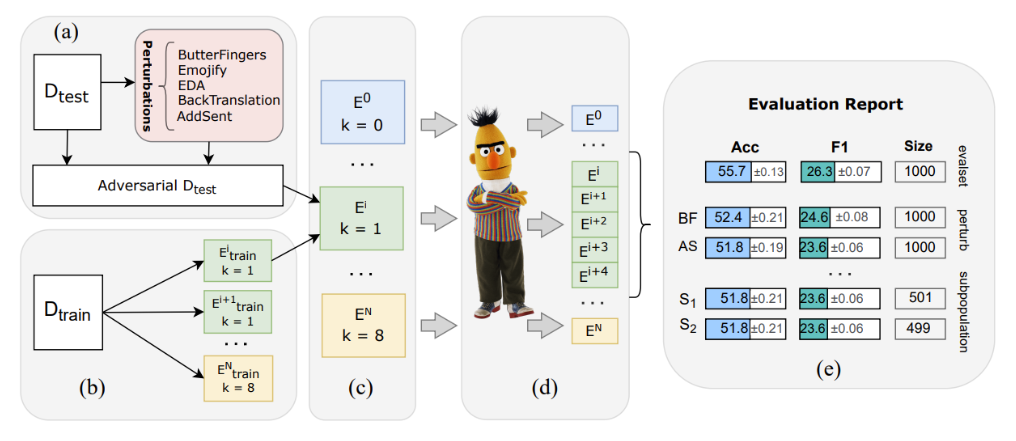
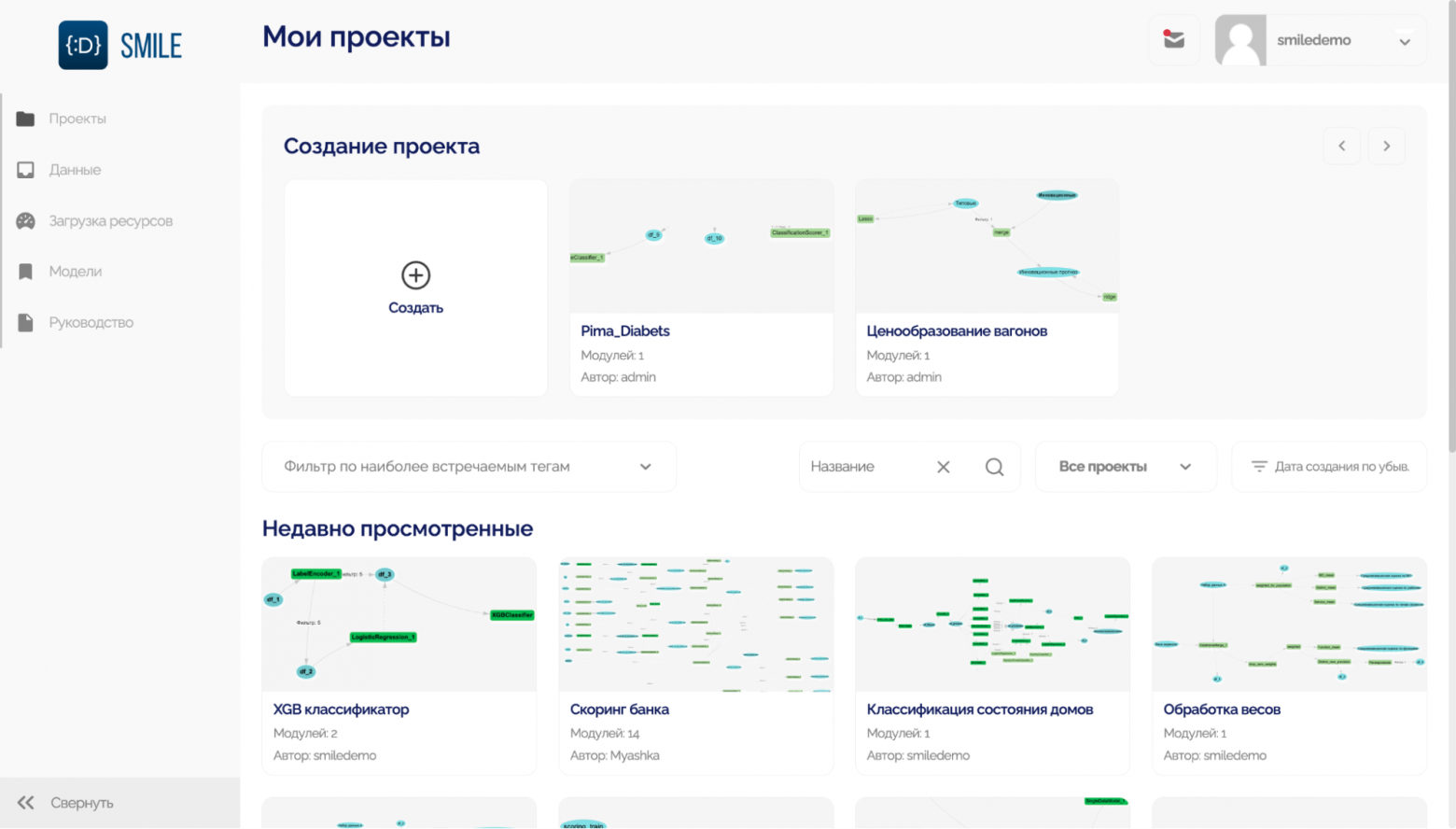
Я вырос в маленьком и закрытом военном городке, где самая длинная улица была 2 километра и по ней, в среднем, проезжала одна машина за две-три минуты.
Когда я приехал поступать в МГУ, заселился в ДАСе на 15 этаже. После пятиэтажного городка это была очень впечатляющая перемена. Лето было жарким и окна всегда были распахнуты, сторона ДАСа, где я жил, выходила на Большую Черёмушкинскую улицу, не самую загруженную, по столичным меркам, но довольно оживленную. На такой высоте в комнату собирались звуки с половины города. Конечно, колоколов Ивана великого слышно не было, но разноголосый гомон плотно набивался в небольшую комнату.
Однажды, сильно заполночь, разговорившись с соседом-аспирантом, я посетовал на постоянный шум, наполняющий этот огромный город.
— Но ведь сейчас тихо! — Воскликнул сосед, который прожил в этом общежитии уже пять лет.
— Нет…