
Сегодня мы завершаем новогоднюю серию постов, посвященных лекциям Школы анализа данных. Последний по порядку, но никак не по важности курс — «Алгоритмы и структуры данных поиска».
В этом курсе рассматриваются базовые алгоритмы и структуры данных, включая хешировани, сложность и модели вычислений, деревья поиска, B-деревья, задачи геометрического поиска, динамическую связность в графах и другое.
Мы учли то, о чём нас просили в комментариях к прошлым курсам — теперь при желании можно не только смотреть/скачивать лекции по отдельности, но и загрузить всё разом в виде открытой папки на Яндекс.Диске. Кстати — в предыдущих постах тоже появились такие же апдейты (вот ссылки для удобства: «машинное обучение», «дискретный анализ и теория вероятностей», «параллельные и распределённые вычисления»).
Лекции читает Максим Александрович Бабенко, заместитель директора отделения computer science, ассистент кафедры математической логики и теории алгоритмов механико-математического факультета МГУ им. М. В. Ломоносова, кандидат физико-математических наук.
В этом курсе рассматриваются базовые алгоритмы и структуры данных, включая хешировани, сложность и модели вычислений, деревья поиска, B-деревья, задачи геометрического поиска, динамическую связность в графах и другое.
Мы учли то, о чём нас просили в комментариях к прошлым курсам — теперь при желании можно не только смотреть/скачивать лекции по отдельности, но и загрузить всё разом в виде открытой папки на Яндекс.Диске. Кстати — в предыдущих постах тоже появились такие же апдейты (вот ссылки для удобства: «машинное обучение», «дискретный анализ и теория вероятностей», «параллельные и распределённые вычисления»).
Лекции читает Максим Александрович Бабенко, заместитель директора отделения computer science, ассистент кафедры математической логики и теории алгоритмов механико-математического факультета МГУ им. М. В. Ломоносова, кандидат физико-математических наук.
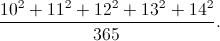





 Так получилось, что последние несколько недель очень часто приходилось слышать слова Promise и Deferred от разных людей. Как правило, этими понятиями оперируют уже повидавшие виды разработчики, столкнувшиеся в своей деятельности с определенными задачами.
Так получилось, что последние несколько недель очень часто приходилось слышать слова Promise и Deferred от разных людей. Как правило, этими понятиями оперируют уже повидавшие виды разработчики, столкнувшиеся в своей деятельности с определенными задачами.