
У нас проблемы с промисами
16 мин
Перевод
Разрешите представить вам перевод статьи Нолана Лоусона «У нас проблемы с промисами», одной из лучших по теме из тех, что мне доводилось читать.
Дорогие JavaScript разработчики, настал момент признать это — у нас проблемы с промисами.
Нет, не с самими промисами. Их реализация по спецификации A+ превосходна. Основная проблема, которая сама предстала передо мной за годы наблюдений за тем, как многие программисты борются с богатыми на промисы API, заключается в следующем:
— Многие из нас используют промисы без действительного их понимания.
Если вы мне не верите, решите такую задачку:
Вопрос: В чем разница между этими четырьмя вариантами использования промисов?
У нас проблемы с промисами
Дорогие JavaScript разработчики, настал момент признать это — у нас проблемы с промисами.
Нет, не с самими промисами. Их реализация по спецификации A+ превосходна. Основная проблема, которая сама предстала передо мной за годы наблюдений за тем, как многие программисты борются с богатыми на промисы API, заключается в следующем:
— Многие из нас используют промисы без действительного их понимания.
Если вы мне не верите, решите такую задачку:
Вопрос: В чем разница между этими четырьмя вариантами использования промисов?
doSomething().then(function () {
return doSomethingElse();
});
doSomething().then(function () {
doSomethingElse();
});
doSomething().then(doSomethingElse());
doSomething().then(doSomethingElse);
 Ты просто-напросто ненавидишь
Ты просто-напросто ненавидишь 

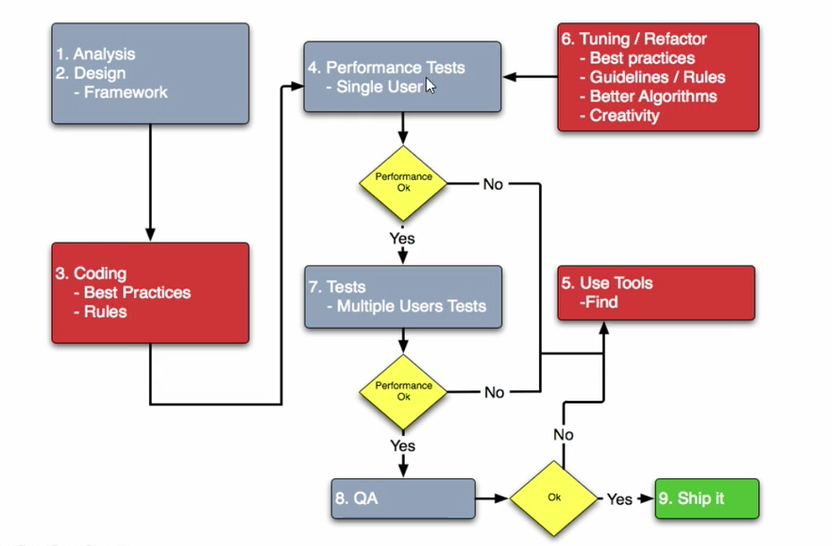
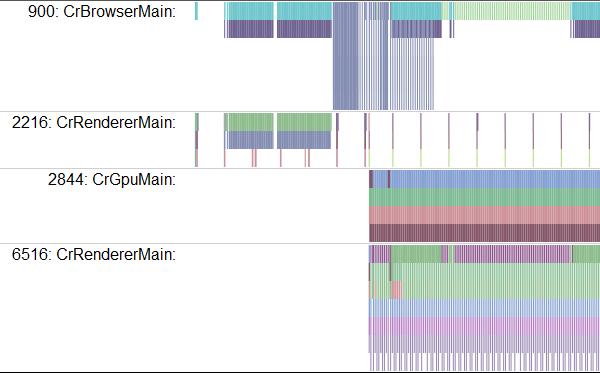
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.


 Доброго времени суток читатель. Сегодняшний пост будет посвящен вычислению приближенного значения
Доброго времени суток читатель. Сегодняшний пост будет посвящен вычислению приближенного значения 

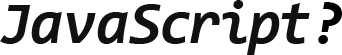
 В современном мире анализа данных использовать только один метод или только один подход означает, что рано или поздно ты столкнешься с фактом, как сильно ты ошибался. Для анализа данных комбинируют различные методики, сравнивают результат и на основании сравнения уже делают более точные прогнозы. В программе ZINBA использован именно такой подход. Разработчики объединили разнообразные методы анализа DNA-seq экспериментов в едином пакете. Этот пакет написан для программы статистической обработки данных R. Что же делает ZINBA? Находит различные обогащенные регионы даже в тех случаях, когда некоторые из них были усилены, например, химически или имеют разную степень соотношения сигнал-шум.
В современном мире анализа данных использовать только один метод или только один подход означает, что рано или поздно ты столкнешься с фактом, как сильно ты ошибался. Для анализа данных комбинируют различные методики, сравнивают результат и на основании сравнения уже делают более точные прогнозы. В программе ZINBA использован именно такой подход. Разработчики объединили разнообразные методы анализа DNA-seq экспериментов в едином пакете. Этот пакет написан для программы статистической обработки данных R. Что же делает ZINBA? Находит различные обогащенные регионы даже в тех случаях, когда некоторые из них были усилены, например, химически или имеют разную степень соотношения сигнал-шум.
