Прогресс в области нейросетей вообще и распознавания образов в частности, привел к тому, что может показаться, будто создание нейросетевого приложения для работы с изображениями — это рутинная задача. В некотором смысле, так и есть — если вам пришла в голову идея, связанныя с распознаватием образов, не сомневайтесь, что кто-то уже что-то подобное написал. Все, что от вас требуется, это найти в Гугле соответствующий кусок кода и «скомпилировать» его у автора.
Однако, все еще есть многочисленные детали, делающие задачу не столько неразрешимой, сколько… нудной, я бы сказал. Отнимающей слишком много времени, особенно если вы — новичок, которому нужно руководство, step-by-step, проект, выполненный прямо на ваших глазах, и выполненный от начала и до конца. Без обычных в таких случаях «пропустим эту очевидную часть» отговорок.
В этой статье мы рассмотрим задачу создания определителя пород собак (Dog Breed Identifier): создадим и обучим нейросеть, а затем портируем ее на Java для Android и опубликуем на Google Play.
Если вы хотите посмотреть на готовый результат, вот он: NeuroDog App на Google Play.
Веб сайт с моей робототехникой (в процессе): robotics.snowcron.com.
Веб сайт с самой программой, включая руководство: NeuroDog User Guide.
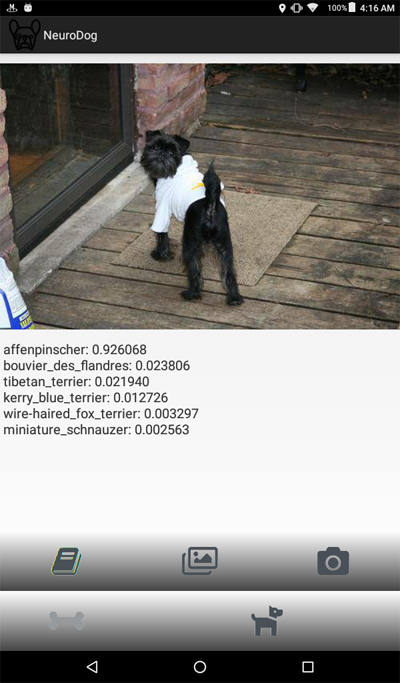
А вот скриншот программы:
Однако, все еще есть многочисленные детали, делающие задачу не столько неразрешимой, сколько… нудной, я бы сказал. Отнимающей слишком много времени, особенно если вы — новичок, которому нужно руководство, step-by-step, проект, выполненный прямо на ваших глазах, и выполненный от начала и до конца. Без обычных в таких случаях «пропустим эту очевидную часть» отговорок.
В этой статье мы рассмотрим задачу создания определителя пород собак (Dog Breed Identifier): создадим и обучим нейросеть, а затем портируем ее на Java для Android и опубликуем на Google Play.
Если вы хотите посмотреть на готовый результат, вот он: NeuroDog App на Google Play.
Веб сайт с моей робототехникой (в процессе): robotics.snowcron.com.
Веб сайт с самой программой, включая руководство: NeuroDog User Guide.
А вот скриншот программы:








 Здравствуйте, коллеги! Это блог открытой русскоговорящей
Здравствуйте, коллеги! Это блог открытой русскоговорящей  Привет, Хабр!
Привет, Хабр!