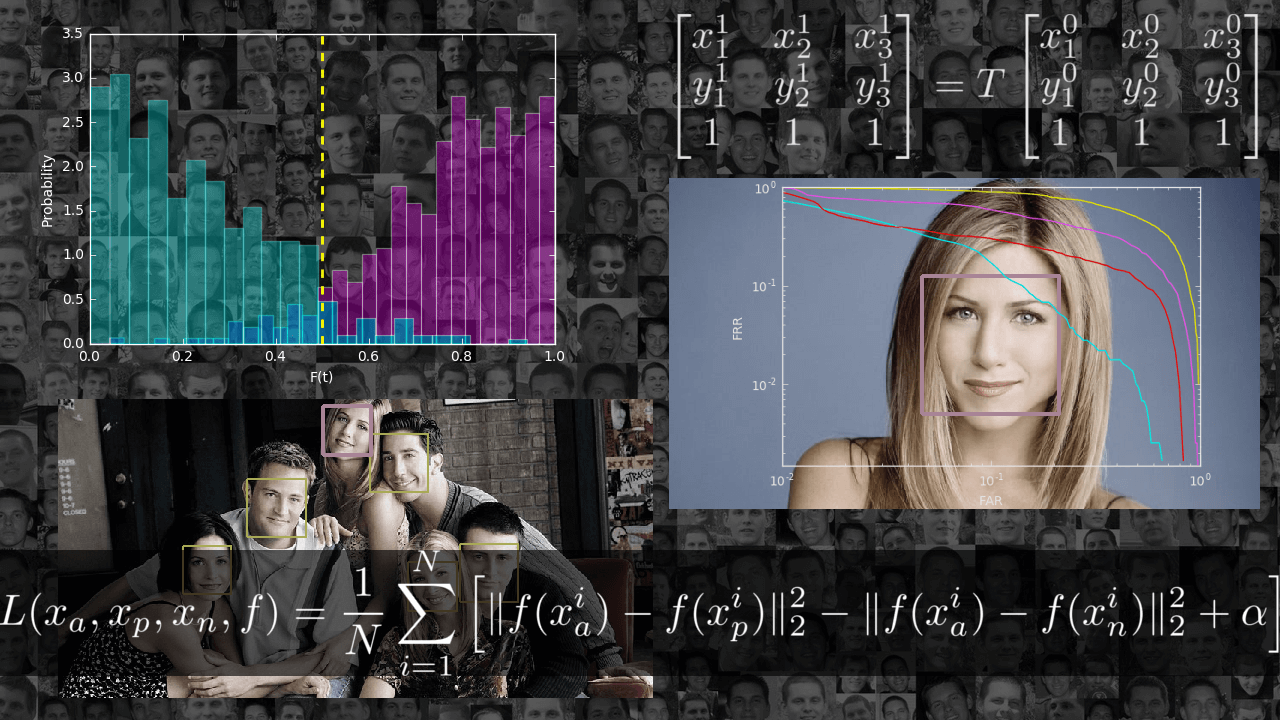Как начать работу в Kaggle: руководство для новичков в Data Science
4 min
Доброго времени суток, уважаемые хабровчане! Сегодня я хотел бы поговорить о том, как не имея особого опыта в машинном обучении, можно попробовать свои силы в соревнованиях, проводимых Kaggle.

Как вам уже, наверное, известно, Kaggle – это платформа для исследователей разных уровней, где они могут опробовать свои модели анализа данных на серьезных и актуальных задачах. Суть такого ресурса – не только в возможности получить неплохой денежный приз в случае, если именно ваша модель окажется лучшей, но и в том (а, это, пожалуй, гораздо важнее), чтобы набраться опыта и стать специалистом в области анализа данных и машинного обучения. Ведь самый важный вопрос, зачастую стоящий перед такого рода специалистами – где найти реальные задачи? Здесь их достаточно.
Мы попробуем поучаствовать в обучающем соревновании, не предусматривающем каких-либо поощрений, кроме опыта.
Как вам уже, наверное, известно, Kaggle – это платформа для исследователей разных уровней, где они могут опробовать свои модели анализа данных на серьезных и актуальных задачах. Суть такого ресурса – не только в возможности получить неплохой денежный приз в случае, если именно ваша модель окажется лучшей, но и в том (а, это, пожалуй, гораздо важнее), чтобы набраться опыта и стать специалистом в области анализа данных и машинного обучения. Ведь самый важный вопрос, зачастую стоящий перед такого рода специалистами – где найти реальные задачи? Здесь их достаточно.
Мы попробуем поучаствовать в обучающем соревновании, не предусматривающем каких-либо поощрений, кроме опыта.

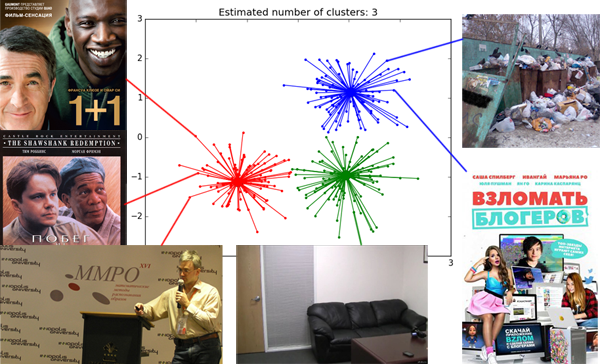


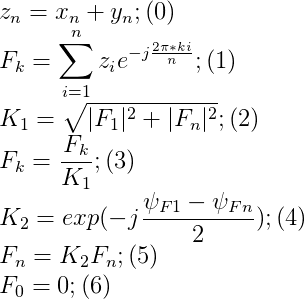
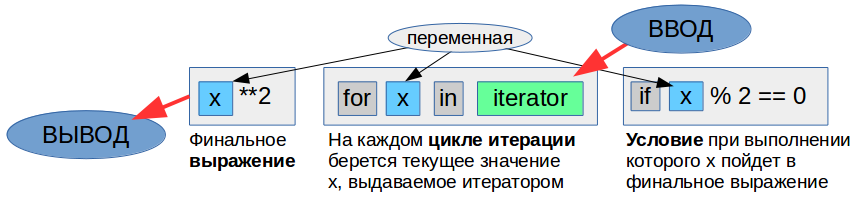





 Привет, Хаброжители! к нам только что пришла из типографии книга Кэла Ньюпорта «В работу с головой. Паттерны успеха от IT-специалиста»
Привет, Хаброжители! к нам только что пришла из типографии книга Кэла Ньюпорта «В работу с головой. Паттерны успеха от IT-специалиста»