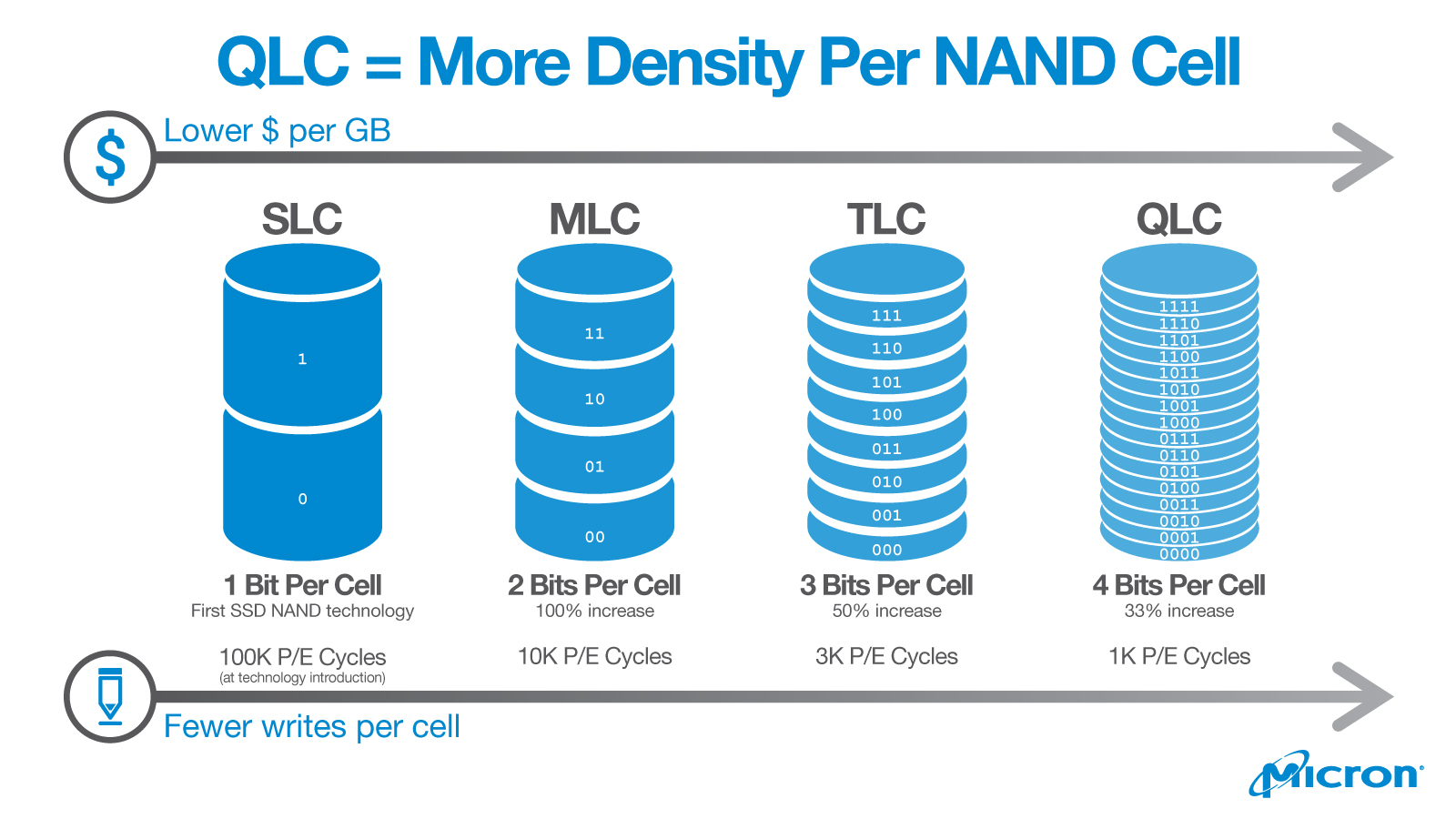
Как и следовало ожидать, в процессе разработки потребовалось решить множество задач, связанных с переходом на новую технологию. Компании-гиганты успешно с ними справляются, а небольшие китайские фирмы ещё отстают, их накопители менее технологичны, но дешевле.
Как это происходило, появился ли новый «убийца HDD» и надо ли бежать в магазины, меняя все HDD и SSD прошлых поколений на новые — расскажем ниже.
В этой статье мы хотим рассказать о новом этапе эволюции SSD — очередном повышении уровня записи данных в NAND: о четырехуровневых ячейках, хранящих по 4 бита, или QLC (Quad-Level Cell). Накопители, сделанные по этой технологии имеют большую плотность записи, это упрощает увеличение их объема, а стоимость оказывается меньше, чем у SSD с «традиционными» ячейками MLC и TLC.
Как и следовало ожидать, в процессе разработки потребовалось решить множество задач, связанных с переходом на новую технологию. Компании-гиганты успешно с ними справляются, а небольшие китайские фирмы ещё отстают, их накопители менее технологичны, но дешевле.
Как это происходило, появился ли новый «убийца HDD» и надо ли бежать в магазины, меняя все HDD и SSD прошлых поколений на новые — расскажем ниже.
Варим ML Boot Camp III: Starter Kit
17 min
Tutorial

16 марта закончилось соревнование по машинному обучению ML Boot Camp III. Я не настоящий сварщик, но, тем не менее, смог добиться 7го места в финальной таблице результатов. В данной статье я хотел бы поделиться тем, как начать участвовать в такого рода чемпионатах, на что стоит обратить внимание в первый раз при решении задачи, и рассказать о своем подходе.
Метод оптимизации Нелдера — Мида. Пример реализации на Python
5 min
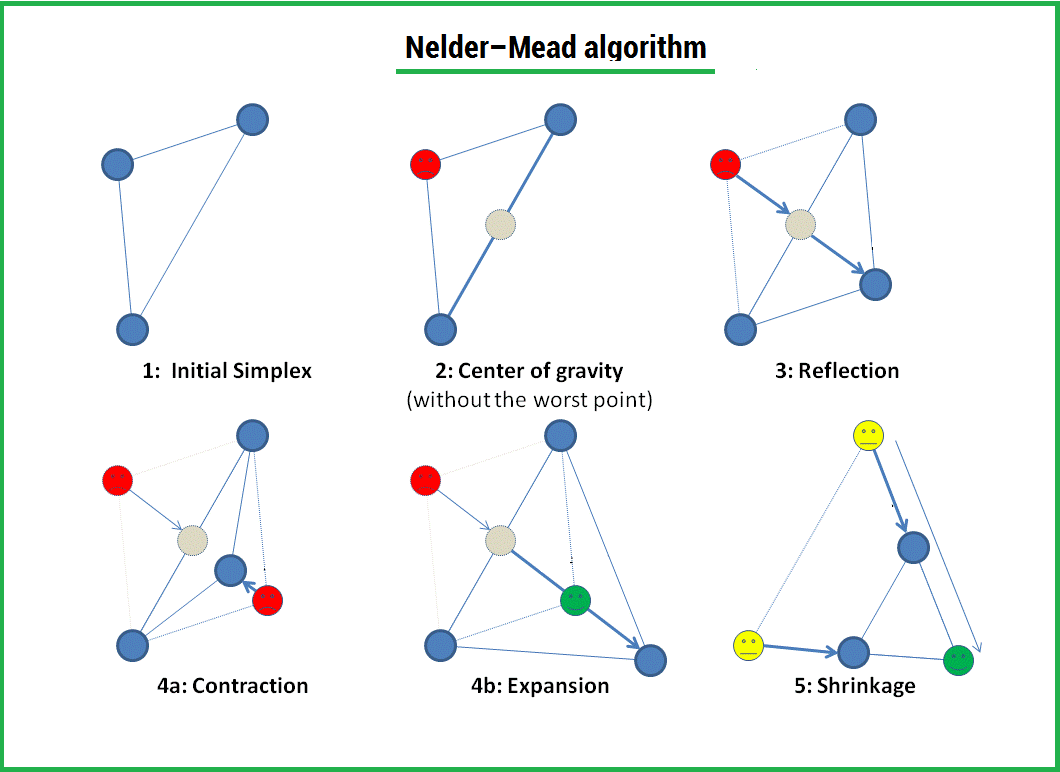
Метод Нелдера — Мида — метод оптимизации (поиска минимума) функции от нескольких переменных. Простой и в тоже время эффективный метод, позволяющий оптимизировать функции без использования градиентов. Метод надежен и, как правило, показывает хорошие результаты, хотя и отсутствует теория сходимости. Может использоваться в функции optimize из модуля scipy.optimize популярной библиотеки для языка python, которая используется для математических расчетов.
Нейронные сети, фундаментальные принципы работы, многообразие и топология
9 min
Нейронные сети совершили революцию в области распознавания образов, но из-за неочевидной интерпретируемости принципа работы, их не используют в таких областях, как медицина и оценка рисков. Требуется наглядное представление работы сети, которое сделает её не чёрным ящиком, а хотя бы «полупрозрачным». Cristopher Olah, в работе «Neural Networks, Manifolds, and Topology» наглядно показал принципы работы нейронной сети и связал их с математической теорией топологии и многообразия, которая послужила основой для данной статьи. Для демонстрации работы нейронной сети используются низкоразмерные глубокие нейронные сети.
Понять поведение глубоких нейронных сетей в целом нетривиальная задача. Проще исследовать низкоразмерные глубокие нейронные сети — сети, в которых есть только несколько нейронов в каждом слое. Для низкоразмерных сетей можно создавать визуализацию, чтобы понять поведение и обучение таких сетей. Эта перспектива позволит получить более глубокое понимание о поведении нейронных сетей и наблюдать связь, объединяющую нейронные сети с областью математики, называемой топологией.
Из этого вытекает ряд интересных вещей, в том числе фундаментальные нижние границы сложности нейронной сети, способной классифицировать определенные наборы данных.
Рассмотрим принцип работы сети на примере
Понять поведение глубоких нейронных сетей в целом нетривиальная задача. Проще исследовать низкоразмерные глубокие нейронные сети — сети, в которых есть только несколько нейронов в каждом слое. Для низкоразмерных сетей можно создавать визуализацию, чтобы понять поведение и обучение таких сетей. Эта перспектива позволит получить более глубокое понимание о поведении нейронных сетей и наблюдать связь, объединяющую нейронные сети с областью математики, называемой топологией.
Из этого вытекает ряд интересных вещей, в том числе фундаментальные нижние границы сложности нейронной сети, способной классифицировать определенные наборы данных.
Рассмотрим принцип работы сети на примере
Переезд: подготовка, выбор, освоение территории
16 min
Кажется, что IT-инженерам легко живется. Они хорошо зарабатывают и свободно перемещаются между работодателями и странами. Но это все не просто так. «Типичный айтишник» красноглазит за компьютером со школы, а потом еще в университете, магистратуре, аспирантуре… Дальше работа, работа, работа, годы продакшн, и только тогда переезд. А потом опять работа.
Конечно же, со стороны может показаться, что просто повезло. Но, если не считать времени и труда на обучение, прокачку навыков и бег по карьерной лестнице, то сам переезд — это гарантия серебряных полосок на голове и геноцида нервных клеток.

Переезд в другой город, страну, континент или планету не так уж прост. Иной менталитет, культура, правила, законы, цены, медицина, а еще надо найти куда переезжать, оффер, жилье, сделать визу… тысячи нюансов. Как не получить нервный тик, а только максимальную выгоду и удовольствие от процесса, расскажет Денис Неклюдов (nekdenis).
По каким причинам люди уезжают, что их ждет там и как выбирать, куда переехать? Как сориентироваться на рынке труда, найти работу, подготовиться к интервью и выбрать самый выгодный оффер. На примере переездов Дениса на Пхукет, в Сингапур, Сан-Франциско и опыта множества других экспатов подготовимся к новым приключениям. Рассказ Дениса — это дорожная карта или чек-лист, который будет полезен всем, кто задумывается о переезде.
Дисклеймер. «Земля круглая» и вращается. Когда-нибудь мы вернемся туда, откуда начали. Переезд Дениса не провоцирует вас навсегда покинуть родину. Не воспринимайте тему переезда агрессивно, а лишь как способ расширить кругозор. Статья основана исключительно на опыте обычных разработчиков без налета роскошной жизни крипто-миллионеров и тяжелых судеб мигрантов без профессии.
Конечно же, со стороны может показаться, что просто повезло. Но, если не считать времени и труда на обучение, прокачку навыков и бег по карьерной лестнице, то сам переезд — это гарантия серебряных полосок на голове и геноцида нервных клеток.
Переезд в другой город, страну, континент или планету не так уж прост. Иной менталитет, культура, правила, законы, цены, медицина, а еще надо найти куда переезжать, оффер, жилье, сделать визу… тысячи нюансов. Как не получить нервный тик, а только максимальную выгоду и удовольствие от процесса, расскажет Денис Неклюдов (nekdenis).
По каким причинам люди уезжают, что их ждет там и как выбирать, куда переехать? Как сориентироваться на рынке труда, найти работу, подготовиться к интервью и выбрать самый выгодный оффер. На примере переездов Дениса на Пхукет, в Сингапур, Сан-Франциско и опыта множества других экспатов подготовимся к новым приключениям. Рассказ Дениса — это дорожная карта или чек-лист, который будет полезен всем, кто задумывается о переезде.
Дисклеймер. «Земля круглая» и вращается. Когда-нибудь мы вернемся туда, откуда начали. Переезд Дениса не провоцирует вас навсегда покинуть родину. Не воспринимайте тему переезда агрессивно, а лишь как способ расширить кругозор. Статья основана исключительно на опыте обычных разработчиков без налета роскошной жизни крипто-миллионеров и тяжелых судеб мигрантов без профессии.
Идеальное резюме, которому будут рады рекрутер и работодатель
12 min
Данная статья основана на материалах моего выступления перед студентами Южного Федерального Университета. Большинство примеров – из мира веб-разработки. Однако принципы, о которых я рассказываю, применимы к любой области деятельности.