
В данной статье я рассмотрю популярную сетевую утилиту netcat и полезные трюки при работе с ней.

User
В данной статье я рассмотрю популярную сетевую утилиту netcat и полезные трюки при работе с ней.

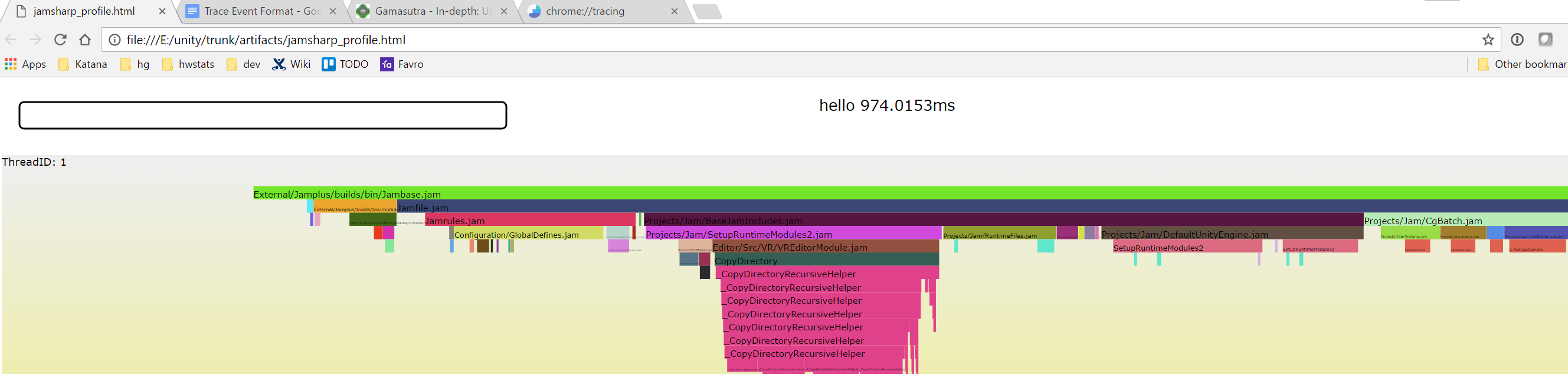

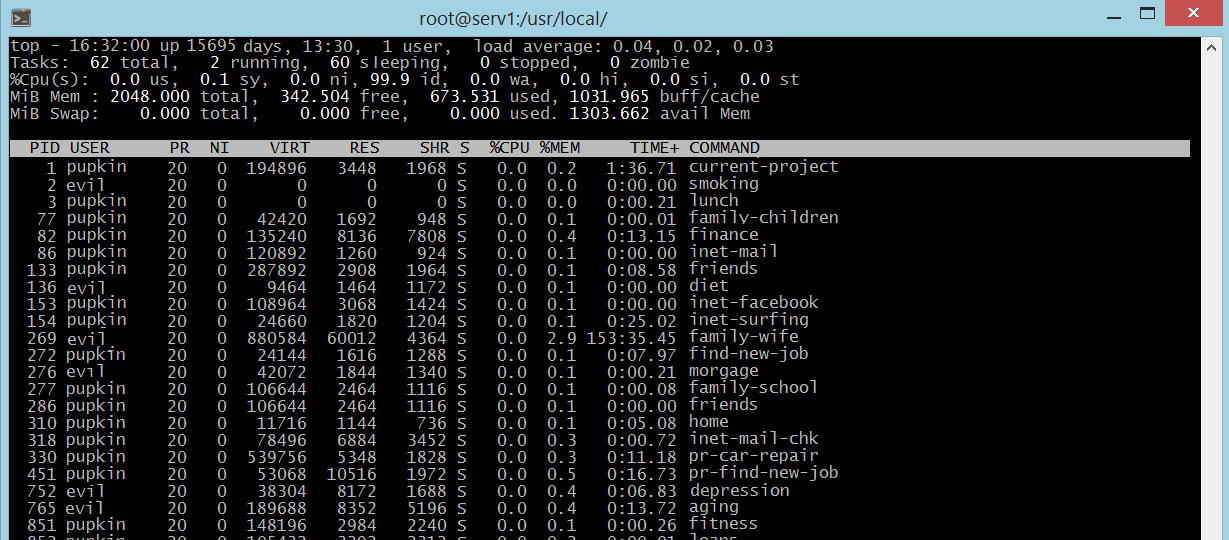
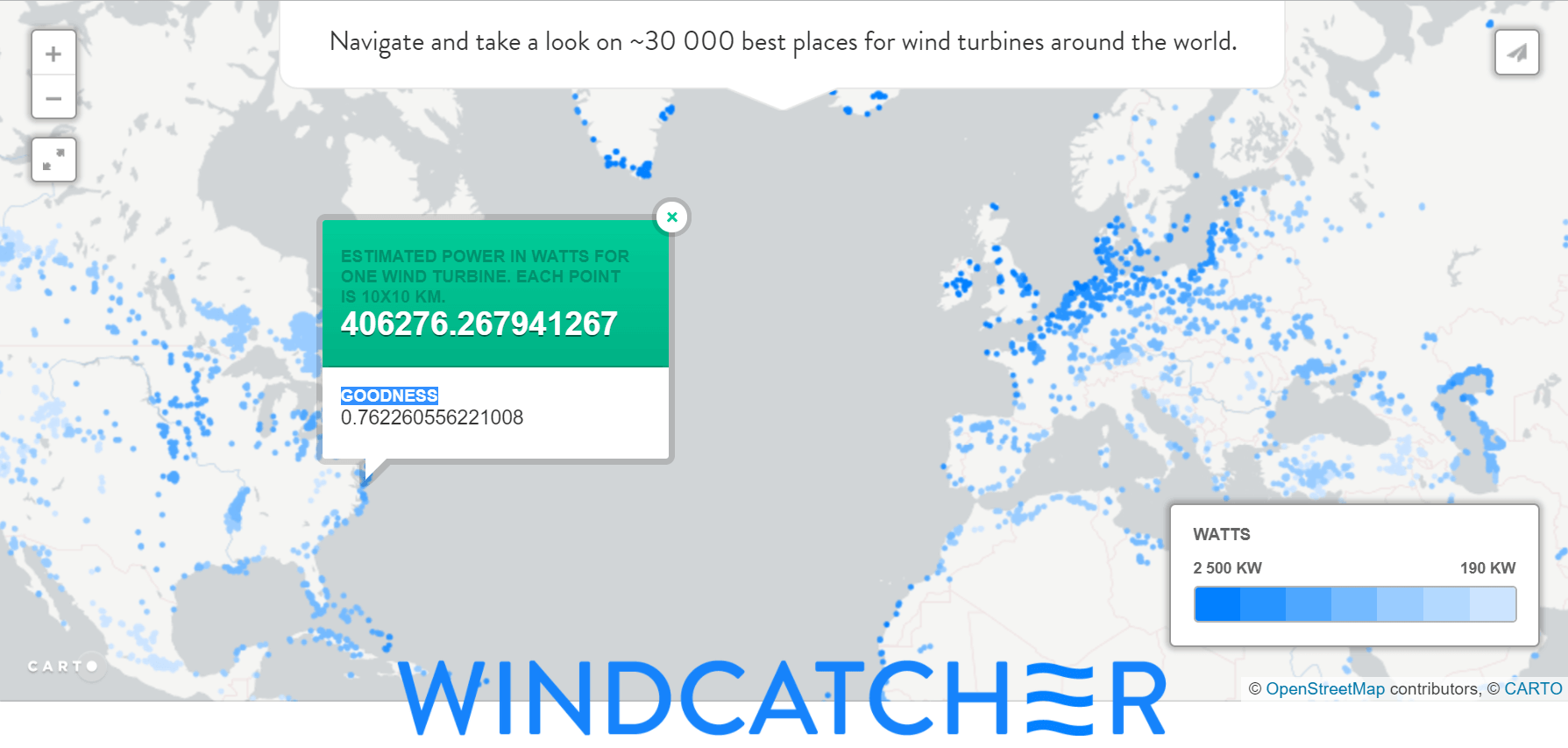
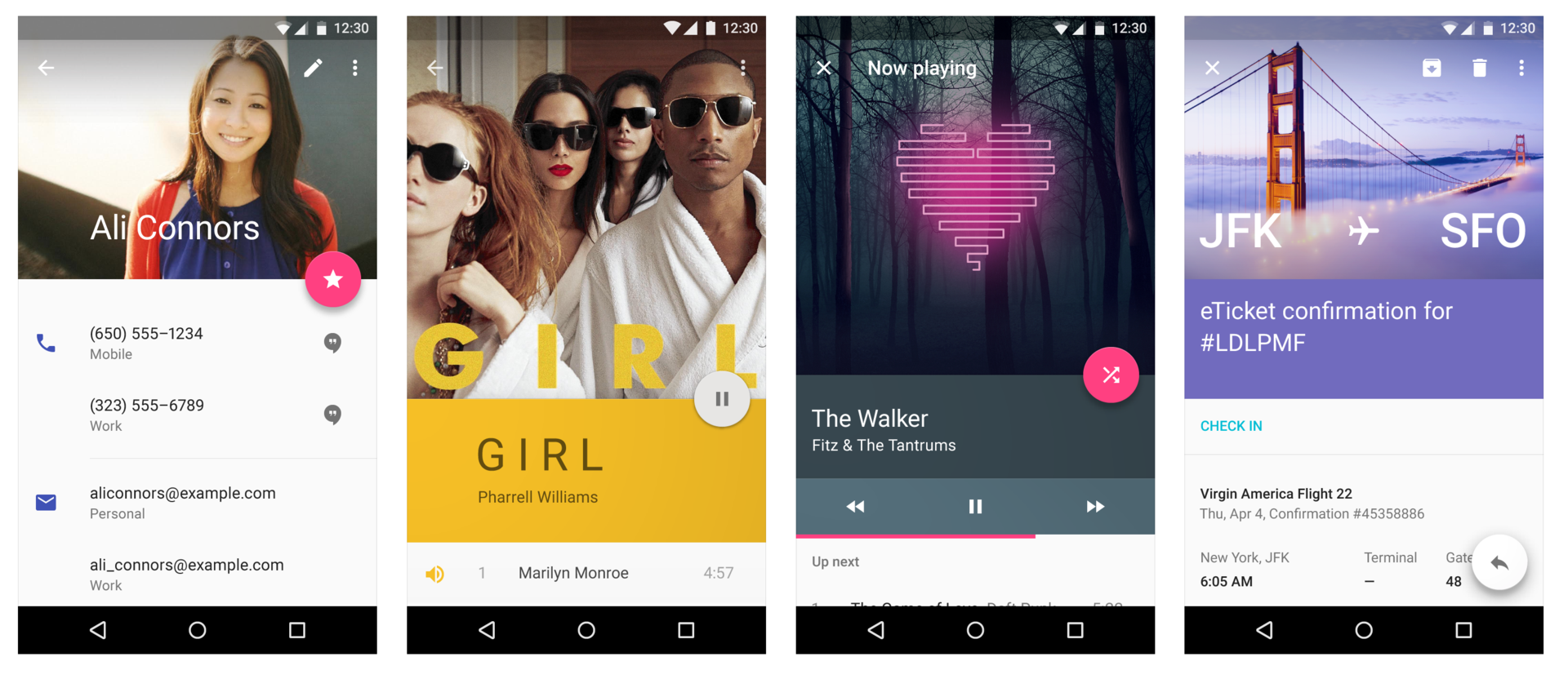
В этой серии статей я расскажу о внутреннем устройстве Android — о процессе загрузки, о содержимом файловой системы, о Binder и Android Runtime, о том, из чего состоят, как устанавливаются, запускаются, работают и взаимодействуют между собой приложения, об Android Framework, и о том, как в Android обеспечивается безопасность.

Метод Уэлфорда — простой и эффективный способ для вычисления средних, дисперсий, ковариаций и других статистик. Этот метод обладает целым рядом прекрасных свойств:
Оригинальная статья Уэлфорда была опубликована в 1962 году. Тем не менее, нельзя сказать, что алгоритм сколь-нибудь широко известен в настоящее время. А уж найти математическое доказательство его корректности или экспериментальные сравнения с другими методами и вовсе нетривиально.
Настоящая статья пытается заполнить эти пробелы.

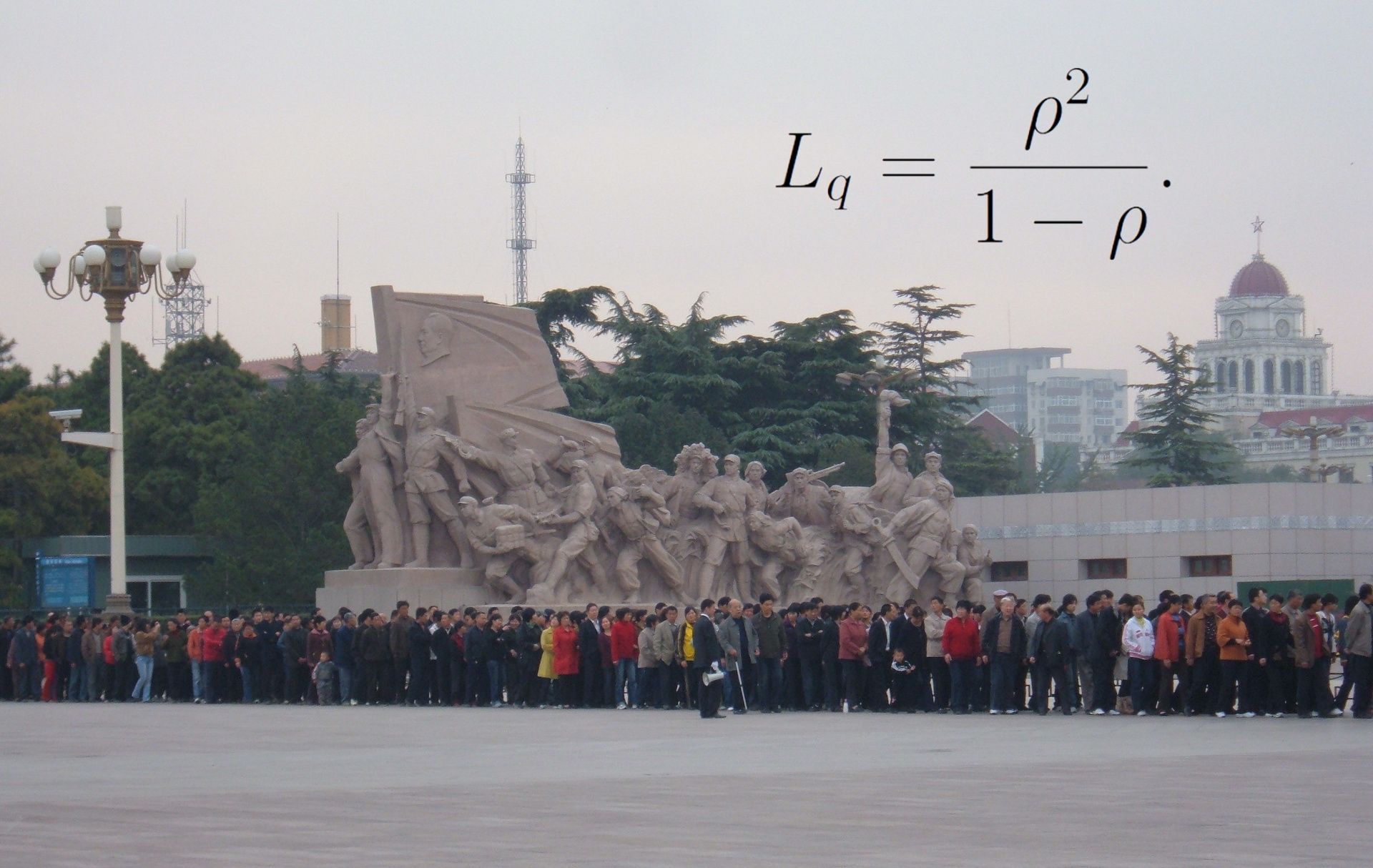
Вдохновившись некоторое время назад статьей «Умные часы своими руками за 1500р.», я тоже решил попробовать сделать подобный девайс.
Эта статья не позиционируется как руководство к действию или инструкция, скорее как указание на ключевые моменты, с которыми мне пришлось столкнуться. Быть может, кому-то она послужит источником вдохновения и полезной информации.
Подбор компонентов, разводка платы, пайка в суровых условиях, 3D-печатный корпус и JavaScript на часах — под катом. Welcome!

Обычно модели машинного обучения строят в jupyter-ноутбуках, код которых выглядит, мягко говоря, не очень — длинные простыни из лапши выражений и вызовов "на коленке" написанных функций. Понятно, что такой код почти невозможно поддерживать, поэтому каждый проект переписывается чуть ли не с нуля. А о внедрении этого кода в production даже подумать страшно.
Поэтому сегодня представляем на ваш строгий суд превью python'овской библиотеки по работе с датасетами и data science моделями. С ее помощью ваш код на python'е может выглядеть так:
my_dataset.
load('/some/path').
normalize().
resize(shape=(256, 256, 256)).
random_rotate(angle=(-30, 30)).
random_crop(shape=(64, 64, 64))
for i in range(MAX_ITER):
batch = my_dataset.next_batch(BATCH_SIZE, shuffle=True)
# обучаем модель, подавая ей батчи с данными В этой статье вы узнаете об основных классах и методах, которые помогут сделать ваш код простым, понятным и удобным.

Недавно я опубликовал свою первую статью на Хабре. И первый блин прилетел мне прямо в голову. 12к просмотров и плюс 4 звезды на гитхабе… Ладно, сам виноват, не надо было заниматься ерундой на уроках русского языка и литературы. Если я правильно понял, то проблема заключалась в том, что я сразу перешел к сути. Вывалил все в лоб. Не познакомился с родителями, так сказать. А что за Jeta такая, как она работает, что происходит за сценой? Магия какая я то… Никому ведь не нужна магия в проектах, так?
"От куда у тебя уверенность, что твоя библиотека вообще кому-то нужна?" спросит среднестатистический хаброчанин. Оттуда, что каждый день, вешая очередную аннотацию или просто смотря на код, я думаю "Боже, это прекрасно!". Кто от такого откажется?
Ладно, давайте сначала и по порядку.

Части 1 и 2: ссылка
В первой части мы поговорили о разных стратегиях обработки ошибок и о том, когда их рекомендуется применять. В частности, я рассказал, что предусловия функций должны проверяться с помощью отладочных утверждений (debug assertions), т. е. только в режиме отладки.
Для проверки условия библиотека С предоставляет макрос assert(), но только если не определён NDEBUG. Однако, как и в случае со многими другими вещами в С, это простое, но иногда неэффективное решение. Главная проблема, с которой я столкнулся, — глобальность решения: у вас есть утверждения либо везде, либо нигде. Плохо это потому, что вы не сможете отключить утверждения в библиотеке, оставив их только в собственном коде. Поэтому многие авторы библиотек самостоятельно пишут макросы утверждений, раз за разом.
На прошлой внутренней конференции разработчиков Контура я выступал с докладом. В моей презентации был слайд, на котором были перечислены известные российские ИТ-компании, разделенные на два столбца. Между компаниями в правом и левом столбцах было одно весомое различие.
Я попросил зал ответить на вопрос, с какими компаниями вы себя больше ассоциируете? В каких, по вашему мнению, работают крутые инженеры, там интересно развиваться и туда интересно пойти работать, сотрудники этих компаний могут чему-то научить других, поделиться опытом?
На конференции коллеги почти единогласно проголосовали за компании из правого столбца.
Отличие их состояло в том, что они активно распространяют свои технологии и знания — делятся с профессиональным сообществом открытым кодом и понятными мануалами, выступают на конференциях. Они осознанно вкладываются в развитие своих opensource-проектов. Технологии и описания многих из них лежат в открытом доступе на специально созданных сайтах tech.yandex.ru, opensource.mail.ru, techno.2gis.ru/opensource, и известны многим разработчикам за пределами компаний.
Если вы вдруг решили заняться благотворительностью (почти) и сделать что-то подобное в своей компании, надеюсь, мой текст поможет ответить на вопросы: нужно ли это вам, сколько ресурсов потребуется и что в итоге получится. У нас вышел такой сайт: tech.skbkontur.ru.

