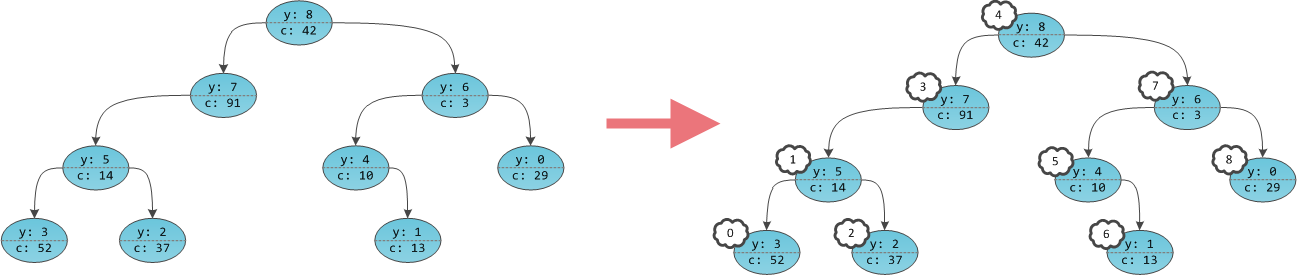
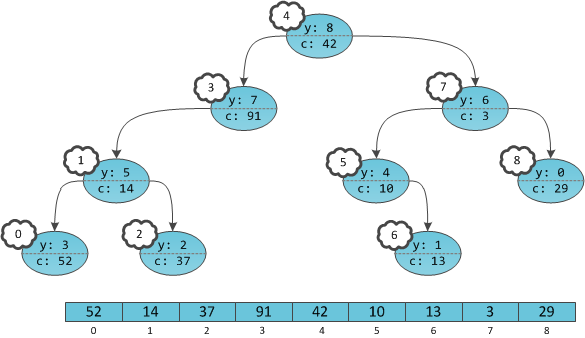
Хоть от многопоточности и библиотек, которые её поддерживают, отказываются немногие Java-программисты, но тех, кто нашёл время изучить вопрос в глубину ещё меньше. Вместо этого мы узнаём о потоках только столько, сколько нам требуется для конкретной задачи, добавляя новые приёмы в свой инструментарий лишь тогда, когда это необходимо. Так можно создавать и запускать достойные приложения, но можно делать и лучше. Понимание особенностей компилятора и виртуальной машины Java поможет вам писать более эффективный, производительный код.
В этом выпуске серии «5 вещей …», я представлю некоторые из тонких аспектов многопоточного программирования, в том числе synchronized-методы, volatile переменные и атомарные классы. Речь пойдет в особенности о том, как некоторые из этих конструкций взаимодействуют с JVM и Java-компилятором, и как различные взаимодействия могут повлиять на производительность приложений.
В этом выпуске серии «5 вещей …», я представлю некоторые из тонких аспектов многопоточного программирования, в том числе synchronized-методы, volatile переменные и атомарные классы. Речь пойдет в особенности о том, как некоторые из этих конструкций взаимодействуют с JVM и Java-компилятором, и как различные взаимодействия могут повлиять на производительность приложений.


 abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.
abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.