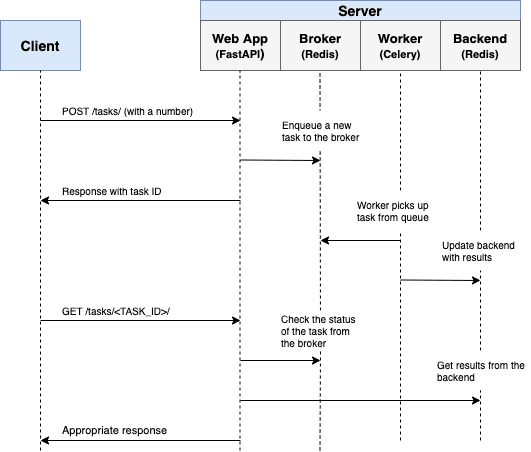
Сегодня самый популярный поисковый движок — это Reddit. Единственные, кто этого не знает — команда Reddit, которая не может отвлечься на создание приличного интерфейса поиска. Поэтому вместо этого нам приходится прибегать к Google и добавлять в строку запроса слово «reddit».
Пол Грэм считает, что такая ситуация означает, что Reddit как сайт социальной сети «всё ещё не достиг своего пика». На самом деле это означает, что количество людей, использующих Reddit как поисковый движок, растёт.
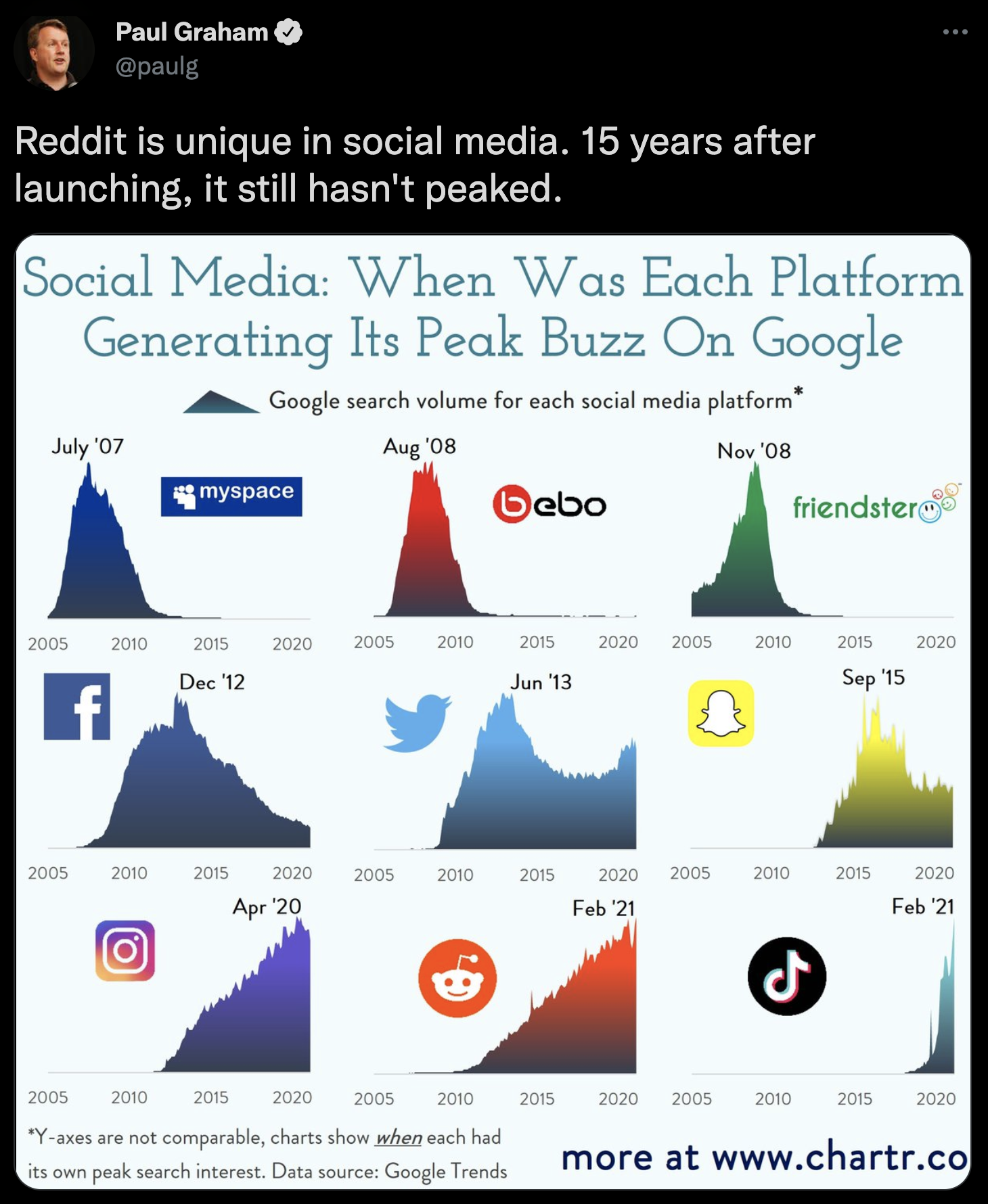
Пол Грэм: «Reddit — уникальная соцсеть. Спустя 15 лет после запуска она всё ещё не достигла своего пика».
Почему люди ищут именно на Reddit? Короткий ответ: очевидно, что поисковые результаты Google умирают. Длинный ответ: бОльшая часть веба стала слишком недостоверной, чтобы ей доверять.
Пол Грэм считает, что такая ситуация означает, что Reddit как сайт социальной сети «всё ещё не достиг своего пика». На самом деле это означает, что количество людей, использующих Reddit как поисковый движок, растёт.
Пол Грэм: «Reddit — уникальная соцсеть. Спустя 15 лет после запуска она всё ещё не достигла своего пика».
Почему люди ищут именно на Reddit? Короткий ответ: очевидно, что поисковые результаты Google умирают. Длинный ответ: бОльшая часть веба стала слишком недостоверной, чтобы ей доверять.