Сей пост навеян неожиданным для меня интересом хабранаселения к посту уважаемого Milfgard из Мосигры про производство в Китае. Дело в том, что один из моих интересов как раз в производстве батарей – Denaq. И производство расположено ну конечно же в Китае. Я не стану рассказывать про организацию производства, там свои замечательные фокусы есть. Я расскажу именно про заказ чего-то под себя и покупку всякого опта. Что-то вроде алгоритма украшенного реальными историями из личного опыта. Это все будет про электронику, так как я сам именно ею занимаюсь. Истории и иллюстрации я буду выделять курсивом. Кому скучно читать общие выводы – читайте только их.

Семён Гольберт @ababo
User
«Атака на банк-клиент...». Взгляд со стороны работника банка
8 min
Меня очень заинтересовала статья Атака на банк-клиент или Охота на миллион в связи с тем, что я явлюсь непосредственным участником процесса дистанционного банковского обслуживания (далее — ДБО) со стороны банка. Чуть позже появилась статья Кому я нужен?, поэтому мыслей на эту тему накопилось очень много и хочется поделиться со всеми (а еще я давно хотел зарегистрироваться, но подходящего момента не было). По возможности буду краток и не буду сыпать научными терминами.
Математическая морфология
6 min
Воспользовавшись поиском, я с удивлением обнаружил, что на Хабре совсем нет статей, описывающих аппарат математической морфологии, а ведь этот аппарат незаменим в области низкоуровневой обработки изображений. Если вам это интересно, прошу под кат.
Консервативная логика
14 min
Вооруженные жидким азотом оверклокеры неоднократно показывали, что современные чипы могут стабильно работать на частотах в разы выше номинальных, обеспечивая соответствующий рост производительности. Тем не менее, прогресс в области «гонки гигагерц» остановился давно и надежно. Первый «Pentium 4» с частотой больше 3 ГГц появился в далеком 2002 году, почти 10 лет назад. За прошедшие годы нормы техпроцессов уменьшились со 180 до 32 нм, но даже это не позволило существенно поднять штатные рабочие частоты. Все упирается в огромное тепловыделение элементов цифровой логики.
В основе «проблемы тепловыделения» лежит глубокая связь между информационной и термодинамической энтропией, а также второе начало термодинамики, запрещающее уменьшение общей энтропии замкнутой системы. Любое вычисление, уменьшающее энтропию информационную, обязано приводить к увеличению энтропии термодинамической, то есть к выделению тепла. Рольф Ландауэр в 1961 году показал [pdf], что уничтожение одного бита информации должно приводить к выделению не менее k∙T∙ln 2 джоулей энергии, где k – постоянная Больцмана и T – температура системы. Само по себе эта энергия невелика: для T=300K она составляет всего 0.017 эВ на бит, но в пересчете на процессор в целом суммарная энергия вырастает уже до величин порядка одного Джоуля за каждую секунду работы, то есть порядка одного Ватта [Компьютерра №538]. На практике этот теоретический минимум умножается на ненулевое сопротивление и прочие неидеальности реальных полупроводников. В результате мы получаем процессоры, которые по тепловыделению обгоняют утюги.
В основе «проблемы тепловыделения» лежит глубокая связь между информационной и термодинамической энтропией, а также второе начало термодинамики, запрещающее уменьшение общей энтропии замкнутой системы. Любое вычисление, уменьшающее энтропию информационную, обязано приводить к увеличению энтропии термодинамической, то есть к выделению тепла. Рольф Ландауэр в 1961 году показал [pdf], что уничтожение одного бита информации должно приводить к выделению не менее k∙T∙ln 2 джоулей энергии, где k – постоянная Больцмана и T – температура системы. Само по себе эта энергия невелика: для T=300K она составляет всего 0.017 эВ на бит, но в пересчете на процессор в целом суммарная энергия вырастает уже до величин порядка одного Джоуля за каждую секунду работы, то есть порядка одного Ватта [Компьютерра №538]. На практике этот теоретический минимум умножается на ненулевое сопротивление и прочие неидеальности реальных полупроводников. В результате мы получаем процессоры, которые по тепловыделению обгоняют утюги.
Поиск подстроки и смежные вопросы
13 min
Здравствуйте, уважаемое сообщество! Недавно на Хабре проскакивала неплохая обзорная статья о разных алгоритмах поиска подстроки в строке. К сожалению, там отсутствовали подробные описания каких либо из упомянутых алгоритмов. Я решил восполнить данный пробел и описать хотя бы парочку тех, которые потенциально можно запомнить. Те, кто еще помнит курс алгоритмов из института, не найдут, видимо, ничего нового для себя.
Арт-проект от Google
3 min
Translation
Только что прогулявшаяся по Версалю, Менеджер по маркетингу продуктов Лидия Болотова
Более тысячи произведений искусства из 17 музеев мира теперь доступны онлайн в рамках Арт-проекта!
Сегодня компания Google представляет Арт-проект – результат уникального сотрудничества Google и знаменитых музеев мира. Теперь вы сможете познакомиться и рассмотреть в мельчайших деталях более тысячи произведений искусства на сайте googleartproject.com.
В проекте участвуют 17 художественных музеев, включая Государственный Эрмитаж в Санкт-Петербурге и Государственную Третьяковскую галерею в Москве. На сайте googleartproject.com представлена коллекция гигапиксельных изображений известнейших произведений искусства и собраны тысячи фотографий других великолепных работ. При использовании панорамной технологии Street View были созданы виртуальные экскурсии по залам художественных галерей.
Теперь любой человек, в какой бы стране он ни находился, может узнать больше о произведениях искусства разных стран мира, об их истории и создателях.
Музеи помогали нам выбирать коллекции для проекта, подбирать оптимальный угол съемки произведений, составляли сопроводительный текст, а также предоставляли аудио- и видеоматериалы. В виртуальную коллекцию вошли такие шедевры, как "Возвращение блудного сына" Рембрандта из Государственного Эрмитажа, "Явление Христа народу" Александра Иванова из Государственной Третьяковской галереи, "Рождение Венеры" Боттичелли, композиция современного британского художника Криса Офили "No Woman No Cry", пост-импрессионистские картины Сезанна, византийские иконы, потолочные росписи Версаля и интерьеры древних египетских храмов, произведения Уистлера и полотна Рембрандта.
Вы можете перемещаться по галереям, выбирать интересующие вас произведения искусства, читать информацию о них или в мельчайших деталях рассматривать изображения тех работ, которые отсняты в сверхвысоком разрешении (каждое такое изображение состоит из 14 млрд. пикселей). На информационной вкладке можно прочитать сопроводительный текст о произведении, найти другие работы того же художника и посмотреть видеоролики на YouTube, рассказывающие о картине, а также прослушать аудиофайлы.
Для создания панорамы интерьеров музеев специалисты Google специально доработали аппаратуру, использовавшуюся при создании сервиса «Просмотр улиц». Результаты съемок были сведены воедино, и теперь все пользователи смогут легко «прогуляться» по 385 залам разных галерей мира.
Кроме того, пользователи Арт-проекта смогут создавать собственные коллекции и отправлять ссылки на них своим друзьям, которые, в свою очередь, смогут комментировать понравившиеся работы.
Музеи в проекте:
Старая национальная галерея, Берлин, Германия
Галерея искусств Фриера в Смитсоновском институте, Вашингтон, США
Коллекция Фрика, Нью-Йорк, США
Берлинская картинная галерея, Берлин, Германия
Метрополитен-музей, Нью-Йорк, США
Музей современного искусства, Нью-Йорк, США
Музей королевы Софии, Мадрид, Испания
Музей Тиссена — Борнемисы, Мадрид, Испания
Музей Кампа, Прага, Чешская Республика
Национальная галерея, Лондон, Великобритания
Версальский дворец, Франция
Государственный музей, Амстердам, Нидерланды
Государственный Эрмитаж, Санкт-Петербург, Россия
Государственная Третьяковская галерея, Москва, Россия
Галерея Тейт, Лондон, Великобритания
Галерея Уффици, Флоренция, Италия
Музей Ван Гога, Амстердам, Нидерланды

Более тысячи произведений искусства из 17 музеев мира теперь доступны онлайн в рамках Арт-проекта!
Сегодня компания Google представляет Арт-проект – результат уникального сотрудничества Google и знаменитых музеев мира. Теперь вы сможете познакомиться и рассмотреть в мельчайших деталях более тысячи произведений искусства на сайте googleartproject.com.
В проекте участвуют 17 художественных музеев, включая Государственный Эрмитаж в Санкт-Петербурге и Государственную Третьяковскую галерею в Москве. На сайте googleartproject.com представлена коллекция гигапиксельных изображений известнейших произведений искусства и собраны тысячи фотографий других великолепных работ. При использовании панорамной технологии Street View были созданы виртуальные экскурсии по залам художественных галерей.
Теперь любой человек, в какой бы стране он ни находился, может узнать больше о произведениях искусства разных стран мира, об их истории и создателях.
Музеи помогали нам выбирать коллекции для проекта, подбирать оптимальный угол съемки произведений, составляли сопроводительный текст, а также предоставляли аудио- и видеоматериалы. В виртуальную коллекцию вошли такие шедевры, как "Возвращение блудного сына" Рембрандта из Государственного Эрмитажа, "Явление Христа народу" Александра Иванова из Государственной Третьяковской галереи, "Рождение Венеры" Боттичелли, композиция современного британского художника Криса Офили "No Woman No Cry", пост-импрессионистские картины Сезанна, византийские иконы, потолочные росписи Версаля и интерьеры древних египетских храмов, произведения Уистлера и полотна Рембрандта.
Вы можете перемещаться по галереям, выбирать интересующие вас произведения искусства, читать информацию о них или в мельчайших деталях рассматривать изображения тех работ, которые отсняты в сверхвысоком разрешении (каждое такое изображение состоит из 14 млрд. пикселей). На информационной вкладке можно прочитать сопроводительный текст о произведении, найти другие работы того же художника и посмотреть видеоролики на YouTube, рассказывающие о картине, а также прослушать аудиофайлы.
Для создания панорамы интерьеров музеев специалисты Google специально доработали аппаратуру, использовавшуюся при создании сервиса «Просмотр улиц». Результаты съемок были сведены воедино, и теперь все пользователи смогут легко «прогуляться» по 385 залам разных галерей мира.
Кроме того, пользователи Арт-проекта смогут создавать собственные коллекции и отправлять ссылки на них своим друзьям, которые, в свою очередь, смогут комментировать понравившиеся работы.
Музеи в проекте:
Старая национальная галерея, Берлин, Германия
Галерея искусств Фриера в Смитсоновском институте, Вашингтон, США
Коллекция Фрика, Нью-Йорк, США
Берлинская картинная галерея, Берлин, Германия
Метрополитен-музей, Нью-Йорк, США
Музей современного искусства, Нью-Йорк, США
Музей королевы Софии, Мадрид, Испания
Музей Тиссена — Борнемисы, Мадрид, Испания
Музей Кампа, Прага, Чешская Республика
Национальная галерея, Лондон, Великобритания
Версальский дворец, Франция
Государственный музей, Амстердам, Нидерланды
Государственный Эрмитаж, Санкт-Петербург, Россия
Государственная Третьяковская галерея, Москва, Россия
Галерея Тейт, Лондон, Великобритания
Галерея Уффици, Флоренция, Италия
Музей Ван Гога, Амстердам, Нидерланды
Что нужно знать про арифметику с плавающей запятой
14 min

В далекие времена, для IT-индустрии это 70-е годы прошлого века, ученые-математики (так раньше назывались программисты) сражались как Дон-Кихоты в неравном бою с компьютерами, которые тогда были размером с маленькие ветряные мельницы. Задачи ставились серьезные: поиск вражеских подлодок в океане по снимкам с орбиты, расчет баллистики ракет дальнего действия, и прочее. Для их решения компьютер должен оперировать действительными числами, которых, как известно, континуум, тогда как память конечна. Поэтому приходится отображать этот континуум на конечное множество нулей и единиц. В поисках компромисса между скоростью, размером и точностью представления ученые предложили числа с плавающей запятой (или плавающей точкой, если по-буржуйски).
Арифметика с плавающей запятой почему-то считается экзотической областью компьютерных наук, учитывая, что соответствующие типы данных присутствуют в каждом языке программирования. Я сам, если честно, никогда не придавал особого значения компьютерной арифметике, пока решая одну и ту же задачу на CPU и GPU получил разный результат. Оказалось, что в потайных углах этой области скрываются очень любопытные и странные явления: некоммутативность и неассоциативность арифметических операций, ноль со знаком, разность неравных чисел дает ноль, и прочее. Корни этого айсберга уходят глубоко в математику, а я под катом постараюсь обрисовать лишь то, что лежит на поверхности.
Web – P2P — Web
6 min
 Доброе время суток, дорогой %username%.
Доброе время суток, дорогой %username%.Недавно прочитал хабрастатью посвящённую достаточно общей идее распределённого веба. Сам я уже некоторое время занят в практической реализации проекта, идеи которого поразительно похожи на идеи автора вышеупомянутой статьи.
Под катом общие размышления, обзор текущего состояния проекта, перспективы и, конечно, немного трафика.
Если интересно — welcome под кат.
Колоночные СУБД — принцип действия, преимущества и область применения
5 min
Середина 2000-х годов ознаменовалась бурным ростом числа колоночных СУБД. Vertica, ParAccel, Kognito, Infobright, SAND и другие пополнили клуб колоночных СУБД и разбавили гордое одиночество Sybase IQ, основавшей его в 90х годах. В этой статье я расскажу о причинах популярности идеи по-колоночного хранения данных, принцип действия и область использования колоночных СУБД.
Начнем с того, что популярные в наше время реляционные СУБД — Oracle, SQL Server, MySQL, DB2, Postgre и др. базируются на архитектуре, отсчитывающей свою историю еще c 1970-х годов, когда радиоприемники были транзисторными, бакенбарды длинными, брюки расклешенными, а в мире СУБД преобладали иерархические и сетевые системы управления данными. Главная задача баз данных тогда заключалась в том, чтобы поддержать начавшийся в 1960-х годах массовый переход от бумажного учета хозяйственной деятельности к компьютерному. Огромное количество информации из бумажных документов переносилось в БД учетных систем, которые должны были надежно хранить все входящие сведения и, при необходимости, быстро находить их. Такие требования обусловили архитектурные особенности реляционных СУБД, оставшиеся до настоящего времени практически неизменными: построчное хранение данных, индексирование записей и журналирование операций.
Начнем с того, что популярные в наше время реляционные СУБД — Oracle, SQL Server, MySQL, DB2, Postgre и др. базируются на архитектуре, отсчитывающей свою историю еще c 1970-х годов, когда радиоприемники были транзисторными, бакенбарды длинными, брюки расклешенными, а в мире СУБД преобладали иерархические и сетевые системы управления данными. Главная задача баз данных тогда заключалась в том, чтобы поддержать начавшийся в 1960-х годах массовый переход от бумажного учета хозяйственной деятельности к компьютерному. Огромное количество информации из бумажных документов переносилось в БД учетных систем, которые должны были надежно хранить все входящие сведения и, при необходимости, быстро находить их. Такие требования обусловили архитектурные особенности реляционных СУБД, оставшиеся до настоящего времени практически неизменными: построчное хранение данных, индексирование записей и журналирование операций.
Реляционные базы данных обречены?
14 min
Translation
Примечание переводчика: хоть статья довольно старая (опубликована 2 года назад) и носит громкое название, в ней все же дается хорошее представление о различиях реляционных БД и NoSQL БД, их преимуществах и недостатках, а также приводится краткий обзор нереляционных хранилищ.
В последнее время появилось много нереляционных баз данных. Это говорит о том, что если вам нужна практически неограниченная масштабируемость по требованию, вам нужна нереляционная БД.
Если это правда, значит ли это, что могучие реляционные БД стали уязвимы? Значит ли это, что дни реляционных БД проходят и скоро совсем пройдут? В этой статье мы рассмотрим популярное течение нереляционных баз данных применительно к различным ситуациям и посмотрим, повлияет ли это на будущее реляционных БД.
«Я не пишу юнит-тесты, потому что ...» — отговорки
3 min
Translation
Я глубоко верю в методику TDD (разработка через тестирование), так как видел на практике пользу от неё. Она выводит разработку ПО на новый уровень качества и зрелости, хотя она до сих пор не стала повсеместно распространённой. Когда наступает момент выбора между функциональностью, временем и качеством, всегда страдает именно качество. Мы обычно не хотим потратить больше времени на тестирование и не хотим идти на уступки в количестве выпускаемой функциональности. Если вы не планировали использовать методику TDD с самого начала проекта, то потом очень трудно перейти на неё.
Все мы слышали
Все мы слышали
Один компьютер на двоих (и более) или multiseat на базе Ubuntu 10.04 LTS
22 min
В данной статье рассматривается реализация multiseat на базе Ubuntu 10.04 LTS с аппаратным ускорением. Пример, рассмотренный в этой статье, уже введен в эксплуатацию и работает около полугода в обычном Минском офисе. Описываются проблемы реализации и внедрения готовой системы в работу с точки зрения обычного студента-электроприводчика, который подрабатывает на полставки системным администратором.
Вот время работы системным администратором в небольшом офисе при обновлении парка компьютеров появилась небольшая проблема. Современные компьютеры дают уровень производительности, много превосходящий необходимый для офисных компьютеров. Причем реалии рынка таковы, что различия в производительности мало сказываются на цене. И вроде бы дешевые компьютеры на базе Atom по ценовому признаку практически не отличаются от более производительных компьютеров на базе обычных процессоров Amd и Intel (материнская плата с процессором Atom стоит около 100-150 у.е. на май 2010 года, Минск, и та же цена на октябрь 2010 в том же Минске).
Та же ситуация и с жесткими дисками: для офисной работы нет необходимости в объеме диска более 40-80 Гб. Но на рынке такие жесткие диски уже практически не представлены. На момент написания статьи в продаже были жесткие диски емкостью 160 Гб (38$), 250 Гб (39$), 320 Гб (40$), 500 Гб (41$), дальше различия по ценам заметны сильнее. Цена за гигабайт жестких дисков малого объема довольно высока. Та же ситуация и со всеми остальными комплектующими.
Возникает закономерный вопрос, как рационально все это использовать? Давайте подойдем логически — чтобы удешевить систему можно либо купить комплектующие похуже (не сильно удешевляет), либо отказаться от некоторых комплектующих. По сути, в рабочем месте обязательными являются устройства ввода (клавиатура, мышь, планшет и т.д.) и устройства отображения информации (монитор, проектор и т.д.). Остальная часть системы пользователей особо не касается, и от нее можно избавляться. Безусловно, от всего избавиться не получится. Давайте заглянем под крышку системного блока. Тут мы обязательно видим материнскую плату, видеокарту (может быть уже на материнской плате), процессор (тоже может быть на материнской плате) и память. А вот остальные комплектующие уже не так важны. Оптический привод мало востребован, и поэтому его, скорее всего, не будет.
С жестким диском тоже интересная ситуация. Его может и не быть, тогда у нас будет так называемая бездисковая станция. Тут вся информация загружается по сети с сервера (реализация PXE+NFS и немного бубна). Но хочется чего-то большего.
Тогда и возникла идея подключить к одному компьютеру две клавиатуры, две мыши и два монитора и заставить их работать независимо. В зарубежных источниках такие системы называются multiseat.
Но можно на этом и не ограничиваться, а делать бездисковую multiseat-станцию. Этот вариант отлично подойдет для пары multiseat-станций с сервером. В данной статье не рассматривается.
Вступление
Вот время работы системным администратором в небольшом офисе при обновлении парка компьютеров появилась небольшая проблема. Современные компьютеры дают уровень производительности, много превосходящий необходимый для офисных компьютеров. Причем реалии рынка таковы, что различия в производительности мало сказываются на цене. И вроде бы дешевые компьютеры на базе Atom по ценовому признаку практически не отличаются от более производительных компьютеров на базе обычных процессоров Amd и Intel (материнская плата с процессором Atom стоит около 100-150 у.е. на май 2010 года, Минск, и та же цена на октябрь 2010 в том же Минске).
Та же ситуация и с жесткими дисками: для офисной работы нет необходимости в объеме диска более 40-80 Гб. Но на рынке такие жесткие диски уже практически не представлены. На момент написания статьи в продаже были жесткие диски емкостью 160 Гб (38$), 250 Гб (39$), 320 Гб (40$), 500 Гб (41$), дальше различия по ценам заметны сильнее. Цена за гигабайт жестких дисков малого объема довольно высока. Та же ситуация и со всеми остальными комплектующими.
Возникает закономерный вопрос, как рационально все это использовать? Давайте подойдем логически — чтобы удешевить систему можно либо купить комплектующие похуже (не сильно удешевляет), либо отказаться от некоторых комплектующих. По сути, в рабочем месте обязательными являются устройства ввода (клавиатура, мышь, планшет и т.д.) и устройства отображения информации (монитор, проектор и т.д.). Остальная часть системы пользователей особо не касается, и от нее можно избавляться. Безусловно, от всего избавиться не получится. Давайте заглянем под крышку системного блока. Тут мы обязательно видим материнскую плату, видеокарту (может быть уже на материнской плате), процессор (тоже может быть на материнской плате) и память. А вот остальные комплектующие уже не так важны. Оптический привод мало востребован, и поэтому его, скорее всего, не будет.
С жестким диском тоже интересная ситуация. Его может и не быть, тогда у нас будет так называемая бездисковая станция. Тут вся информация загружается по сети с сервера (реализация PXE+NFS и немного бубна). Но хочется чего-то большего.
Тогда и возникла идея подключить к одному компьютеру две клавиатуры, две мыши и два монитора и заставить их работать независимо. В зарубежных источниках такие системы называются multiseat.
Но можно на этом и не ограничиваться, а делать бездисковую multiseat-станцию. Этот вариант отлично подойдет для пары multiseat-станций с сервером. В данной статье не рассматривается.
Структуры данных: двоичная куча (binary heap)
4 min
Двоичная куча (binary heap) – просто реализуемая структура данных, позволяющая быстро (за логарифмическое время) добавлять элементы и извлекать элемент с максимальным приоритетом (например, максимальный по значению).
Для дальнейшего чтения необходимо иметь представление о деревьях, а также желательно знать об оценке сложности алгоритмов. Алгоритмы в этой статье будут сопровождаться кодом на C#.
Двоичная куча представляет собой полное бинарное дерево, для которого выполняется основное свойство кучи: приоритет каждой вершины больше приоритетов её потомков. В простейшем случае приоритет каждой вершины можно считать равным её значению. В таком случае структура называется max-heap, поскольку корень поддерева является максимумом из значений элементов поддерева. В этой статье для простоты используется именно такое представление. Напомню также, что дерево называется полным бинарным, если у каждой вершины есть не более двух потомков, а заполнение уровней вершин идет сверху вниз (в пределах одного уровня – слева направо).
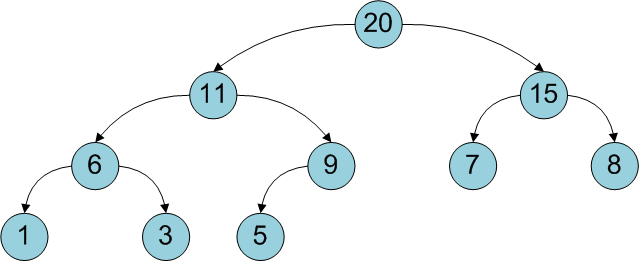
Для дальнейшего чтения необходимо иметь представление о деревьях, а также желательно знать об оценке сложности алгоритмов. Алгоритмы в этой статье будут сопровождаться кодом на C#.
Введение
Двоичная куча представляет собой полное бинарное дерево, для которого выполняется основное свойство кучи: приоритет каждой вершины больше приоритетов её потомков. В простейшем случае приоритет каждой вершины можно считать равным её значению. В таком случае структура называется max-heap, поскольку корень поддерева является максимумом из значений элементов поддерева. В этой статье для простоты используется именно такое представление. Напомню также, что дерево называется полным бинарным, если у каждой вершины есть не более двух потомков, а заполнение уровней вершин идет сверху вниз (в пределах одного уровня – слева направо).
Зачем на самом деле нужен мозг
10 min
 В продолжение предыдущего топика "Как на самом деле работает мозг". На написание данного поста меня побудила, с одной стороны, замечательная книга «Grooming, Gossip, and the Evolution of Language» Робина Данбара (Robin Dunbar), а с другой — очередная порция «полезных» и «умных» советов в GTD и других блогах.
В продолжение предыдущего топика "Как на самом деле работает мозг". На написание данного поста меня побудила, с одной стороны, замечательная книга «Grooming, Gossip, and the Evolution of Language» Робина Данбара (Robin Dunbar), а с другой — очередная порция «полезных» и «умных» советов в GTD и других блогах.Для затравки — небольшая логическая задачка. Дан набор карточек; на каждой из них на одной стороне написана буква, на другой — цифра.
На столе лежат четыре карточки: «А», «Д», «5» и «6». Вам говорят: если на карточке (из числа лежащих на столе) на одной стороне гласная, то на обороте — чётная цифра. Какие из карточек достаточно перевернуть, чтобы однозначно подтвердить или опровергнуть это утверждение?
Подумайте немного, запишите ответ на бумажке и добро пожаловать под кат.
Метод имитации отжига
7 min
Дорогие друзья, доброго времени суток!
Уже не один раз здесь обсуждалась такая разновидность оптимизационных алгоритмов, как генетические алгоритмы. Однако, существуют и другие способы поиска оптимального решения в задачах с многими степенями свободы. Один из них (и, надо сказать, один из наиболее эффективных) — метод имитации отжига, о котором здесь ещё не рассказывали. Я решил устранить эту несправедливость и как можно более простыми словами познакомить вас с этим замечательным алгоритмом, а заодно привести пример его использования для решения несложной задачки.
Я понимаю, почему генетические алгоритмы пользуются такой большой популярностью: они очень образны и, следовательно, доступны для понимания. В самом деле, несложно и крайне интересно представить решение некой задачи, как реальный биологический процесс развития популяции живых существ с определёнными свойствами. Между тем, алгоритм отжига также имеет свой прототип в реальном мире (это понятно и из самого названия). Правда, пришёл он не из биологии, а из физики. Процесс, имитируемый данным алгоритмом, похож на образование веществом кристаллической структуры с минимальной энергией во время охлаждения и затвердевания, когда при высоких температурах частицы хаотично движутся, постепенно замедляясь и застывая в местах с наименьшей энергией. Только в случае математической задачи роль частиц вещества выполняют параметры, а роль энергии — функция, характеризующая оптимальность набора этих параметров.
Уже не один раз здесь обсуждалась такая разновидность оптимизационных алгоритмов, как генетические алгоритмы. Однако, существуют и другие способы поиска оптимального решения в задачах с многими степенями свободы. Один из них (и, надо сказать, один из наиболее эффективных) — метод имитации отжига, о котором здесь ещё не рассказывали. Я решил устранить эту несправедливость и как можно более простыми словами познакомить вас с этим замечательным алгоритмом, а заодно привести пример его использования для решения несложной задачки.
Я понимаю, почему генетические алгоритмы пользуются такой большой популярностью: они очень образны и, следовательно, доступны для понимания. В самом деле, несложно и крайне интересно представить решение некой задачи, как реальный биологический процесс развития популяции живых существ с определёнными свойствами. Между тем, алгоритм отжига также имеет свой прототип в реальном мире (это понятно и из самого названия). Правда, пришёл он не из биологии, а из физики. Процесс, имитируемый данным алгоритмом, похож на образование веществом кристаллической структуры с минимальной энергией во время охлаждения и затвердевания, когда при высоких температурах частицы хаотично движутся, постепенно замедляясь и застывая в местах с наименьшей энергией. Только в случае математической задачи роль частиц вещества выполняют параметры, а роль энергии — функция, характеризующая оптимальность набора этих параметров.
Моноиды и их приложения: моноидальные вычисления в деревьях
20 min
Приветствую, Хабрахабр. Сегодня я хочу, в своём обычном стиле, устроить сообществу небольшой ликбез по структурам данных. Только на этот раз он будет гораздо более всеобъемлющ, а его применения и практичность — простираться далеко в самые разнообразные области программирования. Самые красивые применения, я, конечно же, покажу и опишу непосредственно в статье.
Нам понадобится капелька абстрактного мышления, знание какого-нибудь сбалансированного дерева поиска (например, описанного мною ранее декартова дерева), умение читать простой код на C#, и желание применить полученные знания.
Итак, на повестке сегодняшнего дня — моноиды и их основное применение для кеширования вычислений в деревьях.
Представьте себе множество чего угодно, множество, состоящее из объектов, которыми мы собираемся манипулировать. Назовём его M. На этом множестве мы вводим бинарную операцию, то есть функцию, которая паре элементов множества ставит в соответствие новый элемент. Здесь и далее эту абстрактную операцию мы будем обозначать "⊗", и записывать выражения в инфиксной форме: если a и b — элементы множества, то c = a ⊗ b — тоже какой-то элемент этого множества.
Например, рассмотрим все строки, существующие на свете. И рассмотрим операцию конкатенации строк, традиционно обозначаемую в математике "◦", а в большинстве языков программирования "+":
Или другой пример — функция fst, известная в функциональных языках при манипуляции с кортежами. Из двух своих аргументов она возвращает в качестве результата первый по порядку. Так,fst(5, 2) = 5 ; fst( . Безразлично, на каком множестве рассматривать эту бинарную операцию, так что в вашей воле выбрать любое.
Далее мы на нашу операцию "⊗" накладываем ограничение ассоциативности. Это значит, что от неё требуется следующее: если с помощью "⊗" комбинируют последовательность объектов, то результат должен оставаться одинаковым вне зависимости от порядка применения "⊗". Более строго, для любых трёх объектов a, b и c должно иметь место:
(a ⊗ b) ⊗ c = a ⊗ (b ⊗ c)
Легко увидеть, что конкатенация строк ассоциативна: не важно, какое склеивание в последовательности строк выполнять раньше, а какое позже, в итоге все равно получится общая склейка всех строк в последовательности. То же касается и функции fst, ибо:
fst(fst(a, b), c) = a
fst(a, fst(b, c)) = a
Цепочка применений fst к последовательности в любом порядке всё равно выдаст её головной элемент.
И последнее, что мы потребуем: в множестве M по отношению к операции должен существовать нейтральный элемент, или единица операции. Это такой объект, который можно комбинировать с любым элементом множества, и это не изменит последний. Формально выражаясь, если e — нейтральный элемент, то для любого a из множества имеет место:
a ⊗ e = e ⊗ a = a
В примере со строками нейтральным элементом выступает пустая строкаfst(e, a) = e всегда, и если a ≠ e , то свойство нейтральности мы теряем. Можно, конечно, рассмотреть fst на множестве из одного элемента, но кому такая скука нужна? :)
Каждую такую тройку <M, ⊗, e> мы и будем торжественно называть моноидом. Зафиксируем это знание в коде:
Больше примеров моноидов, а также где мы их, собственно, применять будем, лежит под катом.
Нам понадобится капелька абстрактного мышления, знание какого-нибудь сбалансированного дерева поиска (например, описанного мною ранее декартова дерева), умение читать простой код на C#, и желание применить полученные знания.
Итак, на повестке сегодняшнего дня — моноиды и их основное применение для кеширования вычислений в деревьях.
Моноид как концепция
Представьте себе множество чего угодно, множество, состоящее из объектов, которыми мы собираемся манипулировать. Назовём его M. На этом множестве мы вводим бинарную операцию, то есть функцию, которая паре элементов множества ставит в соответствие новый элемент. Здесь и далее эту абстрактную операцию мы будем обозначать "⊗", и записывать выражения в инфиксной форме: если a и b — элементы множества, то c = a ⊗ b — тоже какой-то элемент этого множества.
Например, рассмотрим все строки, существующие на свете. И рассмотрим операцию конкатенации строк, традиционно обозначаемую в математике "◦", а в большинстве языков программирования "+":
"John" ◦ "Doe" = "JohnDoe"Или другой пример — функция fst, известная в функциональных языках при манипуляции с кортежами. Из двух своих аргументов она возвращает в качестве результата первый по порядку. Так,
"foo", "bar") = "foo"Далее мы на нашу операцию "⊗" накладываем ограничение ассоциативности. Это значит, что от неё требуется следующее: если с помощью "⊗" комбинируют последовательность объектов, то результат должен оставаться одинаковым вне зависимости от порядка применения "⊗". Более строго, для любых трёх объектов a, b и c должно иметь место:
Легко увидеть, что конкатенация строк ассоциативна: не важно, какое склеивание в последовательности строк выполнять раньше, а какое позже, в итоге все равно получится общая склейка всех строк в последовательности. То же касается и функции fst, ибо:
fst(fst(a, b), c) = a
fst(a, fst(b, c)) = a
Цепочка применений fst к последовательности в любом порядке всё равно выдаст её головной элемент.
И последнее, что мы потребуем: в множестве M по отношению к операции должен существовать нейтральный элемент, или единица операции. Это такой объект, который можно комбинировать с любым элементом множества, и это не изменит последний. Формально выражаясь, если e — нейтральный элемент, то для любого a из множества имеет место:
a ⊗ e = e ⊗ a = a
В примере со строками нейтральным элементом выступает пустая строка
"": с какой стороны к какой строке её ни приклеивай, строка не поменяется. А вот fst в этом отношении нам устроит подлянку: нейтральный элемент для неё придумать невозможно. Ведь Каждую такую тройку <M, ⊗, e> мы и будем торжественно называть моноидом. Зафиксируем это знание в коде:
public interface IMonoid<T> {
T Zero { get; }
T Append(T a, T b);
}
Больше примеров моноидов, а также где мы их, собственно, применять будем, лежит под катом.
Цифровые подписи в исполняемых файлах и обход этой защиты во вредоносных программах
8 min

Хабрапривет!
Ну вроде как удалось решить вопросы с кармой, но они ником образом не касаются сегодняшней темы, а лишь объясняют некоторое опоздание её выхода на свет (исходные планы были на ноябрь прошлого года).
Сегодня я предлагаю Вашему вниманию небольшой обзор по системе электронных подписей исполняемых файлов и способам обхода и фальсификации этой системы. Также будет рассмотрен в деталях один из весьма действенных способов обхода. Несмотря на то, что описываемой инфе уже несколько месяцев, знают о ней не все. Производители описываемых ниже продуктов были уведомлены об описываемом материале, так что решение этой проблемы, если они вообще считают это проблемой, на их ответственности. Потому как времени было предостаточно.
Закономерные случайности
3 min
Увлекаясь компьютерной графикой, заметил, что комбинация правил и случайности может давать неожиданно красивые результаты.
С одной стороны, глядя на такие изображения очевидно их компьютерное происхождение, с другой — фактор случайности делает их неповторимыми и непредсказуемыми.
Еще подметил, что многократное повторение даже неказистых форм создает гармоничные рисунки, если видеть их целиком.



С одной стороны, глядя на такие изображения очевидно их компьютерное происхождение, с другой — фактор случайности делает их неповторимыми и непредсказуемыми.
Еще подметил, что многократное повторение даже неказистых форм создает гармоничные рисунки, если видеть их целиком.
Unity — бесплатный кроссплатформенный 3D движок (и браузерный тоже)
7 min
Преамбула
Итак, сегодня я хотел бы рассказать вам о Unity (тем, кто ещё не знаком с ним, по крайней мере). Безусловно, на Хабре есть люди, которые знают, что это такое, но поиск выдаёт катастрофически малое количество топиков с упоминанием сабжа — два из них просто сообщают о новых версиях, один кратко презентует и ещё один посвящен всё-таки его использованию. «Непростительно, надо это исправить!», — подумал я, и решил написать краткий презентейшн с целью популяризации технологии. Если вы уже в теме — дальше можете не читать.
Честно говоря, когда я читал на википедии о бесплатном (по крайней мере, с вполне нормальной по функционалу фришной лицензией) 3d движке с нормальным IDE, встроенной нормальной физикой, аудио-движком и прямой реализацией сетевого мультиплеера на котором можно делать приложения для всего, кроме, пожалуй, nix'ов (поддерживаются и нормально работают Windows, MacOS, Wii, iPhone, iPod, iPad, Android, PS3, XBox 360), я уже чуял подвох.
Как и зачем я стал работать за компьютером стоя
4 min
Translation

Ежедневно я работаю за компьютером 9–10 часов. Вплоть до прошлой недели я проводил все это время, сидя на своей вечно расширяющейся заднице.
В понедельник я отрегулировал свой стол для стоячего положения (фотография выше) и провел неделю, работая исключительно стоя. К сидению я теперь никогда не вернусь.