Примечание от переводчика:
Этот пост был написан и опубликован на Medium разработчиком приложений Адрианом Космачевским из Швейцарии. Кроме подготовки перевода его публикации, я также пригласил и самого автора, Адриана ( akosma ), на Хабр, для того, чтобы он смог лично ответить на любые вопросы участников сообщества, если таковые возникнут. Думаю, для общего удобства при общении в комментариях с ним стоит использовать английский (и, при желании, дублировать на русском).
Привет всем, я — сорокадвухлетний программист-самоучка, а это моя история.
Пару недель назад я наткнулся на твит, в котором была картинка, прикрепленная ниже, и он заставил меня задуматься о моей карьере.
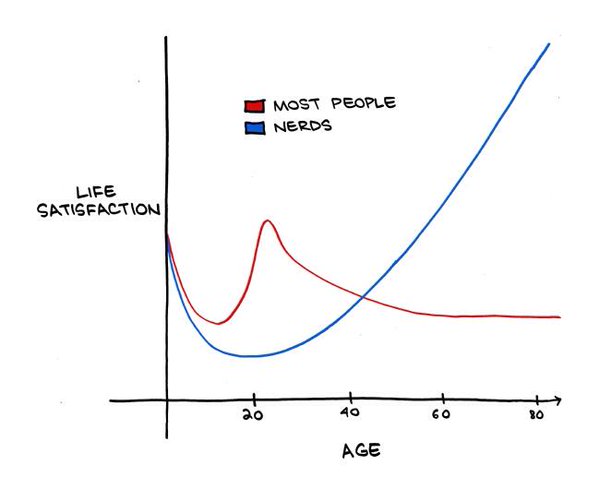
Эти размышления привели меня туда, откуда все начиналось.
Я дебютировал в роли разработчика программного обеспечения в 10 часов утра 6 октября 1997 года, в городе Оливос, к северу от Буэнос-Айреса, в Аргентине. Был понедельник. Не так давно я праздновал свой 24-й день рождения.
Мир в 1997 году
Тогда он был немного другим. На веб-сайтах не было предупреждений об использовании cookie. Новаторскими в сети были сайты вида Excite.com, а моим любимым поисковиком был AltaVista.
Мой электронный ящик имел вид kosmacze@sc2a.unige.ch и был расположен на личном веб-сайте, который размещался по адресу
http://sc2a.unige.ch/~kosmacze. Тогда мы еще оплакивали принцессу Диану, а Стив Джобс только-только вернулся на роль CEO и убедил Microsoft «вбросить» в Apple Computer 150 миллионов долларов. Digital Equipment Corporation подала в суд на Dell, останки Че Гевары вернули на Кубу, только начался четвертый (!) сезон «Друзей». Был убит Джанни Версаче, скончались Мать Тереза, Рой Лихтенштейн и Жанна Кальман. Люди зависали за Final Fantasy 7 на PlayStation, будто бы были наркоманами, Би-Би-2 начал вещание телепузиков, а Кэмерон только собирался показать миру свой «Титаник».