В предыдущей статье мы закончили разговор о профилировании обзором событийных профайлеров.
Сегодня я предлагаю рассмотреть методы отладки программ.
Сегодня я предлагаю рассмотреть методы отладки программ.

Пользователь

db13 ~ # cat /etc/fstab | grep md
/dev/md0 / ext3 noatime 0 1
/dev/md1 /mnt/db reiser4 noatime 0 0
title Gentoo Linux 3.10.7 md0
root (hd0,0)
kernel /boot/kernel-3.10.7 root=/dev/md0
[ 0.000000] Command line: root=/dev/md0 raid=/dev/md0 [ 0.000000] Kernel command line: root=/dev/md0 raid=/dev/md0 [ 1.063603] md: raid1 personality registered for level 1 [ 1.266420] md: Waiting for all devices to be available before autodetect [ 1.266494] md: If you don't use raid, use raid=noautodetect [ 1.266781] md: Autodetecting RAID arrays. [ 1.293670] md: invalid raid superblock magic on sdc1
[ 1.294210] md: sdc1 does not have a valid v0.90 superblock, not importing! [ 1.312482] md: invalid raid superblock magic on sdd1 [ 1.312556] md: sdd1 does not have a valid v0.90 superblock, not importing!
[ 1.312579] md: Scanned 4 and added 2 devices. [ 1.312595] md: autorun ... [ 1.312610] md: considering sdb3 ... [ 1.312626] md: adding sdb3 ... [ 1.312641] md: adding sda3 ... [ 1.312657] md: created md0 [ 1.312665] md: bind<sda3> [ 1.312754] md: bind<sdb3> [ 1.312770] md: running: <sdb3><sda3> [ 1.313064] md/raid1:md0: active with 2 out of 2 mirrors [ 1.313166] md0: detected capacity change from 0 to 7984840704 [ 1.313262] md: ... autorun DONE. [ 1.320413] md0: unknown partition table [ 1.338528] EXT3-fs (md0): mounted filesystem with ordered data mode [ 2.581420] systemd-udevd[861]: starting version 208 [ 3.122748] md: bind<sdc1> [ 4.896331] EXT3-fs (md0): using internal journal
mdadm --manage /dev/md1 --run. Конечно, можно было бы прописать эту строчку куда-нибудь в rc-скрипты, но, согласитесь, это как-то не спортивно.
[ 0.000000] Command line: root=/dev/md0 raid=/dev/md0 [ 0.000000] Kernel command line: root=/dev/md0 raid=/dev/md0 [ 1.063924] md: raid1 personality registered for level 1 [ 1.248078] md: Waiting for all devices to be available before autodetect [ 1.248201] md: If you don't use raid, use raid=noautodetect [ 1.248504] md: Autodetecting RAID arrays. [ 1.265058] md: Scanned 2 and added 2 devices. [ 1.265243] md: autorun ... [ 1.265258] md: considering sda3 ... [ 1.265274] md: adding sda3 ... [ 1.265290] md: adding sdb3 ... [ 1.265305] md: created md0 [ 1.265321] md: bind<sdb3> [ 1.265331] md: bind<sda3> [ 1.265428] md: running: <sda3><sdb3> [ 1.265865] md/raid1:md0: active with 2 out of 2 mirrors [ 1.265891] md0: detected capacity change from 0 to 7984840704 [ 1.266068] md: ... autorun DONE. [ 1.276627] md0: unknown partition table [ 1.294892] EXT3-fs (md0): mounted filesystem with ordered data mode
[ 2.713383] systemd-udevd[860]: starting version 208 [ 3.128295] md: bind<sdc1> [ 3.159107] md: bind<sdd1> [ 3.170320] md/raid1:md1: active with 2 out of 2 mirrors [ 3.170333] md1: detected capacity change from 0 to 17170300928 [ 3.178113] md1: unknown partition table [ 4.911712] EXT3-fs (md0): using internal journal [ 5.027077] reiser4: md1: found disk format 4.0.0.




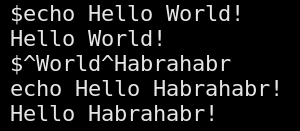 В данном посте я расскажу о наиболее интересных командах, которые могут быть очень полезны при работе в консоли. Однозначных критериев определения какая команда лучше другой — нет, каждый сам для своих условий выбирает лучшее. Я решил построить список команд на основе наиболее рейтинговых приемов работы с консолью от commandlinefu.com, кладовой консольных команд. Результат выполнения одной из таких команд под Linux приведен на картинке. Если заинтересовало, прошу под кат.
В данном посте я расскажу о наиболее интересных командах, которые могут быть очень полезны при работе в консоли. Однозначных критериев определения какая команда лучше другой — нет, каждый сам для своих условий выбирает лучшее. Я решил построить список команд на основе наиболее рейтинговых приемов работы с консолью от commandlinefu.com, кладовой консольных команд. Результат выполнения одной из таких команд под Linux приведен на картинке. Если заинтересовало, прошу под кат.
Не стоит преследовать цели, которые легко достичь. Стоит нацеливаться на то, что удается сделать с трудом, приложив немалые усилия — Альберт Эйнштейн
